O Centro de Operações da Cisco Stay Community (NOC) implantou consultas e segurança do Serviço de Nome de Domínio da Cisco (DNS). A equipe do Centro de Operações de Segurança (SOC) integrou os logs do DNS na Splunk Enterprise Safety e Cisco XDR.
Para proteger os participantes da Cisco Stay na rede, o perfil de segurança padrão foi ativado, para bloquear consultas para domínios conhecidos de malware, comando e controle, phishing, tunelamento de DNS e criptografia. Há ocasiões em que uma pessoa precisa ir a um domínio bloqueado, uma demonstração ao vivo ou sessão de treinamento.

Durante a conferência da Cisco Stay San Diego 2025, e Outras conferências Trabalhamos no passado, vimos nomes de domínio que são de duas a três palavras em uma ordem aleatória como “alphabladeConnect (.) com”Como exemplo. Esses domínios estão ligados a uma campanha de phishing e às vezes ainda não são identificados como maliciosos.
Ivan Berlinson, nosso engenheiro de integração principal, criou Fluxos de trabalho de automação XDR Com o Splunk para identificar os principais domínios vistos nas últimas seis e 24 horas dos troncos DNS da Umbrella, pois isso pode ser usado para alertar a uma infecção ou campanha. Percebemos que os domínios que se seguiram ao padrão de três nomes aleatórios começaram a aparecer, como 23 consultas para ShotGunchancecruel (.) COM em 24 horas.
Isso me fez pensar: “Poderíamos pegar esses domínios usando o código e, com nosso esforço para usar a IA, poderíamos aproveitar a IA para encontrá -los para nós?”
A resposta é “sim”, mas com advertências e um pouco de ajuste. Para tornar isso possível, primeiro precisava descobrir as categorias de dados que eu queria. Antes que os domínios sejam marcados como maliciosos, eles geralmente são categorizados como comprasAssim, anúnciosAssim, comércioou sem categoria.
Comecei a executar um pequeno LLM no meu Mac e conversando com ele para determinar se a funcionalidade que eu quero está lá. Eu disse aos requisitos de precisar ser duas ou três palavras aleatórias e me dizer se acha que é um domínio de phishing. Dei alguns domínios que já sabíamos que eram maliciosos e foi capaz de dizer que eles estavam pitando de acordo com meus critérios. Isso period tudo que eu precisava para começar a codificar.
Fiz um script para puxar os domínios permitidos da Umbrella, criar um conjunto desdobado dos domínios e, em seguida, enviá-lo ao LLM para processá-los com um immediate inicial sendo o que eu disse anteriormente. Isso não funcionou muito bem para mim, já que period um modelo menor. Eu o dominei com a quantidade de dados e rapidamente o quebrei. Começou a retornar respostas que não faziam sentido e idiomas diferentes.
Eu mudei rapidamente o comportamento de como enviei os domínios. Comecei a enviar domínios em pedaços de 10 de cada vez, depois cheguei até 50 de cada vez, pois isso parecia ser o máximo antes que eu pensasse que se tornaria não confiável em seu comportamento.
Durante esse processo, notei variações em suas respostas aos dados. Isso ocorre porque eu estava dando o immediate inicial que eu criei toda vez que enviava um novo pedaço de domínios, e isso interpretaria esse aviso de maneira diferente a cada vez. Isso me levou a modificar o modelo modelfile. Este arquivo é usado como a raiz de como o modelo se comportará. Pode ser modificado para alterar a forma como um modelo responderá, analisará dados e será construído. Comecei a modificar esse arquivo de um assistente de propósito geral, útil, para ser um assistente do SOC, com atenção aos detalhes e responder apenas no JSON.
Isso foi ótimo, porque agora estava respondendo constantemente a como eu queria, mas havia muitos falsos positivos. Eu estava recebendo uma taxa de 15 a 20% de falso positivo (FP). Isso não foi aceitável para mim, pois eu gosto de ter alertas de alta fidelidade e menos pesquisas quando um alerta entra.
Aqui está um exemplo da taxa de FP para 50 neste momento e, muitas vezes, foi muito maior:
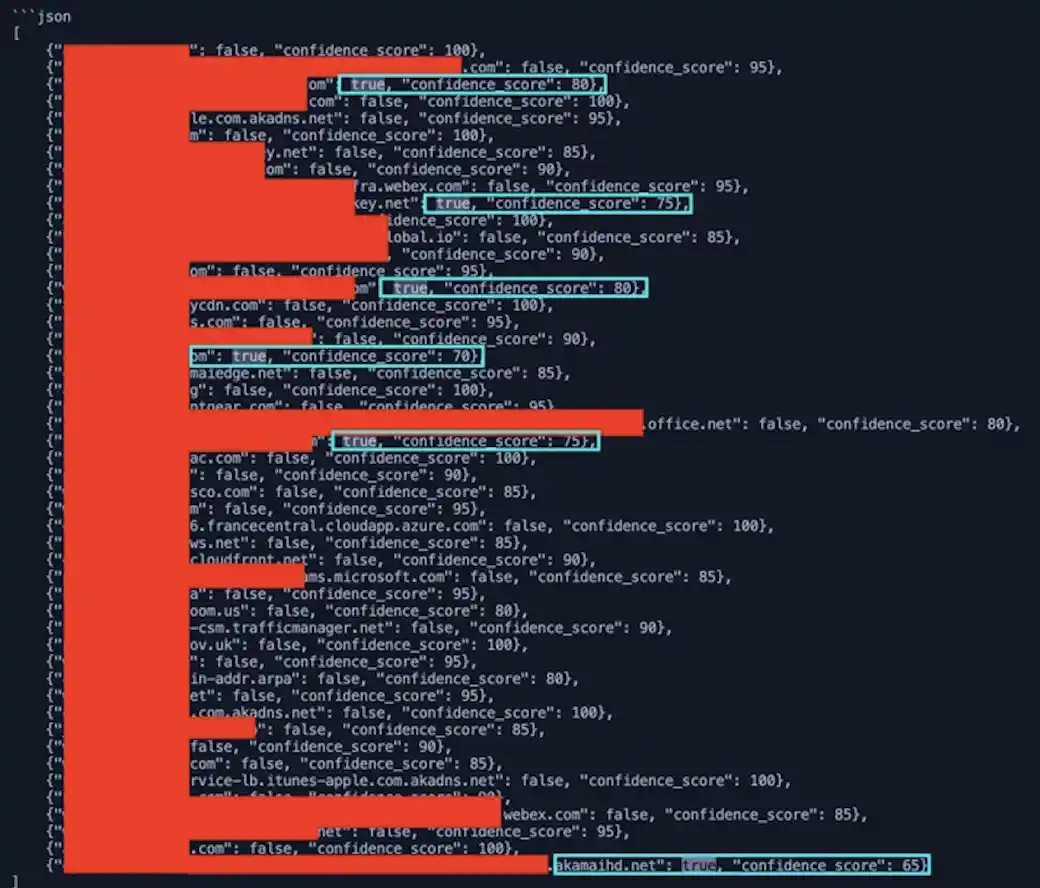
Comecei a ajustar o modelfile Para dizer ao modelo para me dar uma pontuação de confiança também. Agora eu period capaz de ver como estava confiante em sua determinação. Eu estava recebendo uma tonelada de 100% em domínios para a AWS, CDNs e similares. Ajustando o modelfile deve consertar isso. Eu atualizei o modelfile para ser mais específico em sua análise. Eu adicionei que não deveria haver delimitadores, como um ponto ou traço entre as palavras. E eu dei amostras negativas e positivas que ele poderia usar como exemplos ao analisar os domínios alimentados a ele.
Isso fez maravilhas. Passamos de uma taxa de FP de 15 a 20% para cerca de 10%. 10% é muito melhor do que antes, mas ainda são 100 domínios em 1000 que podem precisar verificar. Eu tentei modificar o modelfile Mais para ver se eu poderia reduzir a taxa de FP, mas sem sucesso. Troquei para um modelo mais recente e consegui reduzir a taxa de FP para 7%. Isso mostra que o modelo com o qual você começa nem sempre será o modelo com o qual você acaba ou atenderá às suas necessidades.
Nesse ponto, fiquei bastante feliz com isso, mas idealmente gostaria de reduzir ainda mais a taxa de FP. Mas com os recursos atuais do modelo, ele foi capaz de identificar com êxito domínios de phishing que não foram marcados como maliciosos e os adicionamos à nossa lista de blocos. Mais tarde, eles foram atualizados em guarda -chuva para serem maliciosos.
Foi um ótimo feito para mim, mas eu precisava ir mais longe. Eu trabalhei com CLASEN CRISTÁRIOnosso especialista em guarda -chuva/acesso seguro e conseguiu obter uma série de domínios associados à campanha de phishing e eu selecionei um conjunto de treinamento para ajustar um modelo.
Essa tarefa provou ser mais desafiadora do que eu pensava, e não consegui ajustar um modelo antes do término do evento. Mas essa pesquisa ainda está em andamento em preparação para Black Hat EUA 2025.
Adoraríamos ouvir o que você pensa! Faça uma pergunta e mantenha -se conectado à segurança da Cisco nas mídias sociais.
Cisco Safety Social Media
Compartilhar: