Pré -processamento de dados Take away erros, preenche informações ausentes e padroniza os dados para ajudar os algoritmos a encontrar padrões reais em vez de serem confundidos com ruído ou inconsistências.
Qualquer algoritmo precisa ser limpo corretamente os dados organizados em formatos estruturados antes de aprender com os dados. O processo de aprendizado de máquina requer pré -processamento de dados, pois sua etapa basic para garantir que os modelos mantenham sua precisão e eficácia operacional, garantindo a confiabilidade.
A qualidade do trabalho de pré -processamento transforma as coleções básicas de dados em informações importantes, juntamente com resultados confiáveis para todas as iniciativas de aprendizado de máquina. Este artigo o leva pelas principais etapas do pré-processamento de dados para o aprendizado de máquina, desde a limpeza e a transformação de dados até ferramentas, desafios e dicas do mundo actual para aumentar o desempenho do modelo.
Compreensão de dados brutos
Dados brutos são o ponto de partida para qualquer Projeto de aprendizado de máquinae o conhecimento de sua natureza é basic.
O processo de lidar com dados brutos às vezes pode ser desigual. Geralmente vem com ruído, entradas irrelevantes ou enganosas que podem distorcer os resultados.
Os valores ausentes são outro problema, especialmente quando os sensores falham ou as entradas são ignoradas. Os formatos inconsistentes também aparecem com frequência: os campos de knowledge podem usar estilos diferentes ou dados categóricos podem ser inseridos de várias maneiras (por exemplo, “sim”, “y”, “1”).
Reconhecer e abordar esses problemas é essencial antes de alimentar os dados em qualquer algoritmo de aprendizado de máquina. Limpe os condutores de entrada para a saída mais inteligente.
Pré -processamento de dados na mineração de dados vs aprendizado de máquina

Embora a mineração de dados e o aprendizado de máquina dependam do pré -processamento para preparar dados para análise, seus objetivos e processos diferem.
Na mineração de dados, o pré -processamento se concentra em tornar os conjuntos de dados grandes e não estruturados utilizáveis para descoberta e resumo de padrões. Isso inclui limpeza, integração e transformação e formatação de dados para consulta, cluster ou mineração de regras de associação, tarefas que nem sempre exigem treinamento de modelo.
Diferentemente do aprendizado de máquina, onde o pré -processamento geralmente se concentra na melhoria da precisão do modelo e na redução do excesso de ajuste, a mineração de dados visa a interpretabilidade e as idéias descritivas. A engenharia de recursos é menos sobre previsão e mais sobre encontrar tendências significativas.
Além disso, os fluxos de trabalho de mineração de dados podem incluir discretização e binning com mais frequência, principalmente para categorizar variáveis contínuas. Embora o pré -processamento da ML possa parar assim que o conjunto de dados de treinamento for preparado, a mineração de dados pode voltar à exploração iterativa.
Assim, as metas de pré -processamento: extração do Perception versus desempenho preditivo, definem o tom de como os dados são moldados em cada campo. Diferentemente do aprendizado de máquina, onde o pré -processamento geralmente se concentra na melhoria da precisão do modelo e na redução do excesso de ajuste, a mineração de dados visa a interpretabilidade e as idéias descritivas.
A engenharia de recursos é menos sobre previsão e mais sobre encontrar tendências significativas.
Além disso, os fluxos de trabalho de mineração de dados podem incluir discretização e binning com mais frequência, principalmente para categorizar variáveis contínuas. Embora o pré -processamento da ML possa parar assim que o conjunto de dados de treinamento for preparado, a mineração de dados pode voltar à exploração iterativa.
Etapas principais no pré -processamento de dados
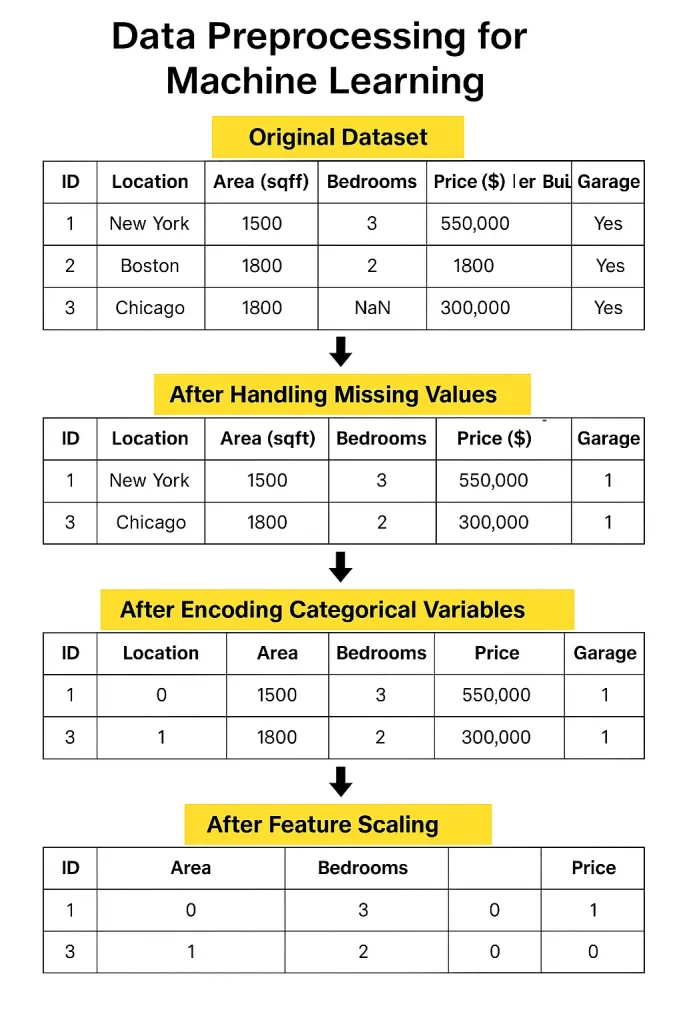
1. Limpeza de dados
Os dados do mundo actual geralmente vêm com valores ausentes, em branco na sua planilha que precisam ser preenchidos ou com cuidado.
Depois, há duplicatas, que podem pesar injustamente seus resultados. E não se esqueça de valores extremos- valores extremos que podem puxar seu modelo na direção errada se não forem controlados.
Isso pode tirar o seu modelo, para que você exact limitar, transformá -los ou excluí -los.
2. Transformação de dados
Depois que os dados são limpos, você precisa formatá -los. Se seus números variam muito ao alcance, normalização ou padronização ajuda a escalá -los de forma consistente.
Dados categóricos- nomes de país ou tipos de produtos- precisam ser convertidos em números através da codificação.
E para alguns conjuntos de dados, ajuda a agrupar valores semelhantes em caixas para reduzir o ruído e destacar os padrões.
3. Integração de dados
Freqüentemente, seus dados virão de diferentes locais- arquivos, bancos de dados ou ferramentas on-line. A fusão de tudo isso pode ser complicada, especialmente se a mesma informação parecer diferente em cada fonte.
Os conflitos de esquema, onde a mesma coluna tem nomes ou formatos diferentes, são comuns e precisam de resolução cuidadosa.
4. Redução de dados
O huge knowledge pode sobrecarregar os modelos e aumentar o tempo de processamento. Ao selecionar apenas os recursos mais úteis ou reduzir as dimensões usando técnicas como PCA ou amostragem, torna seu modelo mais rápido e muitas vezes mais preciso.
Ferramentas e bibliotecas para pré -processamento
- Scikit-Be taught é excelente para as tarefas de pré -processamento mais básicas. Possui funções integradas para preencher valores ausentes, escalar recursos, categorias de codificar e selecionar recursos essenciais. É uma biblioteca sólida e adequada para iniciantes, com tudo o que você precisa para começar.
- Pandas é outra biblioteca essencial. É incrivelmente útil para explorar e manipular dados.
- Validação de dados do tensorflow Pode ser útil se você estiver trabalhando com projetos em larga escala. Ele verifica os problemas de dados e garante que sua entrada siga a estrutura correta, algo fácil de ignorar.
- O DVC (Information Model Management) é ótimo quando o seu projeto cresce. Ele acompanha as diferentes versões de seus dados e etapas de pré -processamento para que você não perca seu trabalho ou estrague as coisas durante a colaboração.
Desafios comuns
Um dos maiores desafios hoje é o gerenciamento de dados em larga escala. Quando você tem milhões de linhas de diferentes fontes diariamente, organizando e limpando todos se torna uma tarefa séria.
O combate desses desafios requer boas ferramentas, planejamento sólido e monitoramento constante.
Outra questão significativa é automatizar o pré -processamento Pipelines. Em teoria, parece ótimo; Basta configurar um fluxo para limpar e preparar seus dados automaticamente.
Mas, na realidade, os conjuntos de dados variam, e as regras que funcionam para um pode se decompor para outro. Você ainda precisa de um olho humano para verificar os casos de borda e fazer chamadas de julgamento. A automação ajuda, mas nem sempre é plug-and-play.
Mesmo se você começar com dados limpos, as coisas mudam, os formatos mudam, as fontes atualizam e os erros entram. Sem verificações regulares, seus dados outrora perfeitos podem desmoronar lentamente, levando a insights não confiáveis e desempenho ruim do modelo.
Práticas recomendadas
Aqui estão algumas práticas recomendadas que podem fazer uma enorme diferença no sucesso do seu modelo. Vamos quebrá-los e examinar como eles se desenrolam em situações do mundo actual.
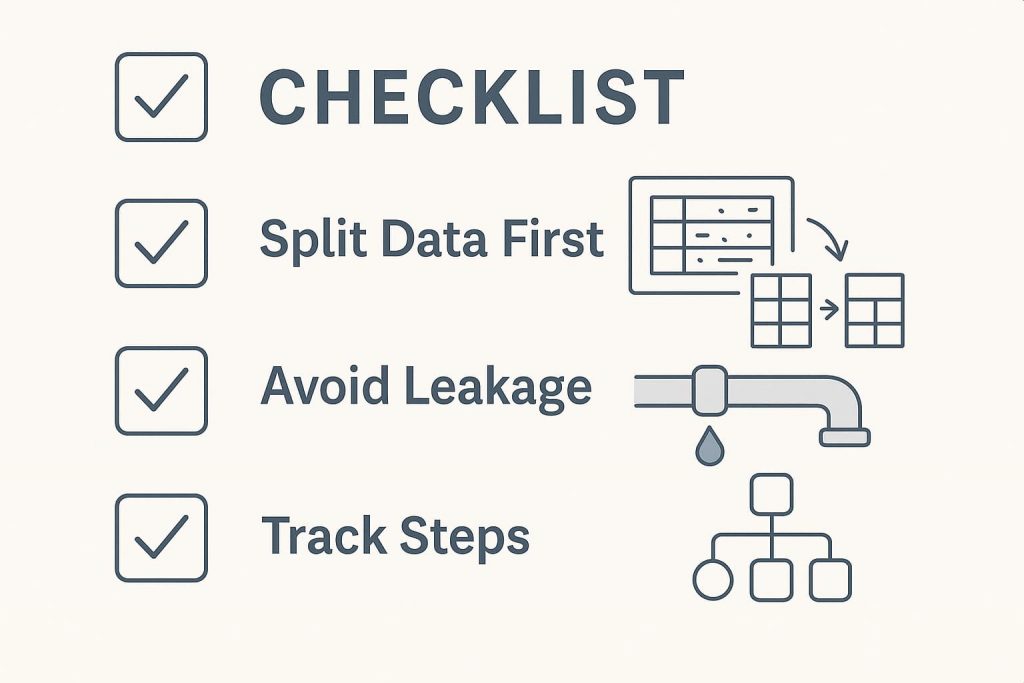
1. Comece com uma divisão de dados adequada
Um erro que muitos iniciantes cometem é fazer todo o pré -processamento no conjunto de dados completo antes de dividi -lo em conjuntos de treinamento e teste. Mas essa abordagem pode introduzir acidentalmente viés.
Por exemplo, se você dimensionar ou normalizar todo o conjunto de dados antes da divisão, as informações do conjunto de testes poderão sangrar no processo de treinamento, chamado de vazamento de dados.
Sempre divida seus dados primeiro e depois aplique pré -processamento apenas no conjunto de treinamento. Posteriormente, transforme o conjunto de testes usando os mesmos parâmetros (como média e desvio padrão). Isso mantém as coisas justas e garante que sua avaliação seja honesta.
2. Evitando vazamento de dados
O vazamento de dados é sorrateiro e uma das maneiras mais rápidas de arruinar um Modelo de aprendizado de máquina. Acontece quando o modelo aprende algo ao qual não teria acesso em uma situação do mundo real-quendo.
As causas comuns incluem o uso de rótulos de destino na engenharia de recursos ou permitir que dados futuros influenciem as previsões atuais. A chave é sempre pensar em quais informações seu modelo teria realisticamente no tempo de previsão e mantê -las limitadas a isso.
3. Rastreie cada etapa
À medida que você passa pelo seu pipeline de pré -processamento, lidar com valores ausentes, codificando variáveis, escalando recursos e acompanhar suas ações são essenciais não apenas para sua própria memória, mas também para a reprodutibilidade.
A documentação de cada etapa garante que outras pessoas (ou futuro você) possam refazer seu caminho. Ferramentas como DVC (controle da versão de dados) ou um simples Pocket book Jupyter com anotações claras pode facilitar isso. Esse tipo de rastreamento também ajuda quando seu modelo tem um desempenho inesperado – você pode voltar e descobrir o que deu errado.
Exemplos do mundo actual
Para ver quanto de uma diferença o pré -processamento faz, considere um Estudo de caso envolvendo previsão de rotatividade de clientes em uma empresa de telecomunicações. Inicialmente, seu conjunto de dados bruto incluía valores ausentes, formatos inconsistentes e recursos redundantes. O primeiro modelo treinado nesses dados confusos quase atingiu 65% de precisão.
Depois de aplicar o pré -processamento adequado, imputando valores ausentes, codificando variáveis categóricas, normalizando recursos numéricos e removendo colunas irrelevantes, a precisão aumentou para mais de 80%. A transformação não estava no algoritmo, mas na qualidade dos dados.
Outro ótimo exemplo vem da assistência médica. Uma equipe trabalhando em Prevendo doenças cardíacas
usou um conjunto de dados público que incluía tipos de dados mistos e campos ausentes.
Eles aplicaram binning a faixas etárias, manipularam outliers usando o RobustScaler e um único codificou várias variáveis categóricas. Após o pré -processamento, a precisão do modelo melhorou de 72% para 87%, provando que você prepara seus dados geralmente importa mais do que o algoritmo que você escolher.
Em suma, o pré -processamento é a base de qualquer projeto de aprendizado de máquina. Siga as melhores práticas, mantenha as coisas transparentes e não subestime seu impacto. Quando bem feito, pode levar seu modelo de média para excepcional.
Perguntas frequentes (perguntas frequentes)
1. O pré -processamento é diferente para o aprendizado profundo?
Sim, mas apenas um pouco. Aprendizado profundo Ainda precisa de dados limpos, apenas menos recursos manuais.
2. Quanto pré -processamento é demais?
Se remover padrões significativos ou prejudicar a precisão do modelo, você provavelmente o exagerou.
3. O pré -processamento pode ser ignorado com dados suficientes?
Não. Mais dados ajudam, mas a entrada de baixa qualidade ainda leva a maus resultados.
3. Todos os modelos precisam do mesmo pré -processamento?
Não. Cada algoritmo tem sensibilidades diferentes. O que funciona para um pode não se adequar a outro.
4. A normalização é sempre necessária?
Principalmente, sim. Especialmente para algoritmos baseados em distância como KNN ou SVMS.
5. Você pode automatizar completamente o pré -processamento?
Não inteiramente. As ferramentas ajudam, mas o julgamento humano ainda é necessário para o contexto e a validação.
Por que rastrear etapas de pré -processamento?
Ele garante a reprodutibilidade e ajuda a identificar o que está melhorando ou prejudicando o desempenho.
Conclusão
O pré -processamento de dados não é apenas uma etapa preliminar, e é a base de um bom aprendizado de máquina. Dados limpos e consistentes levam a modelos que não são apenas precisos, mas também confiáveis. Desde a remoção de duplicatas até a escolha da codificação adequada, cada etapa é importante. Pular ou manipular pré -processamento geralmente leva a resultados barulhentos ou a idéias enganosas.
E à medida que os desafios de dados evoluem, uma sólida compreensão da teoria e das ferramentas se torna ainda mais valiosa. Muitos caminhos de aprendizado prático hoje, como os encontrados em ciência de dados abrangente
Se você deseja construir habilidades fortes e de ciência de dados do mundo actual, incluindo experiência prática com técnicas de pré-processamento, considere explorar o Grasp Information Science & Machine Studying in Python programa de grande aprendizado. Ele foi projetado para preencher a lacuna entre teoria e prática, ajudando você a aplicar esses conceitos com confiança em projetos reais.