Hoje, estamos explorando como a Ethernet se compara ao Infiniband em ambientes de IA/ML, concentrando -se em como Cisco Silicon One™ gerencia o congestionamento da rede e aprimora o desempenho das cargas de trabalho de IA/ML. Este submit enfatiza a importância das métricas de benchmarking e KPI na avaliação de soluções de rede, mostrando o cluster Cisco Zeus equipado com 128 GPUs NVIDIA® H100 e tecnologias de gerenciamento de congestionamento de ponta, como balanceamento de carga dinâmica e spray de pacotes.
Padrões de rede para atender às necessidades das cargas de trabalho de IA/ML
As cargas de trabalho de treinamento de IA/ML geram micro-consciência repetitiva, estressando significativamente os buffers de rede. O tráfego de GPU para GPU leste-oeste durante o treinamento de modelos exige um tecido de rede sem perdas e sem perdas. A Infiniband tem sido uma tecnologia dominante no ambiente de computação de alto desempenho (HPC) e ultimamente no ambiente AI/ML.
O Ethernet é uma alternativa madura, com recursos avançados que podem atender às demandas rigorosas das cargas de trabalho de treinamento de IA/ML e do Cisco Silicon, pode -se executar efetivamente o balanceamento de carga e gerenciamento. Partimos para comparar e comparar o Cisco Silicon One versus o Nvidia Spectrum-X ™ e o Infiniband.
Avaliação de soluções de tecido de rede para IA/ml
Os padrões de tráfego de rede variam com base no tamanho do modelo, arquitetura e técnicas de paralelização usadas em treinamento acelerado. Para avaliar as soluções de tecido de rede AI/ML, identificamos as métricas relevantes de relevantes e as principais métricas de indicador de desempenho (KPI) para as equipes de carga de trabalho e infraestrutura de IA/ML, porque elas visualizam o desempenho através de diferentes lentes.
Estabelecemos testes abrangentes para medir o desempenho e gerar métricas específicas para as equipes de carga de trabalho e infraestrutura de IA/ML. Para esses testes, usamos o cluster Zeus, com back-end e armazenamento dedicados com uma rede de tecido Clos de Folhas Folhas de 3 estágios, construída com plataformas com base na Cisco Silicon One e 128 NVIDIA H100 GPUS. (Veja a Figura 1.)

Desenvolvemos suítes de benchmarking usando ferramentas de código aberto e padrão da indústria contribuídas pela NVIDIA e outros. Nossas suítes de benchmarking incluíram o seguinte (consulte também a Tabela 1):
- Os benchmarks remotos de acesso direto de memória (RDMA) – construídos usando utilitários ibperf – para avaliar o desempenho da rede durante o congestionamento criado pela Incast
- NVIDIA Biblioteca de Comunicação Coletiva (NCCL) Benchmarks, que avaliam a taxa de transferência de aplicativos durante o treinamento e a fase de comunicação de inferência entre as GPUs
- MLCommons Mlperf Conjunto de benchmarks, que avalia as métricas mais compreendidas, o tempo de conclusão do trabalho (JCT) e os tokens por segundo pelas equipes de carga de trabalho
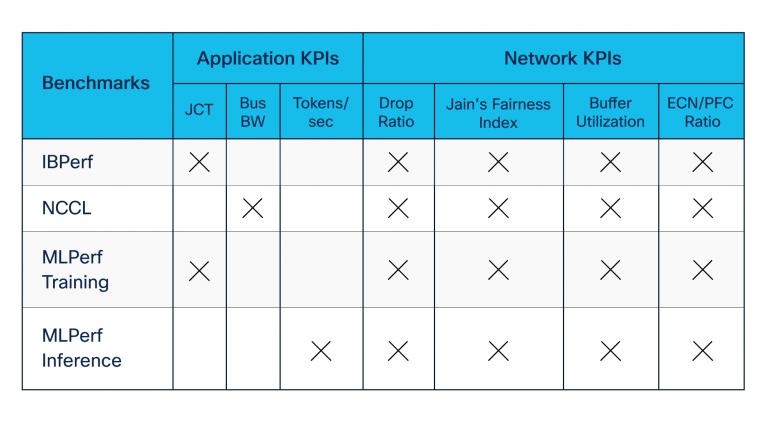
Lenda:
JCT = Tempo de conclusão do trabalho
Ônibus bw = largura de banda de ônibus
ECN/PFC = Notificação explícita de congestionamento e controle de fluxo prioritário
NCCL Benchmarking contra os recursos de prevenção de congestionamento
O congestionamento se acumula durante o estágio de propagação traseira do processo de treinamento, onde é necessária uma sincronização de gradiente entre todas as GPUs que participam do treinamento. À medida que o tamanho do modelo aumenta, o mesmo acontece com o tamanho do gradiente e o número de GPUs. Isso cria micro-consconfiança maciça no tecido da rede. A Figura 2 mostra os resultados do benchmarking de distribuição de JCT e de tráfego. Observe como o Cisco Silicon One suporta um conjunto de recursos avançados para evitar congestionamentos, como o Balanceamento de Carga Dinâmica (DLB) e as técnicas de pulverização de pacotes e a notificação de congestionamento quantizada do information heart (DCQCN) para gerenciamento de congestionamento.
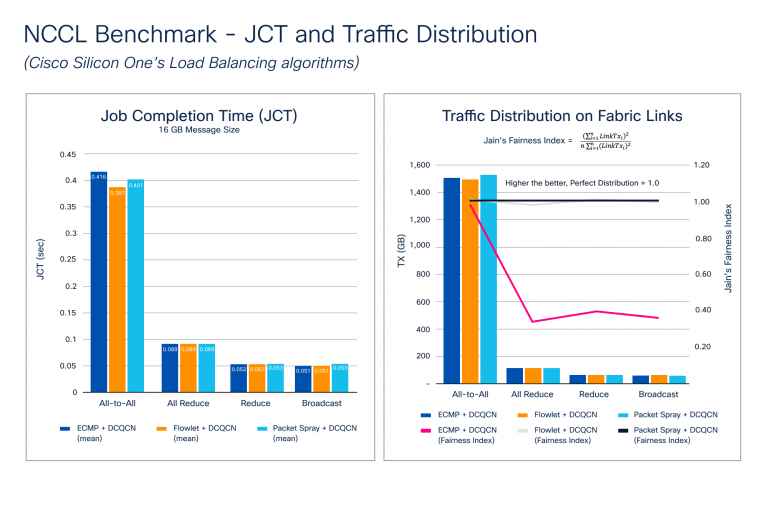
A Figura 2 ilustra como os benchmarks da NCCL se comparam contra diferentes recursos de prevenção de congestionamentos. Testamos os coletivos mais comuns com vários tamanhos de mensagens diferentes para destacar essas métricas. Os resultados mostram que o JCT melhora com o DLB e o spray de pacotes para todos, o que causa mais congestionamento devido à natureza da comunicação. Embora o JCT seja a métrica mais compreendida da perspectiva de um aplicativo, o JCT não mostra com que eficácia a rede é utilizada – algo que a equipe de infraestrutura precisa saber. Esse conhecimento pode ajudá -los a:
- Melhore a utilização da rede para obter melhor JCT
- Saiba quantas cargas de trabalho podem compartilhar o tecido da rede sem impactar adversamente o JCT
- Planeje a capacidade à medida que os casos de uso aumentam
Para avaliar a utilização de tecidos de rede, calculamos o índice de justiça de Jain, onde Linktxᵢ é a quantidade de tráfego transmitido no hyperlink de tecido:

O valor do índice varia de 0,0 a 1,0, com valores mais altos sendo melhores. Um valor de 1,0 representa a distribuição perfeita. A distribuição de tráfego no gráfico de hyperlinks de tecido na Figura 2 mostra como os algoritmos de spray de pacote e dlb criam um índice de justiça Jain quase perfeito, portanto a distribuição de tráfego em todo o tecido é quase perfeita. O ECMP usa hash estático e, dependendo da entropia do fluxo, pode levar à polarização do tráfego, causando micro-connfetion e afetando negativamente o JCT.
Silício One versus Nvidia Spectrum-X e Infiniband
O benchmark NCCL-Análise competitiva (Figura 3) mostra como o Cisco Silicon One se apresenta contra o NVIDIA Spectrum-X e o Infiniband Applied sciences. Os dados para a nvidia foram retirados do Publicação de semiânica. Observe que a Cisco não sabe como esses testes foram realizados, mas sabemos que o tamanho do cluster e a GPU para a conectividade de tecido de rede é semelhante ao cluster Cisco Zeus.
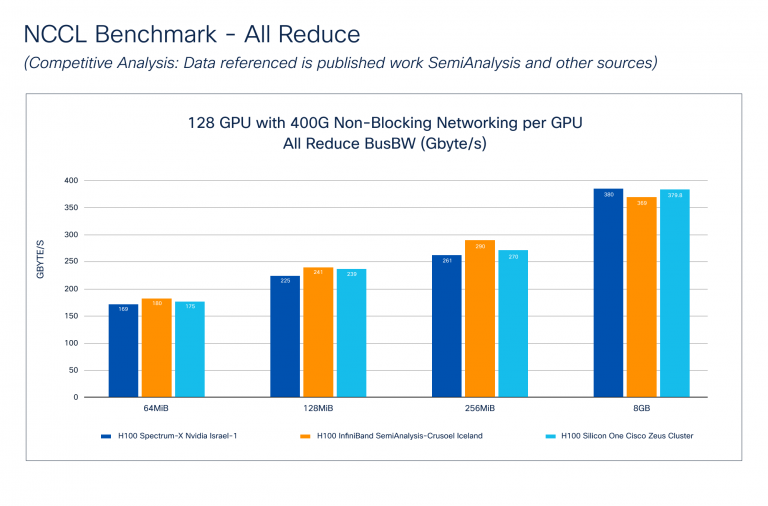
A largura de banda do ônibus (BUS BW) compara o desempenho da comunicação coletiva, medindo a velocidade das operações envolvendo várias GPUs. Cada coletivo possui uma equação matemática específica relatada durante o benchmarking. A Figura 3 mostra que o Cisco Silicon One-todos reduzem o desempenho comparativamente ao Nvidia Spectrum-X e Infiniband em vários tamanhos de mensagem.
Avaliação de desempenho de tecido de rede
O benchmark IBPERF compara o desempenho do RDMA com o ECMP, o DLB e o spray de pacotes, que são cruciais para avaliar o desempenho do tecido da rede. Cenários incest, onde várias GPUs enviam dados para uma GPU, geralmente causam congestionamento. Simulamos essas condições usando as ferramentas IBPERF.
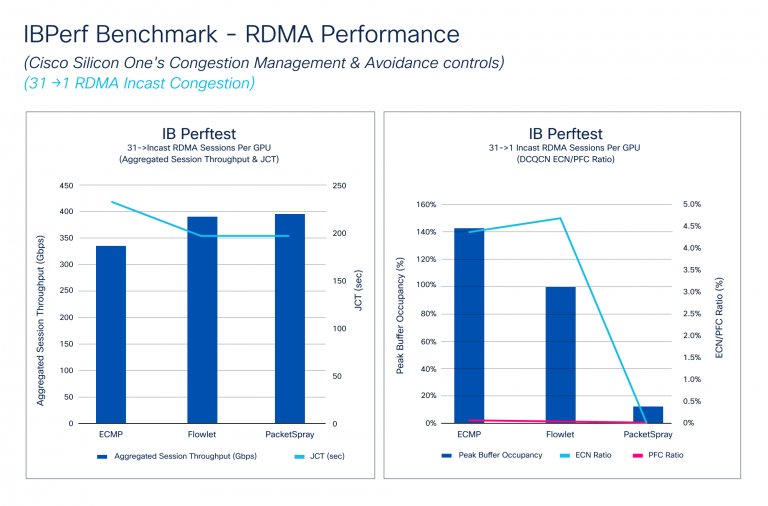
A Figura 4 mostra como a taxa de transferência da sessão agregada e o JCT respondem a diferentes algoritmos de prevenção de congestionamentos: ECMP, DLB e spray de pacotes. DLB e spray de pacotes Alcance Hyperlink Hyperlink Largura, Melhorando o JCT. Ele também ilustra como o DCQCN lida com micro-consconfiança, com as relações PFC e ECN melhorando com o DLB e caindo significativamente com o spray de pacotes. Embora o JCT melhore um pouco do DLB para o spray de pacotes, a proporção ECN cai drasticamente devido à distribuição ideally suited de tráfego do Spray de pacotes.
Referência de treinamento e inferência
O benchmark MLPerf – treinamento e inferência, publicado pelo Organização MLCommonsvisa permitir a comparação justa dos sistemas e soluções de IA/ML.
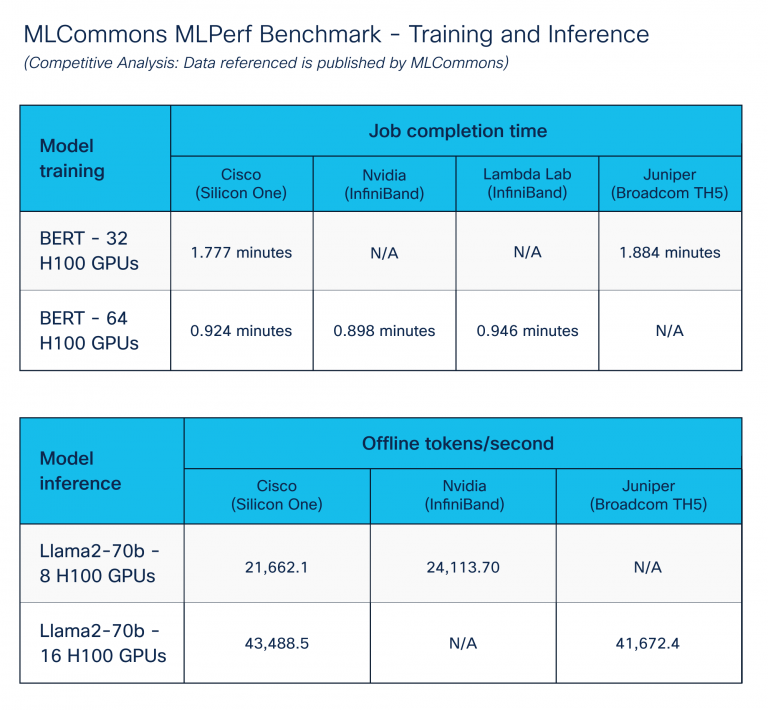
Focamos soluções de information heart de IA/ML, executando os benchmarks de treinamento e inferência. Para alcançar os melhores resultados, sintonizamos extensivamente os componentes de computação, armazenamento e rede usando recursos de gerenciamento de congestionamentos do Cisco Silicon One. A Figura 5 mostra o desempenho comparável em vários fornecedores de plataforma. O Cisco Silicon One com Ethernet tem desempenho como outras soluções de fornecedores para Ethernet.
Conclusão
Nosso profundo mergulhar na Ethernet e Infiniband em ambientes de IA/ML destaca a notável proezas do Cisco Silicon One no combate ao congestionamento e no desempenho de melhorar. Esses avanços inovadores mostram a dedicação inabalável da Cisco para fornecer soluções de rede robustas e de alto desempenho que atendam às demandas rigorosas dos aplicativos AI/ML de hoje.
Muito obrigado a Vijay Tapaskar, Will Eatherton e Kevin Wollenweber por seu apoio neste processo de benchmarking.
Discover a infraestrutura segura de IA
Descubra a infraestrutura de IA segura, escalável e de alto desempenho que você precisa desenvolver, implantar e gerenciar cargas de trabalho de IA com segurança ao escolher a Cisco Safe Manufacturing facility AI com a NVIDIA.
Compartilhar: