Você já se pegou olhando a lista de ingredientes de um produto, pesquisando no Google nomes químicos desconhecidos para descobrir o que eles significam? É uma luta comum – decifrar informações complexas sobre produtos no native pode ser cansativo e demorado. Os métodos tradicionais, como a pesquisa de cada ingrediente individualmente, muitas vezes levam a resultados fragmentados e confusos. Mas e se houvesse uma maneira mais inteligente e rápida de analisar os ingredientes dos produtos e obter insights claros e práticos instantaneamente? Neste artigo, orientaremos você na construção de um Analisador de Ingredientes de Produto usando Gêmeos 2.0Phidata e Tavily Internet Search. Vamos mergulhar e entender essas listas de ingredientes de uma vez por todas!
Objetivos de aprendizagem
- Projete uma arquitetura de agente de IA multimodal usando Phidata e Gemini 2.0 para tarefas de linguagem de visão.
- Integre o Tavily Internet Search aos fluxos de trabalho dos agentes para melhor contexto e recuperação de informações.
- Crie um agente analisador de ingredientes do produto que mix processamento de imagens e pesquisa na net para obter informações detalhadas sobre o produto.
- Saiba como os prompts e instruções do sistema orientam o comportamento do agente em tarefas multimodais.
- Desenvolva uma UI Streamlit para análise de imagens em tempo actual, detalhes nutricionais e sugestões baseadas em saúde.
Este artigo foi publicado como parte do Blogatona de Ciência de Dados.
O que são sistemas multimodais?
Os sistemas multimodais processam e compreendem vários tipos de dados de entrada – como texto, imagens, áudio e vídeo – simultaneamente. Modelos de linguagem de visão, como Gemini 2.0 Flash, GPT-4o, Claude Sonnet 3.5 e Pixtral-12B, são excelentes na compreensão das relações entre essas modalidades, extraindo insights significativos de entradas complexas.
Neste contexto, focamos em modelos de linguagem visible que analisam imagens e geram insights textuais. Esses sistemas combinam visão computacional e processamento de linguagem pure para interpretar informações visuais com base nas solicitações do usuário.
Casos de uso multimodais do mundo actual
Os sistemas multimodais estão transformando as indústrias:
- Financiar: os usuários podem fazer capturas de tela de termos desconhecidos em formulários on-line e obter explicações instantâneas.
- Comércio eletrônico: os compradores podem fotografar os rótulos dos produtos para receber análises detalhadas dos ingredientes e informações sobre saúde.
- Educação: os alunos podem capturar diagramas de livros didáticos e receber explicações simplificadas.
- Assistência médica: os pacientes podem digitalizar relatórios médicos ou rótulos de receitas para obter explicações simplificadas de termos e instruções de dosagem.
Por que Agente Multimodal?
A mudança da IA monomodo para agentes multimodais marca um grande salto na forma como interagimos com os sistemas de IA. Aqui está o que torna os agentes multimodais tão eficazes:
- Eles processam informações visuais e textuais simultaneamente, fornecendo respostas mais precisas e conscientes do contexto.
- Eles simplificam informações complexas, tornando-as acessíveis a usuários que possam ter dificuldades com termos técnicos ou conteúdo detalhado.
- Em vez de procurar manualmente componentes individuais, os usuários podem fazer add de uma imagem e receber uma análise abrangente em uma única etapa.
- Ao combinar ferramentas como pesquisa na net e análise de imagens, eles fornecem insights mais completos e confiáveis.
Agente analisador de ingredientes de produtos de construção

Vamos detalhar a implementação de um Agente de Análise de Ingredientes do Produto:
Etapa 1: configurar dependências
- Gemini 2.0 Flash: Lida com processamento multimodal com recursos de visão aprimorados
- Tavily Search: fornece integração de pesquisa na net para contexto adicional
- Phidata: orquestra o sistema do agente e gerencia fluxos de trabalho
- Streamlit: Para desenvolver o protótipo em aplicativos baseados na Internet.
!pip set up phidata google-generativeai tavily-python streamlit pillowEtapa 2: instalação e configuração da API
Nesta etapa, configuraremos as variáveis de ambiente e reuniremos as credenciais de API necessárias para executar este caso de uso.
from phi.agent import Agent
from phi.mannequin.google import Gemini # wants a api key
from phi.instruments.tavily import TavilyTools # additionally wants a api key
import os
TAVILY_API_KEY = ""
GOOGLE_API_KEY = ""
os.environ('TAVILY_API_KEY') = TAVILY_API_KEY
os.environ('GOOGLE_API_KEY') = GOOGLE_API_KEY Etapa 3: immediate do sistema e instruções
Para obter melhores respostas dos modelos de linguagem, você precisa escrever prompts melhores. Isso envolve definir claramente a função e fornecer instruções detalhadas no immediate do sistema para o LLM.
Vamos definir o papel e as responsabilidades de um Agente com experiência em análise de ingredientes e nutrição. As instruções devem orientar o Agente a analisar sistematicamente os produtos alimentares, avaliar os ingredientes, considerar as restrições alimentares e avaliar as implicações para a saúde.
SYSTEM_PROMPT = """
You might be an knowledgeable Meals Product Analyst specialised in ingredient evaluation and diet science.
Your function is to investigate product substances, present well being insights, and determine potential considerations by combining ingredient evaluation with scientific analysis.
You make the most of your dietary data and analysis works to supply evidence-based insights, making complicated ingredient data accessible and actionable for customers.
Return your response in Markdown format.
"""
INSTRUCTIONS = """
* Learn ingredient record from product picture
* Keep in mind the person is probably not educated concerning the product, break it down in easy phrases like explaining to 10 12 months child
* Establish synthetic components and preservatives
* Test towards main dietary restrictions (vegan, halal, kosher). Embrace this in response.
* Fee dietary worth on scale of 1-5
* Spotlight key well being implications or considerations
* Recommend more healthy alternate options if wanted
* Present temporary evidence-based suggestions
* Use Search instrument for getting context
"""Etapa 4: definir o objeto agente
O Agente, construído usando Phidata, é configurado para processar a formatação de markdown e operar com base no immediate do sistema e nas instruções definidas anteriormente. O modelo de raciocínio utilizado neste exemplo é o Gemini 2.0 Flash, conhecido por sua capacidade superior de compreensão de imagens e vídeos em comparação com outros modelos.
Para integração da ferramenta, usaremos o Tavily Search, um mecanismo avançado de busca na net que fornece contexto relevante diretamente em resposta às consultas do usuário, evitando descrições, URLs e parâmetros irrelevantes desnecessários.
agent = Agent(
mannequin = Gemini(id="gemini-2.0-flash-exp"),
instruments = (TavilyTools()),
markdown=True,
system_prompt = SYSTEM_PROMPT,
directions = INSTRUCTIONS
)Passo 5: Multimodal – Compreendendo a Imagem
Com os componentes do Agente agora instalados, a próxima etapa é fornecer informações do usuário. Isso pode ser feito de duas maneiras: passando o caminho da imagem ou a URL, junto com um immediate do usuário especificando quais informações precisam ser extraídas da imagem fornecida.
Abordagem: 1 Usando Caminho de Imagem

agent.print_response(
"Analyze the product picture",
pictures = ("pictures/bournvita.jpg"),
stream=True
)Saída:
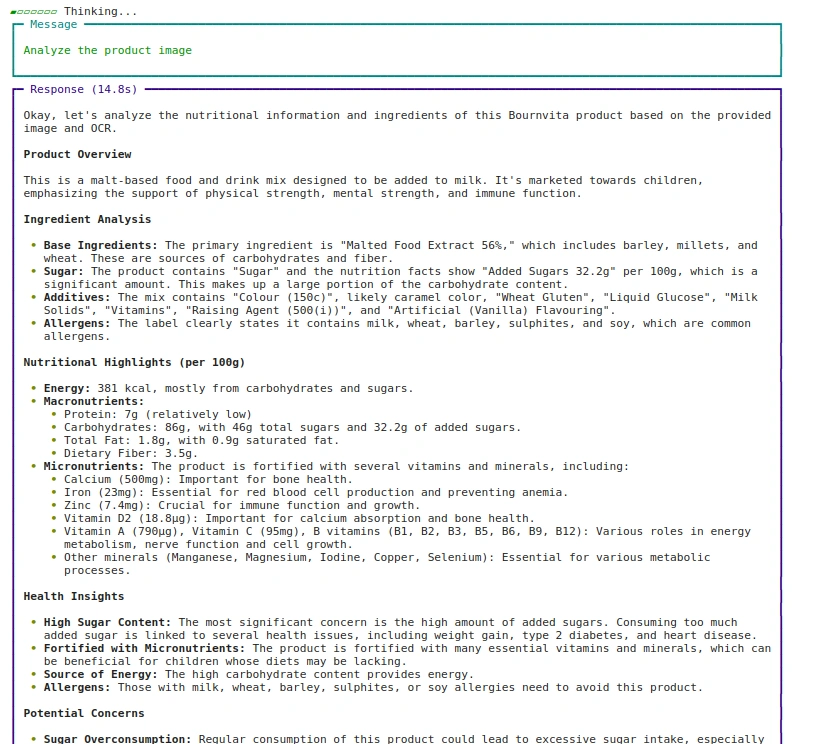
Abordagem: 2 Usando URL
agent.print_response(
"Analyze the product picture",
pictures = ("https://beardo.in/cdn/store/merchandise/9_2ba7ece4-0372-4a34-8040-5dc40c89f103.jpg?v=1703589764&width=1946"),
stream=True
)Saída:
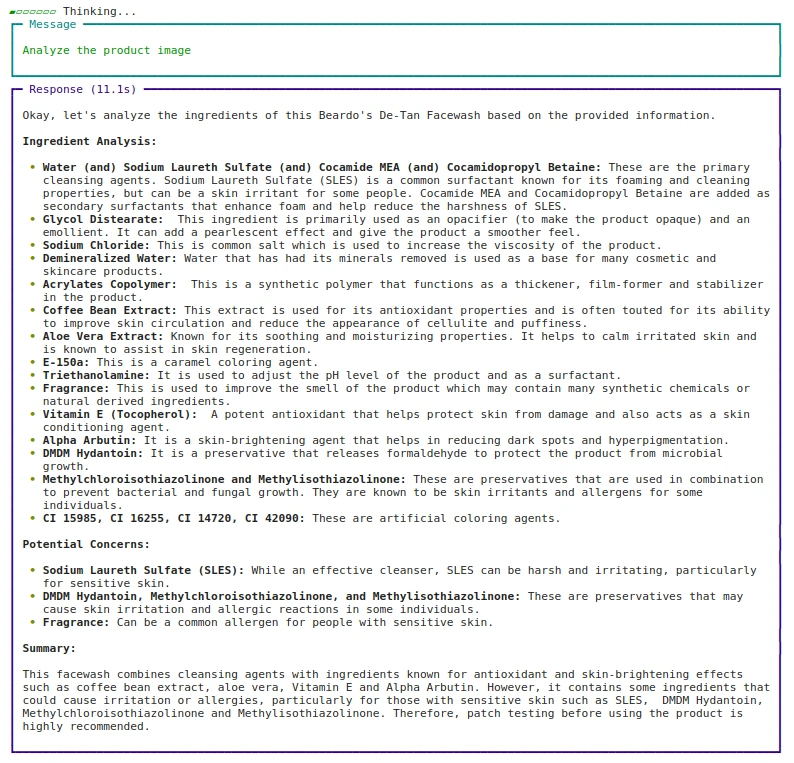
Etapa 6: desenvolver o aplicativo da Internet usando Streamlit
Agora que sabemos como executar o Agente Multimodal, vamos construir a parte UI usando Streamlit.
import streamlit as st
from PIL import Picture
from io import BytesIO
from tempfile import NamedTemporaryFile
st.title("🔍 Product Ingredient Analyzer")Para otimizar o desempenho, defina a inferência do Agente em uma função armazenada em cache. O decorador de cache ajuda a melhorar a eficiência reutilizando a instância do Agente.
Como estamos usando Streamlit, que atualiza a página inteira após cada loop de evento ou acionador de widget, adicionar st.cache_resource garante que a função não seja atualizada e a salva no cache.
@st.cache_resource
def get_agent():
return Agent(
mannequin=Gemini(id="gemini-2.0-flash-exp"),
system_prompt=SYSTEM_PROMPT,
directions=INSTRUCTIONS,
instruments=(TavilyTools(api_key=os.getenv("TAVILY_API_KEY"))),
markdown=True,
)Quando um novo caminho de imagem é fornecido pelo usuário, a função analyze_image é executada e executa o objeto Agente definido em get_agent. Para captura em tempo actual e opção de add de imagens, o arquivo enviado precisa ser salvo temporariamente para processamento.
A imagem é armazenada em um arquivo temporário e, assim que a execução for concluída, o arquivo temporário é excluído para liberar recursos. Isso pode ser feito usando a função NamedTemporaryFile da biblioteca tempfile.
def analyze_image(image_path):
agent = get_agent()
with st.spinner('Analyzing picture...'):
response = agent.run(
"Analyze the given picture",
pictures=(image_path),
)
st.markdown(response.content material)
def save_uploaded_file(uploaded_file):
with NamedTemporaryFile(dir=".", suffix='.jpg', delete=False) as f:
f.write(uploaded_file.getbuffer())
return f.titlePara uma interface de usuário melhor, quando um usuário seleciona uma imagem, é provável que ela tenha resoluções e tamanhos variados. Para manter um structure consistente e exibir a imagem corretamente, podemos redimensionar a imagem enviada ou capturada para garantir que ela caiba claramente na tela.
O algoritmo de reamostragem LANCZOS fornece redimensionamento de alta qualidade, particularmente benéfico para imagens de produtos onde a clareza do texto é essential para a análise de ingredientes.
MAX_IMAGE_WIDTH = 300
def resize_image_for_display(image_file):
img = Picture.open(image_file)
aspect_ratio = img.peak / img.width
new_height = int(MAX_IMAGE_WIDTH * aspect_ratio)
img = img.resize((MAX_IMAGE_WIDTH, new_height), Picture.Resampling.LANCZOS)
buf = BytesIO()
img.save(buf, format="PNG")
return buf.getvalue()Etapa 7: recursos de interface do usuário para Streamlit
A interface é dividida em três abas de navegação onde o usuário pode escolher sua preferência de interesses:
- Guia-1: Produtos de exemplo que os usuários podem selecionar para testar o aplicativo
- Guia-2: Carregar uma imagem de sua escolha se já estiver salvo.
- Guia 3: Capturar ou Tire uma foto ao vivo e analise o produto.
Repetimos o mesmo fluxo lógico para todas as 3 abas:
- Primeiro, escolha a imagem de sua preferência e redimensione-a para exibição na interface do Streamlit usando st.imagem.
- Segundo, salve essa imagem em um diretório temporário para processá-la no objeto Agente.
- Terceiro, analise a imagem onde ocorrerá a execução do Agente usando Gemini 2.0 LLM e a ferramenta Tavily Search.
O gerenciamento de estado é feito por meio do estado da sessão do Streamlit, rastreando exemplos selecionados e standing de análise.

def predominant():
if 'selected_example' not in st.session_state:
st.session_state.selected_example = None
if 'analyze_clicked' not in st.session_state:
st.session_state.analyze_clicked = False
tab_examples, tab_upload, tab_camera = st.tabs((
"📚 Instance Merchandise",
"📤 Add Picture",
"📸 Take Picture"
))
with tab_examples:
example_images = {
"🥤 Power Drink": "pictures/bournvita.jpg",
"🥔 Potato Chips": "pictures/lays.jpg",
"🧴 Shampoo": "pictures/shampoo.jpg"
}
cols = st.columns(3)
for idx, (title, path) in enumerate(example_images.objects()):
with cols(idx):
if st.button(title, use_container_width=True):
st.session_state.selected_example = path
st.session_state.analyze_clicked = False
with tab_upload:
uploaded_file = st.file_uploader(
"Add product picture",
sort=("jpg", "jpeg", "png"),
assist="Add a transparent picture of the product's ingredient record"
)
if uploaded_file:
resized_image = resize_image_for_display(uploaded_file)
st.picture(resized_image, caption="Uploaded Picture", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button("🔍 Analyze Uploaded Picture", key="analyze_upload"):
temp_path = save_uploaded_file(uploaded_file)
analyze_image(temp_path)
os.unlink(temp_path)
with tab_camera:
camera_photo = st.camera_input("Take an image of the product")
if camera_photo:
resized_image = resize_image_for_display(camera_photo)
st.picture(resized_image, caption="Captured Picture", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button("🔍 Analyze Captured Picture", key="analyze_camera"):
temp_path = save_uploaded_file(camera_photo)
analyze_image(temp_path)
os.unlink(temp_path)
if st.session_state.selected_example:
st.divider()
st.subheader("Chosen Product")
resized_image = resize_image_for_display(st.session_state.selected_example)
st.picture(resized_image, caption="Chosen Instance", use_container_width=False, width=MAX_IMAGE_WIDTH)
if st.button("🔍 Analyze Instance", key="analyze_example") and never st.session_state.analyze_clicked:
st.session_state.analyze_clicked = True
analyze_image(st.session_state.selected_example)Hyperlinks importantes
- Você pode encontrar o código completo aqui.
- Substitua o “
”Espaço reservado com suas chaves. - Para tab_examples, você precisa ter uma imagem de pasta. E salve as imagens ali. Aqui está o URL do GitHub com diretório de imagens aqui.
- Se você estiver interessado em usar o caso de uso, aqui está o aplicativo implantado aqui.
Conclusão
Os agentes multimodais de IA representam um grande avanço na forma como podemos interagir e compreender informações complexas em nossas vidas diárias. Ao combinar processamento de visão, compreensão de linguagem pure e recursos de pesquisa na net, esses sistemas, como o Product Ingredient Analyzer, podem fornecer análises instantâneas e abrangentes de produtos e seus ingredientes, tornando a tomada de decisões informadas mais acessível a todos.
Principais conclusões
- Os agentes multimodais de IA melhoram a forma como entendemos as informações do produto. Eles combinam análise de texto e imagem.
- Com Phidata, uma estrutura de código aberto, podemos construir e gerenciar sistemas de agentes. Esses sistemas usam modelos como GPT-4o e Gemini 2.0.
- Os agentes usam ferramentas como processamento de visão e pesquisa na net. Isso torna sua análise mais completa e precisa. Os LLMs têm conhecimento limitado, então os agentes usam ferramentas para lidar melhor com tarefas complexas.
- Streamlit facilita a construção de aplicativos da net para ferramentas baseadas em LLM. Os exemplos incluem RAG e agentes multimodais.
- Bons avisos e instruções do sistema orientam o agente. Isso garante respostas úteis e precisas.
Perguntas frequentes
A. LLaVA (Massive Language and Imaginative and prescient Assistant), Pixtral-12B da Mistral.AI, Multimodal-GPT da OpenFlamingo, NVILA da Nvidia e modelo Qwen são alguns modelos de linguagem de visão multimodal de código aberto ou pesos que processam texto e imagens para tarefas como respostas visuais a perguntas.
R. Sim, o Llama 3 é multimodal, e também os modelos Llama 3.2 Imaginative and prescient (parâmetros 11B e 90B) processam texto e imagens, permitindo tarefas como legenda de imagens e raciocínio visible.
A. Um Modelo Multimodal de Grande Linguagem (LLM) processa e gera dados em várias modalidades, como texto, imagens e áudio. Em contraste, um Agente Multimodal utiliza tais modelos para interagir com o seu ambiente, executar tarefas e tomar decisões com base em entradas multimodais, muitas vezes integrando ferramentas e sistemas adicionais para executar ações complexas.
A mídia mostrada neste artigo não é propriedade da Analytics Vidhya e é usada a critério do Autor.
Cientista de dados no AI Planet || YouTube- AIWithTarun || Desenvolvedor Google especialista em ML || Ganhou 5 hackathons de IA || Coorganizador do TensorFlow Consumer Group Bangalore || Embaixador de Torta e IA na DeepLearningAI