Desde que os primeiros casos de Apache Kafka andavam na Terra há muitas luas, eles foram ligados a uma peça central da tecnologia subjacente que period basic para operações distribuídas: Apache Zookeeper. Com o lançamento de hoje da plataforma Confluent 8.0, a empresa por trás da Kafka excisou oficialmente o Zookeeper da period Hadoop de sua plataforma de streaming em tempo actual da empresa, que será um growth para simplicidade e eficiência.
O esforço para remover o Zookeeper do Apache Kafka já está em andamento há algum tempo. Quatro anos atrás, Confluente O CEO Jay Kreps falou sobre o quanto period importante no Apache Kafka versão 2.8 para substituir o Zookeeper por algo chamado Kraft, que é uma combinação do algoritmo de consenso da balsa e do log Kafka.
“É preciso toda a duplicação entre Kafka e Zookeeper, os quais mantinham um tronco e o fato de terem duas camadas de rede, dois modelos de segurança, dois sistemas de monitoramento, duas maneiras de correr e configurar cada um deles, e isso chega a apenas um” Kreps disse durante a Kafka Summit Europe em maio de 2021.
As empresas intrépidas poderiam executar o próprio código aberto Apache Kafka no modo Kraft, se quisessem desde que o Apache Kafka versão 2.8, mas levaria mais quatro anos para que o Confluent oferecesse uma versão sem zookeeper da plataforma confluente, a versão corporativa da Kafka para os clientes que desejam executar sua própria plataforma de dados em tempo actual em nuvem ou na nuvem.
O Confluent finalmente substituiu o Apache Zookeeper pelo seu modo Kraft na plataforma confluente 8.0 (imagem cortesia de confluência)
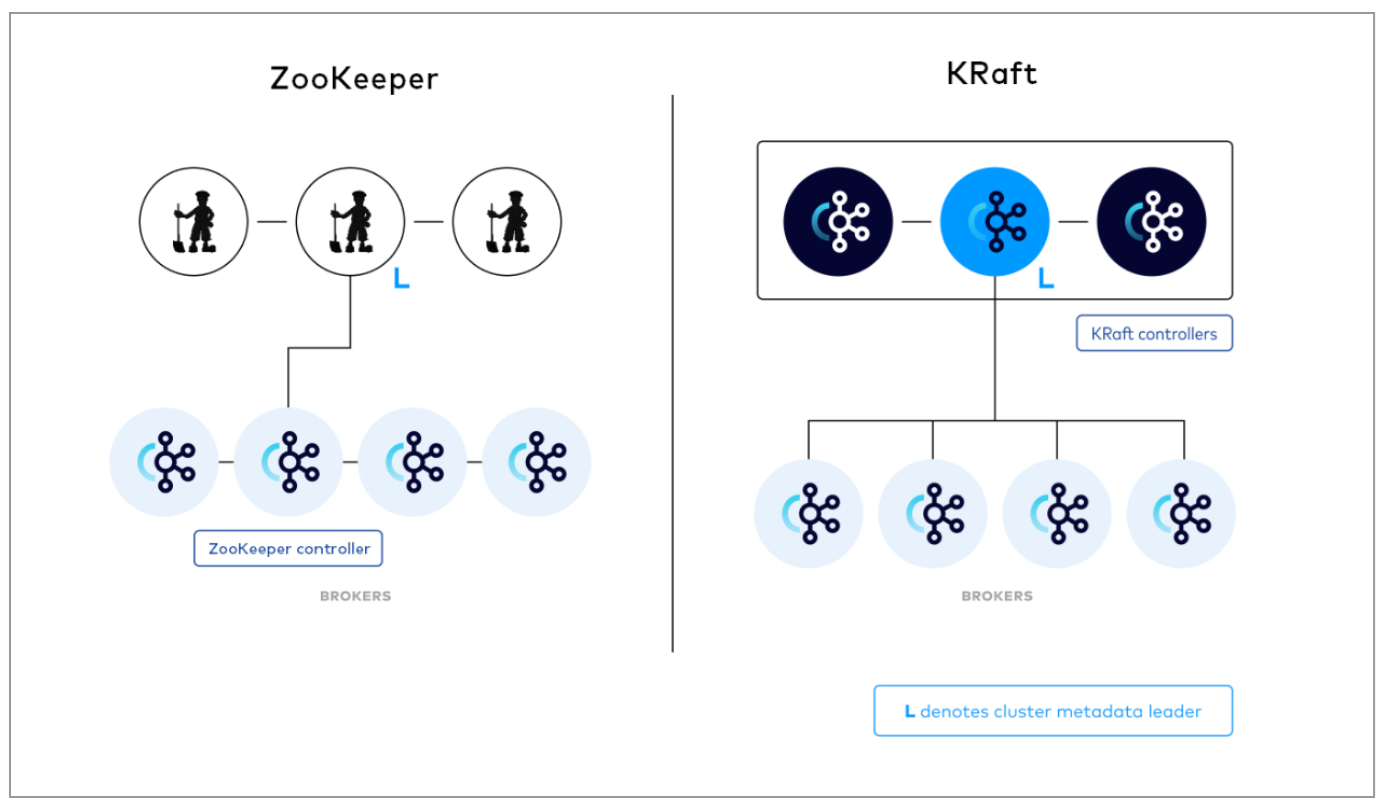
Esse dia finalmente chegou hoje com o lançamento da plataforma confluente 8.0. O Confluent diz que a remoção do Zookeeper na plataforma confluente 8.0 “marca um grande passo adiante na simplificação da arquitetura de Kafka e desbloqueando novos níveis de escalabilidade e resiliência.
“Com a disponibilidade geral do modo Kraft, a Kafka agora lida internamente em sua própria gestão de metadados, eliminando a necessidade de um sistema separado com suas próprias ferramentas, sintaxe e sobrecarga operacional”, diz a empresa. “Esse racionalização permite que as equipes implantem e operem Kafka com menos peças móveis, recuperação mais rápida dos failover e um modelo de configuração e segurança unificado em toda a plataforma”.
A disponibilidade do modo Kraft também traz um benefício de escalabilidade. Segundo o Confluent, os clientes agora podem executar clusters com milhões de partições. Ter tantas partições será um benefício para os clientes da Kafka, que agora podem abrir mais faixas de dados em tempo actual que são restritas a determinados clientes ou determinados tópicos.
Anteriormente, a regra geral sustentava que o número máximo de partições que um único cluster Kafka poderia lidar period de 200.000 partições, espalhadas por um certo número de tópicos, de acordo com este publish Por Knowledge Knowledge Streamhouse da empresa de dados de streaming baseada em Kafka. O pessoal em NetAppque executa um serviço de streaming de dados baseado em Kafka graças à sua aquisição de Instacluste 2022, diz o número máximo de partições que eles poderiam aperte de um único kafka O cluster foi de 80.000 sob o Zookeeper. Com o Kraft, esse número subiu para 1,9 milhão, de acordo com o NetApp. “Mais partições permitem maior concorrência do consumidor de Kafka e, portanto, maior taxa de transferência para clusters de Kafka”, escreveu NetApp.
Com o modo Kraft agora ativado por padrão, o failover do controlador de metadados agora está quase quase instante, diz Confluent, o que reduzirá o tempo de inatividade e melhorará a confiabilidade operacional.
“Para arquitetos e operadores, isso significa desempenho mais rápido, atualizações mais fáceis e uma base construída para o crescimento a longo prazo, sem a complexidade de gerenciar o Zookeeper”, escreveu Olivia Greene, gerente de advertising and marketing de produtos sênior com confluente, e Rohit Bakhshi, diretor de administração de produtos confluentes, Nesta postagem do weblog.
Greene e Bakhshi também elogiaram o recente lançamento de uma nova versão do Confluent Management Heart, que os clientes usam para controlar clusters de plataforma confluentes. A empresa diz que a mudança para uma arquitetura baseada em Prometheus trará grandes aprimoramentos de escalabilidade. O Centro de Controle também adotou o padrão de telemeterismo aberto (OTEL) para a coleta de dados, que eliminará a necessidade de um cluster separado para abrigar dados de observabilidade.
Finalmente, esta versão traz um grande impulso de segurança com a disponibilidade geral de criptografia de nível de campo do lado do cliente. O CSFLE complementa outros recursos de segurança já suportados na plataforma confluente, como a criptografia do lado do servidor da camada de transporte (RBAC) com outra camada de proteção.
“Para organizações de indústrias regulamentadas, como serviços financeiros, assistência médica e setor público, geralmente é necessário uma proteção de dados ainda mais rígida, especialmente para informações confidenciais, como informações de identificação pessoal (PII)”, escrevem Greene e Bakhshi. “O CSFLE permite criptografar campos individuais dentro das mensagens do lado do produtor, garantindo que apenas usuários ou aplicativos autorizados possam descriptografar e acessar dados.”
Outros novos recursos confluentes estão falando no novo lançamento incluem:
- Remoção da compatibilidade para clientes herdados no Apache Kafka 4.0, no qual a plataforma confluente 8.0 é construída;
- Visualização aberta do FlinkSQL para analisar dados históricos e em tempo actual usando o Apache Flink;
- Acesso antecipado para filas, um novo modelo de consumo que permite que vários consumidores compartilhem partições, processem mensagens de forma independente e rastreie a entrega para cargas de trabalho no estilo de fila;
- Capacidade de implantar o Centro de Controle usando o Plano de Controle Confluente para Kubernetes (CFK);
- Suporte para as versões principais do Ansible 2.11 com Ansible confluente;
- Um compromisso de seguir o ciclo de lançamento do Apache Kafka mais de perto com a versão comunitária da plataforma confluente.
O Confluent sediará um webinar em 8 de agosto para falar sobre os novos recursos na plataforma confluente 8.0. Você pode se registrar aqui.
Itens relacionados:
O confluente unifica o lote e o fluxo para alimentação de IA em escala