
(Florentin Catargiu/Shutterstock)
As organizações que investem em knowledge lakehouses em 2025 podem querer conferir uma nova oferta revelada pela Onehouse esta semana. A empresa fundada pelo criador do formato de tabela Apache Hudi lançou o Onehouse Compute Runtime (OCR), que permite aos clientes gerenciar e otimizar cargas de trabalho de knowledge lakehouse em várias plataformas de nuvem, mecanismos de consulta e formatos de tabela abertos.
Estamos no meio de um increase de construção de knowledge lakehouses neste momento, em grande parte devido à indústria coalescendo em torno do Iceberg Apache formato de tabela em meados de 2024, o que reduziu as probabilities de o cliente escolher o formato “errado”, prejudicando assim seus dados. A ascensão do Iceberg parece colocar formatos de mesa concorrentes, incluindo Apache Hudi e Blocos de dados Delta Lake, em segundo plano. Mas o pessoal da Hudi-backer Uma casa veja oportunidades abundantes e não aceite as mudanças de braços cruzados.
Embora a comparação Hudi-Iceberg não seja exatamente igual (leia esta história para saber como o Hudi foi originalmente projetado para resolver o problema de dados rápidos no cluster Hadoop do Uber), o Onehouse está, no entanto, se adaptando à realidade de que o Iceberg está posicionado para ser o formato de tabela dominante no futuro. Uma maneira de fazer isso é lançando o OCR.
OCR oferece aos clientes a capacidade de gerenciar seus ambientes lakehouse em várias plataformas de nuvem (Databricks, Floco de neve, AWS, Google Nuvem) que usam vários mecanismos de consulta (Spark, Redshift, BigQuery, Snowflake) em dados armazenados em vários formatos de tabela (Iceberg, Delta Lake e Hudi). OCR não se preocupa com a execução das cargas de trabalho SQL (ou outras cargas de computação). Em vez disso, seu foco é automatizar alguns dos trabalhos de manutenção menos glamorosos, mas necessários, que as casas do lago exigem.
Os funcionários da Onehouse Kyle Weller e Rajesh Mahindra explicam a situação emergente em uma postagem de weblog essa semana:
“O suporte básico de leitura/gravação é um começo louvável para estabelecer a independência, mas surgiram novos pontos de atrito que desafiam o armazenamento a ser interoperável e common mais uma vez: catálogos de dados, manutenção de tabelas e otimizações de carga de trabalho. Quase todos os fornecedores que suportam OTF (formato de tabela aberta) agora também oferecem seu próprio catálogo e manutenção, o que muitas vezes restringe quais ferramentas podem ler/gravar nas tabelas. Para garantir que o controle dos dados permaneça firmemente nas mãos dos usuários, a indústria precisa não apenas de armazenamento descentralizado, mas também de uma plataforma de computação descentralizada cuidadosamente elaborada que possa realizar manutenção de tabelas e otimizar cargas de trabalho típicas universalmente entre esses diferentes armazéns e fornecedores de dados em nuvem.”
O OCR da Onehouse pretende ser essa plataforma de computação descentralizada. A oferta, lançada pela Onehouse na quinta-feira, 16 de janeiro, aumenta automaticamente os recursos de computação necessários em várias plataformas de nuvem usando técnicas de computação sem servidor nos próprios ambientes de nuvem privada digital (VPC) dos clientes.
O gerenciador de computação sem servidor baseado em Spark do OCR permite o dimensionamento elástico das cargas de trabalho de manutenção do lakehouse, como ingestão de dados, otimização de tabelas e operações ETL. Isso resulta em um ganho de desempenho de 2x a 30x com uma economia de custos de 20% a 80%, afirma a empresa. OCR suporta vários formatos utilizando Apache XTable (incubação), a oferta de código aberto que oferece interoperabilidade de leitura e gravação entre os formatos de tabela Hudi, Delta e Iceberg. Onehouse doou XTable para Apache.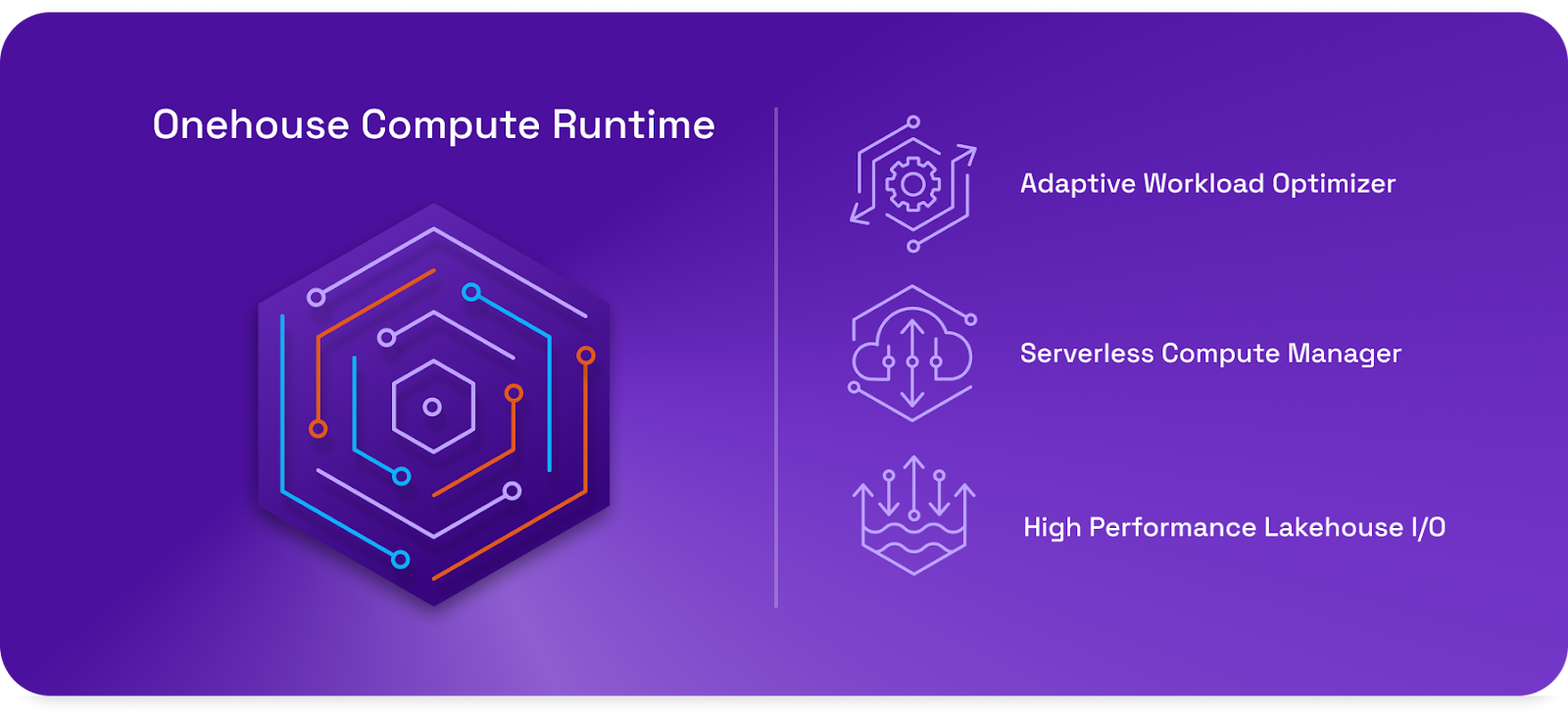
OCR utiliza fusão colunar vetorizada para gravações rápidas, execução em pipeline paralelo para maximizar a eficiência da CPU e acesso otimizado ao armazenamento para reduzir solicitações de rede em comparação com leitores Parquet de código aberto padrão, afirma a empresa.
O objetivo do OCR é fornecer aos clientes todas as ferramentas necessárias para aproveitar o crescimento das lakehouses e a abertura dos formatos de mesa, de acordo com Vinoth Chandar, criador do Hudi e fundador e CEO da Onehouse.
“Embora os formatos de tabelas abertas tenham surgido como meios de abrir dados em vários mecanismos, há uma grande necessidade de uma plataforma de computação de alto desempenho que possa transformar e otimizar dados nesses mecanismos”, diz Chandar, um Pessoa do BigDATAwire 2024 para assistir, em um comunicado de imprensa. “Com o OCR, fornecemos toda a infraestrutura de computação e software program necessários para executar cargas de trabalho de knowledge lakehouse com eficiência. Os recursos de OCR baseiam-se em anos de experiência alimentando os maiores knowledge lakes do mundo usando Apache Hudi, amplamente reconhecido por seu alto desempenho em todo o setor. O tempo de execução otimiza centralmente todas as operações típicas de knowledge lakehouse em todos os mecanismos, reduzindo custos de computação redundantes e pontos de bloqueio.”
Uma das primeiras a adotar o OCR é a empresa de advertising digital Condutor. “Nosso knowledge lakehouse Onehouse nos permitiu atender às demandas de rápido crescimento e, ao mesmo tempo, simplificar drasticamente nossa arquitetura de dados”, disse Emil Emilov, engenheiro de software program principal da Conductor. “Com escalonamento automatizado e recursos que se adaptam às nossas cargas de trabalho, a Onehouse nos ajuda a dedicar nossas equipes à construção de nossos principais diferenciais de plataforma, em vez de manter a pilha de dados continuamente otimizada.”
Onehouse realizará um webinar na quinta-feira, 23 de janeiro, às 10h, horário do Pacífico, para fornecer mais detalhes sobre OCR. Você pode se inscrever no webinar aqui. Você também pode ler o weblog da Onehouse sobre OCR aqui.
Itens relacionados:
Por que os Knowledge Lakehouses estão preparados para um grande crescimento em 2025