O que é um gráfico de conhecimento?
Para entender por que se pode usar um gráfico de conhecimento (kg) em vez de outra representação estruturada de dados, é importante reconhecer seu foco em relações explícitas entre entidades – como empresas, pessoas, máquinas ou clientes – e seus atributos ou recursos associados. Diferentemente de incorporação ou pesquisa de vetores, que priorizam a similaridade em espaços de alta dimensão, um gráfico de conhecimento se destaca em representar as conexões semânticas e o contexto entre os pontos de dados. Uma unidade básica de um gráfico de conhecimento é um fato. Os fatos podem ser representados como um trigêmeo de qualquer uma das seguintes maneiras:
Dois exemplos simples de kg são mostrados abaixo. O exemplo esquerdo de fato poderia ser

Agora que você entende o significado da semântica em gráficos de conhecimento, vamos apresentar o conjunto de dados que usaremos nos próximos exemplos de código: o Bloodhound DataSet. O Bloodhound é um conjunto de dados especializado projetado para analisar relacionamentos e interações nos ambientes do Energetic Listing. É amplamente utilizado para auditoria de segurança, análise de caminho de ataque e obter informações sobre possíveis vulnerabilidades nas estruturas de rede.
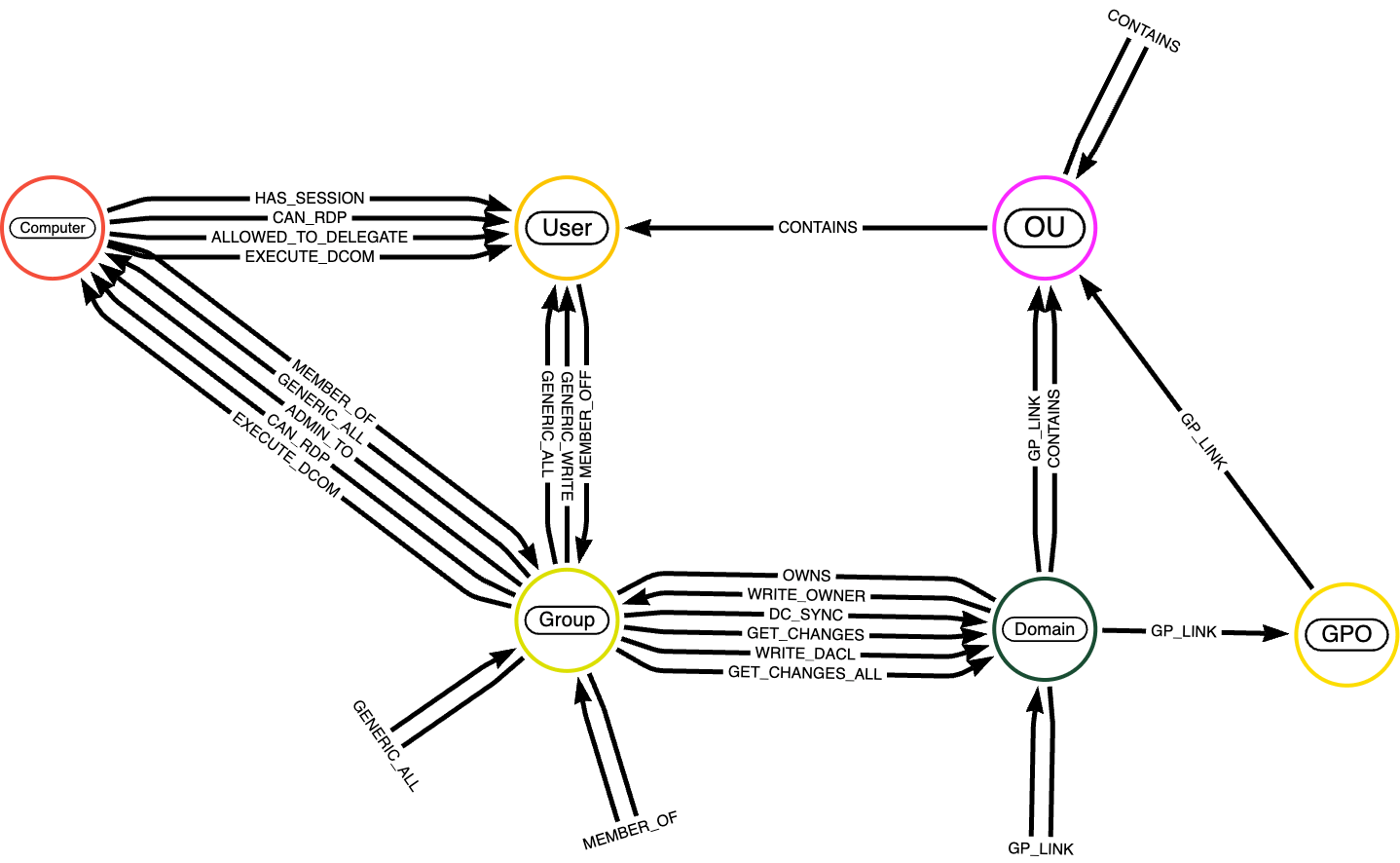
Os nós no conjunto de dados do Bloodhound representam entidades em um ambiente do Energetic Listing. Estes normalmente incluem:
- Usuários: representa contas de usuário individuais no domínio.
- Grupos: Representa grupos de segurança ou distribuição que agregam usuários ou outros grupos para atribuições de permissão.
- Computadores: representa máquinas individuais na rede (estações de trabalho ou servidores).
- Domínios: Representa o domínio do Energetic Listing que organiza e gerencia usuários, computadores e grupos.
- Unidades organizacionais (OUS): Representa os contêineres usados para estruturar e gerenciar objetos como usuários ou grupos.
- GPOs (Objetos de Política de Grupo): Representa políticas aplicadas a usuários e computadores dentro do domínio.
Uma descrição detalhada das entidades de nó é disponível aqui. Relacionamentos no gráfico definem interações, associações e permissões entre nós; Uma descrição completa das bordas é disponível aqui.
Quando escolher o Graphrag em vez de tradicional pano
A vantagem principal do Graphrag sobre o RAG padrão está em sua capacidade de executar correspondência exata Durante a etapa de recuperação. Isso é possível em parte por Preservando explicitamente a semântica das consultas de linguagem pure na linguagem de consulta de gráficos a jusante. Embora as técnicas densas de recuperação baseadas na similaridade de cosseno se destacem na captura de semântica difusa e na recuperação de informações relacionadas, mesmo quando a consulta não é uma correspondência exata, há casos em que a precisão é crítica. Isso torna o Graphrag particularmente valioso em domínios onde a ambiguidade é inaceitável, como conformidade, conjuntos de dados legais ou altamente selecionados.
Dito isto, as duas abordagens não são mutuamente exclusivas e geralmente são combinadas para alavancar seus respectivos pontos fortes. A densa recuperação pode lançar uma ampla rede para relevância semântica, enquanto o gráfico de conhecimento refina os resultados com correspondências exatas ou raciocínio sobre os relacionamentos.
Quando escolher o pano tradicional em relação ao Graphrag
Embora o Graphrag tenha vantagens únicas, ele também vem com desafios. Um obstáculo importante é Definindo o problema corretamente-Não todos os dados ou casos de uso são adequados para um gráfico de conhecimento. Se a tarefa envolver um texto altamente não estruturado ou não exigir relacionamentos explícitos, a complexidade adicional pode não valer a pena, levando a ineficiências e resultados abaixo do ultimate.
Outro desafio é estruturar e manter o gráfico de conhecimento. Projetar um esquema eficaz requer um planejamento cuidadoso para equilibrar detalhes e complexidade. O projeto de esquema ruim pode afetar o desempenho e a escalabilidade, enquanto a manutenção contínua exige recursos e conhecimentos.
Desempenho em tempo actual é outra limitação. Bancos de dados de gráficos como o NEO4J podem lutar com consultas em tempo actual em conjuntos de dados grandes ou frequentemente atualizados devido a travessias complexas e consultas de vários hop, tornando-os mais lentos que os sistemas de recuperação densos. Nesses casos, uma abordagem híbrida-utilizando densa recuperação para o refinamento de velocidade e gráfico para análise pós-quaria-pode fornecer uma solução mais prática.
GraphDB e incorporação
Gráfico DBS como Neo4J geralmente também fornece recursos de pesquisa vetorial by way of ÍNDICES HNSW. A diferença aqui é como eles usam esse índice para fornecer melhores resultados em comparação com os bancos de dados vetoriais. Quando você realiza uma consulta, o NEO4J usa o índice HNSW para identificar as incorporações de correspondência mais próximas com base em medidas como similaridade de cosseno ou distância euclidiana. Esta etapa é essential para encontrar um ponto de partida em seus dados que se alinhem semanticamente com a consulta, alavancando a semântica implícita dada pela pesquisa de vetores.
O que diferencia os bancos de dados de gráficos é a capacidade de combinar essa recuperação inicial baseada em vetores com seus poderosos recursos de travessia. Depois de encontrar o ponto de entrada usando o índice HNSW, o neo4j aproveita o Semântica explícita definido pelos relacionamentos no gráfico do conhecimento. Esses relacionamentos permitem que o banco de dados atravesse o gráfico e colete contexto adicional, descobrindo conexões significativas entre nós. Esta combinação de Semântica implícita de incorporação e Semântica explícita A partir de relacionamentos gráficos, permite que os bancos de dados gráficos forneçam respostas mais precisas e contextualmente ricas do que qualquer uma das abordagens poderia alcançar sozinho.
Graphrag de ponta a ponta nos bancos de dados
Graphrag é um ótimo exemplo de Sistemas de IA compostos em ação, onde vários componentes da IA trabalham juntos para tornar a recuperação mais inteligente e com mais consciência do contexto. Nesta seção, examinaremos como tudo se encaixa.
Arquitetura Graphrag
Abaixo está um diagrama de arquitetura demonstrando como as questões de linguagem pure de um analista podem recuperar informações de um gráfico de conhecimento Neo4J.
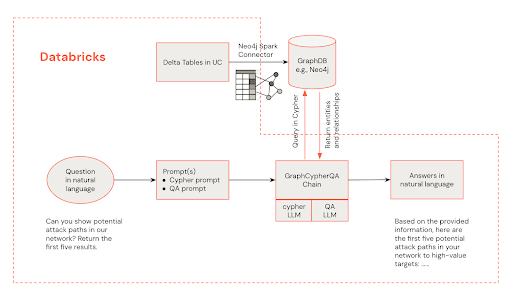
A arquitetura para detecção de ameaças movidas a graphrag combina os pontos fortes dos Databricks e Neo4J:
- Interface do Analista do Centro de Operações de Segurança (SOC): os analistas interagem com o sistema através de Databricks, iniciando consultas e recebendo recomendações de alerta.
- Processamento de Databricks: o Databricks lida com a integração de Processamento de Dados, LLM e serve como o hub central da solução.
- Gráfico de conhecimento Neo4J: O NEO4J armazena e gerencia o gráfico de conhecimento de segurança cibernética, permitindo consultas complexas de relacionamento.
Visão geral da implementação
Para este weblog, estamos pulando os detalhes do código – consulte o github repositório Para a implementação completa. Vamos percorrer as principais etapas para construir e implantar um agente graphrag.
- Construa um gráfico de conhecimento a partir de mesas delta: No caderno, discutimos cenários sobre dados estruturados e dados não estruturados. O Conector de faísca neo4j Fornece um meio muito simples de transformar dados no catálogo de unidades em entidades gráficas (nós/relacionamentos).
- Implante LLMS para consulta Cypher e QA: O Graphrag requer LLMS para geração de consultas e resumo. Demonstramos como implantar o GPT-4O, LLAMA-3.X, um modelo de text2cypher de ajuste fino do Huggingface e serve-os usando um Taxa de transferência provisionada endpoint.
- Criar e testar a cadeia de graphrag: Demonstramos como usar o LLM diferente para o Cypher e o QA LLMS e os avisos by way of Graphcypherqachain. Isso nos permite sintonizar ainda mais com resultados de rastreamento de caixa de vidro usando Rastreamento de mlflow.
- Implantar o agente com estrutura de agente de AI em mosaico: Usar Mosaic AI Agent Framework e mlflow para implantar o agente. No caderno, o processo inclui registrar o modelo, registrá -lo no catálogo de unidades, implantá -lo em um terminal de serviço e iniciar um aplicativo de revisão para conversar.

Conclusão
O Graphrag é uma abordagem poderosa, mas altamente personalizável, para a construção de agentes que fornecem saídas de IA mais determinísticas e relevantes contextualmente. No entanto, seu design é específico do caso, exigindo arquitetura atenciosa e ajuste específico do problema. Ao integrar gráficos de conhecimento com a infraestrutura e ferramentas escaláveis dos Databricks, você pode construir Sistemas de IA compostos Isso combina perfeitamente dados estruturados e não estruturados para gerar insights acionáveis com um entendimento contextual mais profundo.