Introdução
Neste weblog, compartilhamos a jornada de construção de um registro de artefato otimizado sem servidor desde o início. Os principais objetivos são garantir que a distribuição da imagem do contêiner escala perfeitamente sob tráfego imprevisível e sem servidor e permanece disponível em cenários desafiadores, como falhas importantes de dependência.
Os contêineres são o moderno formato de implantação nativo em nuvem, que apresenta isolamento, portabilidade e eco-sistema de ferramentas ricas. Os Serviços Internos do Databricks estão sendo executados como contêineres desde 2017. Implantamos um projeto maduro e apresentamos rico em código aberto como o registro de contêineres. Funcionou bem como os serviços eram geralmente implantados em um ritmo controlado.
Avançando para 2021, quando o Databricks começou a iniciar o DBSQL sem servidor e os produtos de gerência de modelos, espera -se que milhões de VMs fossem provisionadas todos os dias e cada VM puxaria mais de 10 imagens do registro do contêiner. Ao contrário de outros serviços internos, o tráfego de tração de imagem sem servidor é acionado pelo uso do cliente e pode atingir um limite superior muito mais alto.
A Figura 1 é uma carga de tráfego de produção de 1 semana (por exemplo, clientes que lançam novos information warehouses ou pontos de extremidade MLServing) que mostram que o tráfego de pico de pico de DataPlane sem servidor é superior a 100x em comparação com o dos serviços internos.
Com base em nossos testes de estresse, concluímos que o registro de contêiner de código aberto não poderia atender aos requisitos da sem servidor.
Desafios sem servidor
A Figura 2 mostra os principais desafios de servir cargas de trabalho sem servidor com registro de contêiner de código aberto:
- Difícil acompanhar o crescimento dos Databricks:
- Os metadados da imagem do contêiner são apoiados por bancos de dados relacionais, que escalam vertical e lentamente.
- No pico de tráfego, milhares de instâncias de registro precisam ser provisionadas em alguns segundos, que geralmente se tornam um gargalo no caminho crítico da extração da imagem.
- Não suficientemente confiável:
- As solicitações de servir são complexas na arquitetura baseada em OSS, que introduz mais modos de falha.
- Dependências como banco de dados relacional ou armazenamento de objetos em nuvem que estão baixos levam a uma interrupção complete regional.
- Caro para operar: Os registros da OSS não são otimizados para o desempenho e tendem a ter alto uso de recursos (Intensivo da CPU). Executar -os na escala dos Databricks é proibitivamente caro.

E os registros de contêineres gerenciados em nuvem? Eles geralmente são mais escaláveis e oferecem disponibilidade SLA. No entanto, diferentes serviços de provedores de nuvem têm diferentes cotas, limitações, confiabilidade, escalabilidade e características de desempenho. O Databricks opera em várias nuvens, descobrimos que a heterogeneidade das nuvens não atendia aos requisitos e period muito caro para operar.
A distribuição de imagem ponto a ponto (P2P) é outra abordagem comum para melhorar a escalabilidade, em uma camada de infraestrutura diferente. Reduz principalmente a carga para metadados do registro, mas ainda está sujeito a riscos de confiabilidade mencionados. Mais tarde, também introduzimos a camada P2P para reduzir a taxa de transferência de saída de armazenamento em nuvem. No Databricks, acreditamos que cada camada precisa ser otimizada para fornecer confiabilidade para toda a pilha.
Apresentando o registro do artefato
Concluímos que period necessário criar um registro otimizado sem servidor para atender aos requisitos e garantir que fiquemos à frente do rápido crescimento dos Databricks. Portanto, construímos o Registro de Artefatos – um Serviço de Registro de Contêineres de Multi -Cloud. O registro de artefato foi projetado com os seguintes princípios:
- Tudo escala horizontalmente:
- Database relacional removida (postgreSQL); Em vez disso, os metadados foram persistidos no armazenamento de objetos em nuvem (uma dependência existente para imagens manifestam e camadas de armazenamento). Os armazenamentos de objetos em nuvem são muito mais escaláveis e foram bem abstraídos nas nuvens.
- Removeu a instância do cache (Redis) e a substituiu por um cache simples na memória.
- Escalando/baixo em segundos: Adicionado cache extenso para manifestos de imagem e solicitações de blob para reduzir o acerto no caminho lento do código (registro). Como resultado, apenas algumas instâncias (provisionadas em alguns segundos) precisam ser adicionadas em vez de centenas.
- Simples é confiável: Consolidado 3 micro-serviços de código aberto (NGINX, Serviço e Registro de Metadados) em um único serviço, Artifact-Registry. Isso reduz 2 lúpulos extras de rede e melhora o desempenho/confiabilidade.
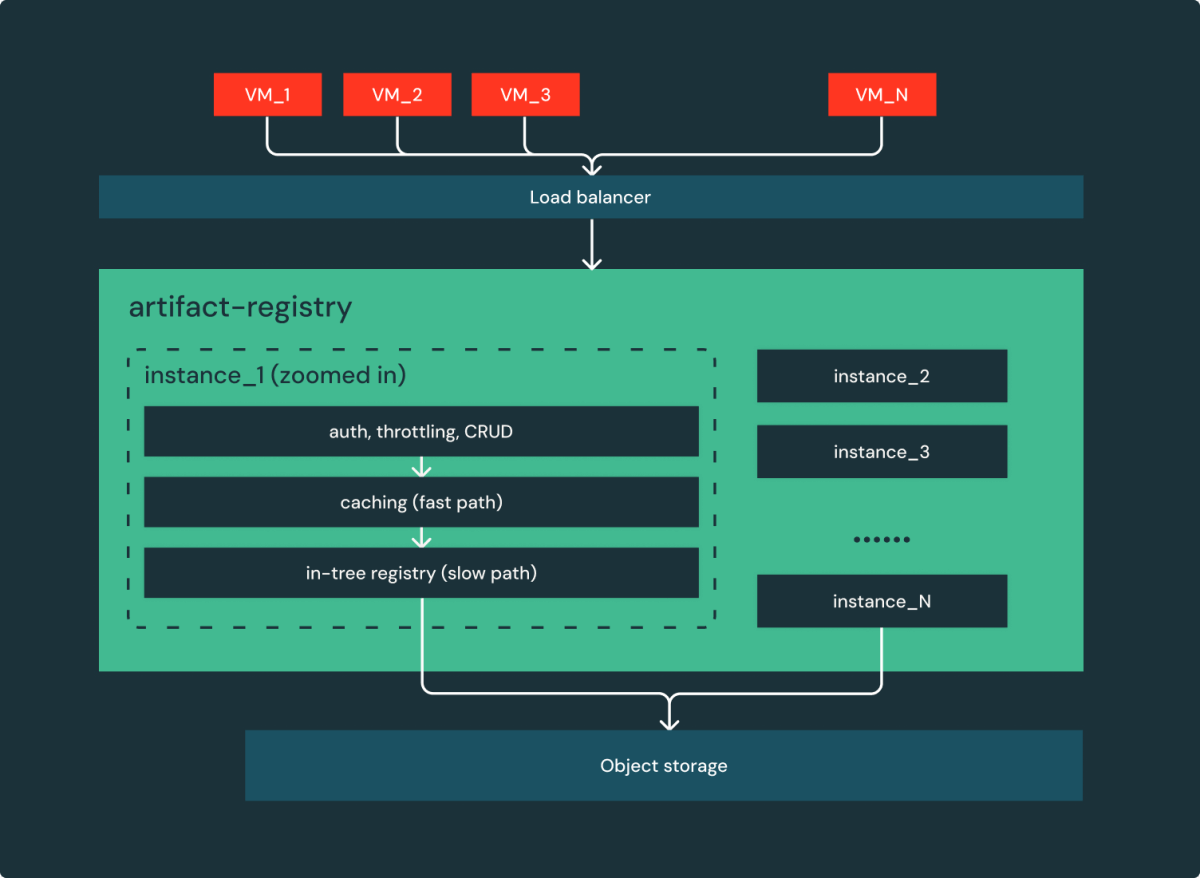
Conforme mostrado na Figura 3, transformamos essencialmente o sistema authentic que consiste em 5 serviços em um serviço da Net simples: Um monte de instâncias apátridas por trás de um balanceador de carga que atende aos pedidos!
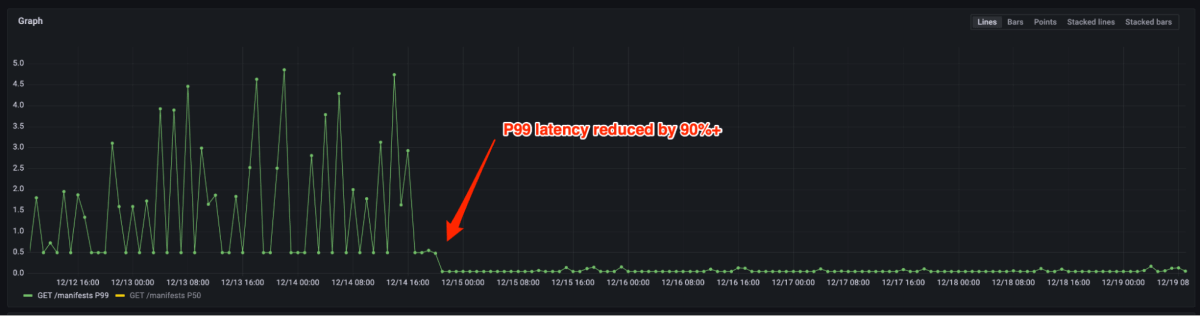
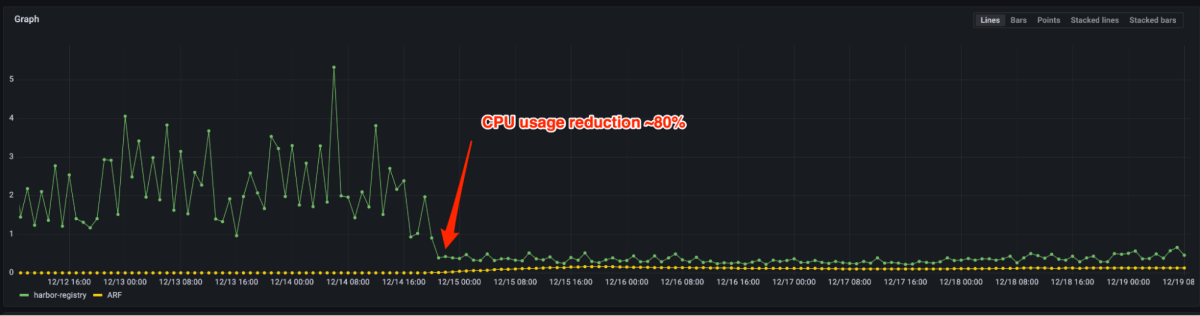
As Figura 4 e 5 mostram que a latência de p99 reduziu em 90%+ e o uso da CPU reduzido em 80% após a migração do registro de código aberto para o registro do artefato. Agora, precisamos apenas provisionar algumas instâncias para a mesma carga em relação a milhares de pessoas anteriormente. De fato, o manuseio do tráfego de pico de produção não requer escala na maioria dos casos. Caso a escala automática seja acionada, isso pode ser feito em alguns segundos.
A principal decisão de design é substituir completamente os bancos de dados relacionais pelo armazenamento de objetos em nuvem para metadados da imagem. Os bancos de dados relacionais são ideais para consistência e capacidade de consulta enriquecida, mas têm limitações de escalabilidade e confiabilidade. Por exemplo, todas as solicitações de tração de imagens exigiam autenticação/autorização, que foi atendida pelo PostgreSQL na implementação de código aberto. Os picos de trânsito causavam regularmente soluços de desempenho. A consulta de pesquisa usada por auth pode ser facilmente substituída por uma operação de GE de um armazenamento de chave/valor mais escalável. Também fizemos trocas cuidadosas entre conveniência e confiabilidade. Por exemplo, usando um banco de dados relacional, é fácil agregar a contagem de imagens, agrupamento de tamanho complete por diferentes dimensões. Suportar esses recursos, no entanto, não é trivial no armazenamento de objetos. Em favor da confiabilidade e escalabilidade, decidimos que o Artifato Registro não apoia tais estatísticas.
Sobrevivendo a interrupções de objetos de nuvem
Com a confiabilidade do serviço melhorada significativamente após a eliminação das dependências do banco de dados relacional, cache remoto e microsserviços internos, ainda existe um modo de falha que ocasionalmente acontece: interrupções de armazenamento de objetos em nuvem. Os armazenamentos de objeto em nuvem são geralmente muito confiáveis e escaláveis; No entanto, quando estão indisponíveis (às vezes por horas), potencialmente causa interrupções regionais. A Databricks ‘mantém uma barra alta em confiabilidade para minimizar o impacto das interrupções subjacentes à nuvem e continuar a atender nossos clientes.
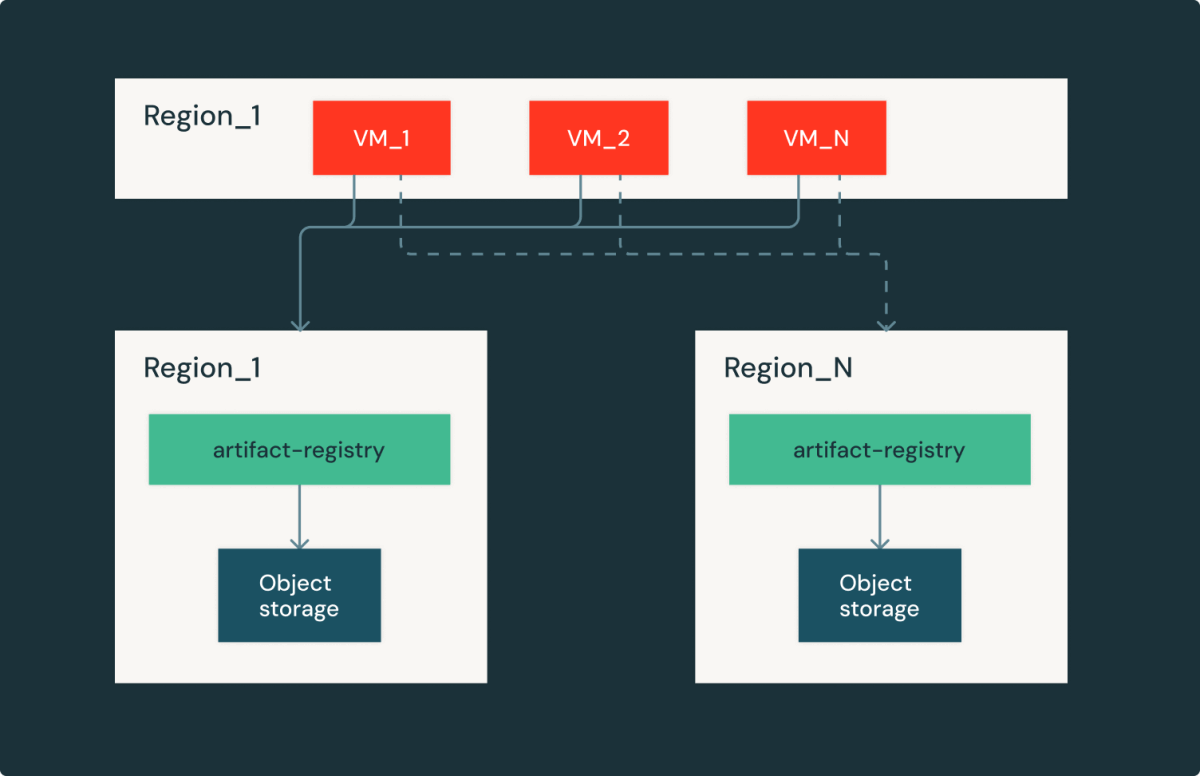
O registro de artefatos é um serviço regional, o que significa que cada nuvem/região tem uma réplica idêntica na região. Essa configuração nos dá a capacidade de falhar em diferentes regiões com a troca na latência do obtain da imagem e no custo de saída. Ao curar cuidadosamente a latência e a capacidade, conseguimos nos recuperar rapidamente das interrupções do provedor de nuvem e continuar atendendo aos clientes dos Databricks.
Conclusões
Nesta postagem do weblog, compartilhamos nossa jornada de construção do Registro de Containers de Databricks de servir tráfego interno de baixa rotatividade para o cliente enfrentando cargas de trabalho sem servidor. Nós, registro de artefato otimizado sem servidor, criado para o servidor. Comparado ao registro de código aberto, ele forneceu 90% de redução de latência P99 e 80% de usos de recursos. Além disso, projetamos o sistema para tolerar interrupções regionais de provedores de nuvem, melhorando ainda mais a confiabilidade. Hoje, o registro de artefatos continua sendo uma base sólida que torna a confiabilidade, a escalabilidade e a eficiência sem costura em meio ao crescimento rápido dos Databricks.
Reconhecimento
Construir infraestrutura confiável e escalável sem servidor é um esforço de equipe de nossos principais colaboradores: Robert Landlord, Tian Ouyang, Jin Dong e Siddharth Gupta. O weblog também é um trabalho em equipe – agradecemos os revisores perspicazes fornecidos por Xinyang Ge e Rohit Jnagal.