Desbloquear recursos poderosos de pesquisa para milhões de itens devem ser rápidos, precisos e sem esforço, mantendo alta relevância. Os bancos de dados relacionais são um método de armazenamento well-liked para dados estruturados, e as organizações os usam extensivamente para armazenar suas principais informações comerciais. Embora os bancos de dados relacionais se destacem em armazenar e recuperar dados estruturados, eles geralmente lutam para pesquisar em grandes blocos de texto não estruturado e, por razões de desempenho, normalmente não indexam todas as colunas.
Por outro lado, mecanismos de pesquisa como o OpenEarch Index todos os campos, permitindo recursos de pesquisa ricos, incluindo pesquisa semântica e agregações poderosas para resumir e analisar dados numéricos. Tradicionalmente, as organizações gerenciavam processos de sincronização de dados complexos, ineficientes e caros, incluindo pipelines de extração, transformação e carga (ETL), para manter seus índices de pesquisa atualizados com seus bancos de dados. Aqueles que desejam aprimorar seus aplicativos com recursos avançados de pesquisa precisam de uma solução mais simples que possa manter a sincronização do índice de pesquisa com seus bancos de dados sem a sobrecarga de gerenciar processos de sincronização de dados personalizados.
Temos o prazer de anunciar a disponibilidade geral da integração do Amazon OpenEarch Service com Amazon Relational Database Service (Amazon RDS) e Amazon Aurora. This new integration eliminates advanced knowledge pipelines and permits close to real-time knowledge synchronization between Amazon Aurora (together with Amazon Aurora MySQL-Suitable Version and Amazon Aurora PostgreSQL-Suitable Version) and Amazon RDS databases (together with Amazon RDS for MySQL and Amazon RDS for PostgreSQL), and Amazon OpenSearch Servicedesbloqueando recursos avançados de pesquisa, como pesquisa híbrida, resultados classificados e pesquisa facetada em bancos de dados transacionais. Agora você pode fornecer resultados de pesquisa de baixa latência e alto rendimento, atualizações de inventário ao vivo e recomendações personalizadas, enquanto se concentra na criação de experiências excepcionais do cliente, em vez de gerenciar a sincronização de dados. Essa integração reduz o ônus operacional de manter pipelines ETL complexos, reduzindo os custos e fornecendo disponibilidade de dados instantâneos para operações de pesquisa.
A Amazon OpenEarch Ingestion fornece sincronização de dados quase em tempo actual entre o Amazon Aurora ou o Amazon RDS e o OpenSearch Service. Selecione seu banco de dados Aurora ou RDS e a ingestão de pesquisa OpenSearch lida com o restante, apoiando Aurora MySQL ou RDS para MySQL (8.0 e acima) e Aurora PostgreSQL ou RDS para PostgreSql (16 e acima).
Visão geral da solução
Veja como esses serviços funcionam juntos:
- Ingestão de dados – A ingestão do OpenEarch primeiro carrega o seu banco de dados instantâneo de Amazon Easy Storage Service (Amazon S3), onde Aurora ou Amazon RDS exportaram os dados iniciais. Em seguida, ele usa os fluxos Aurora ou Amazon RDS Alterar Seize (CDC) para replicar alterações adicionais em tempo actual e os indexa no serviço OpenEarch. Esse processo automatizado mantém seus dados está atualizados constantemente no OpenSearch, tornando -os prontamente disponíveis para pesquisa e análise sem intervenção guide.
- Consulta em tempo actual – Serviço OpenEarch oferece poderosos Capacidades de consulta Isso permite que você understand pesquisas e agregações complexas em seus dados. Se você precisa analisar tendências, detectar anomalias ou executar consultas de pesquisa para retornar resultados relevantes para o seu aplicativo, o OpenSearch Service fornece as ferramentas necessárias.
O diagrama a seguir ilustra a arquitetura da solução para a Amazon Aurora como fonte:

Começando
Configurando sua fonte de banco de dados
Antes de configurar a sincronização, você precisa configurar as configurações de registro do banco de dados de origem. Para aurora mysql, configure seu grupo de parâmetros de cluster com configurações de log binárias aprimoradas. Para o Amazon RDS, ative o registro binário básico ou a replicação lógica através das configurações do grupo de parâmetros de instância. Esses configurações de registro Ative a ingestão do OpenEarch para capturar e replicar as alterações de dados do seu banco de dados.
O Exemplo de banco de dados de RH com aurora mysql é um bom exemplo para mostrar como essa integração funciona.
Antes de criar a visualização, agora explicamos como o OpenSearch representará esses dados. Mapeamentos OpenSearch Defina como os documentos e seus campos são armazenados e indexados, semelhante à forma como um esquema de banco de dados outline tabelas e colunas. O OpenEarch Ingestion Pipeline usa mapeamentos dinâmicos por padrão, convertendo automaticamente os tipos de dados Aurora ou Amazon RDS para apropriar os tipos de campos OpenEarch. Por exemplo, os campos de knowledge do banco de dados se tornam tipos de knowledge de pesquisa do Opensearch e os campos numéricos são mapeados para os tipos numéricos correspondentes do OpenEarch. Embora você possa personalizar esses mapeamentos usando modelos de índiceos mapeamentos padrão normalmente lidam com tipos de dados comuns corretamente, incluindo datas, números e campos de texto.
GET workers/_mapping
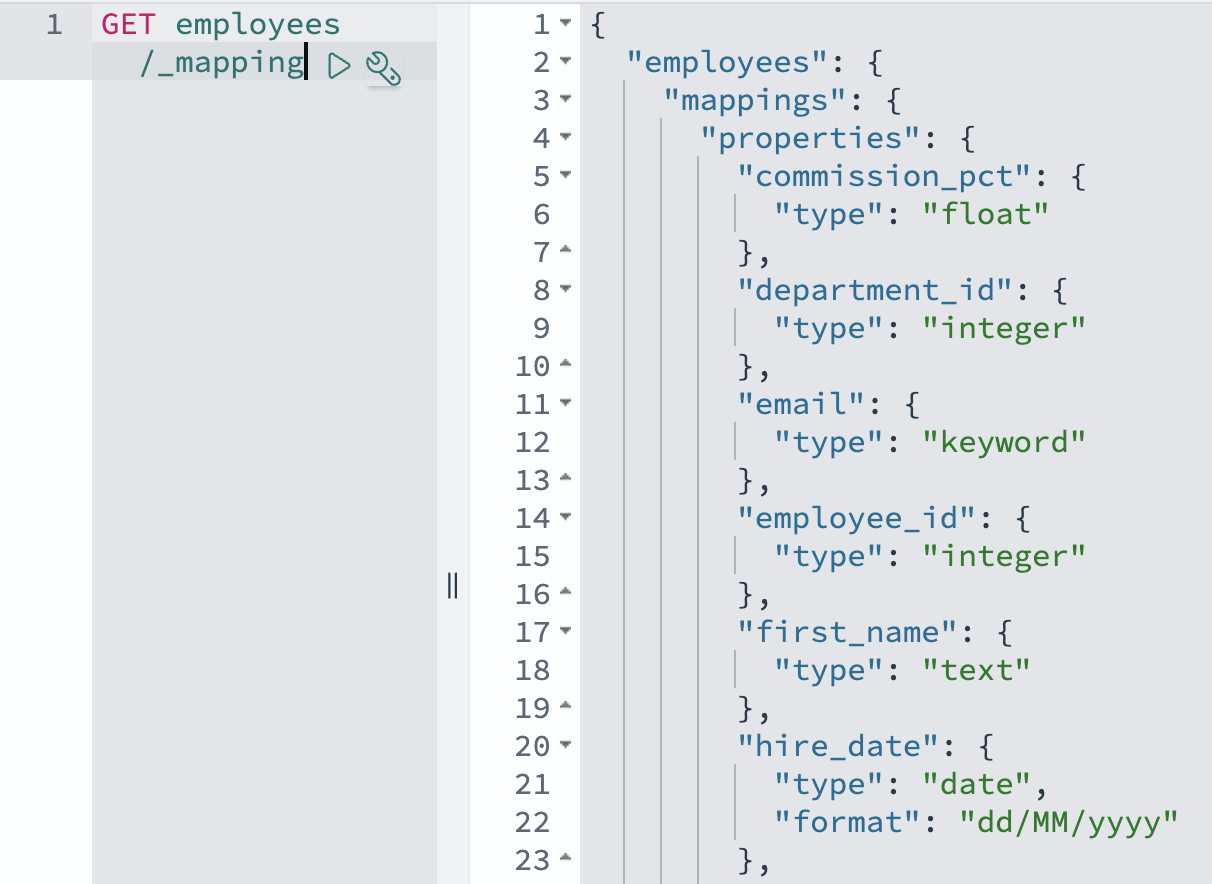
Para demonstrar a capacidade da integração de lidar com relacionamentos de dados complexos, agora examinamos como as lidades de ingestão do OpenEarch unidas. Criamos uma visualização no banco de dados de HR de amostra que combina informações de várias tabelas relacionadas em um único documento pesquisável no OpenEarch. Essa abordagem mostra como você pode transformar estruturas de banco de dados normalizadas em documentos desnormalizados que são otimizados para operações de pesquisa.
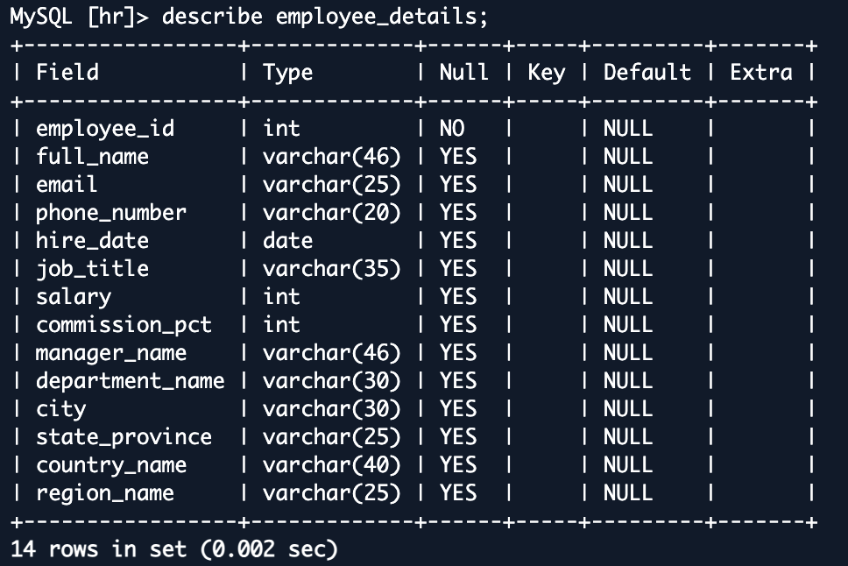
Esse employee_details A View combina dados de várias tabelas, criando uma representação rica e desnormalizada das informações dos funcionários. Quando replicado para o OpenSearch, essa visualização se torna um documento único e abrangente para cada funcionário. Essa estrutura é splendid para operações de pesquisa, permitindo consultas rápidas e complexas em todo o que eram tabelas originalmente separadas. Por exemplo, você pode procurar facilmente funcionários em um departamento e país específico ou analisar distribuições salariais em regiões – questões que seriam mais complexas e potencialmente mais lentas na estrutura de banco de dados normalizada authentic.
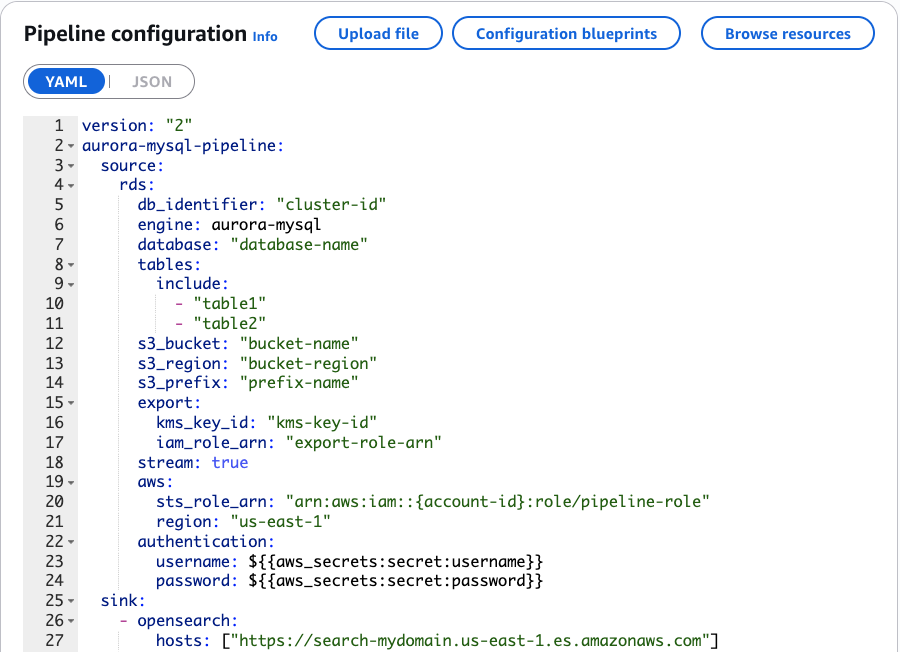
Na configuração do pipeline mostrada na captura de tela a seguir, você pode verificar como a ingestão do OpenSearch se conecta ao banco de dados de RH. A configuração identifica o banco de dados de origem e as tabelas específicas que queremos replicar. Enquanto criamos uma visão para entender os relacionamentos de dados, o pipeline rastreia as mudanças nas tabelas base subjacentes (funcionários, departamentos, locais e regiões). A ingestão do OpenEarch mantém automaticamente esses relacionamentos, o que significa que as alterações nessas tabelas são refletidas adequadamente no seu índice de pesquisa OpenSearch, mantendo os dados de pesquisa consistentes com o banco de dados de origem.
No GIF mostrado abaixo, você pode ver uma demonstração de configurar essa integração usando o editor visible da OpenEarch Ingestion.
Você também pode especificar modelos de mapeamento de índices para mapear seus campos Aurora ou Amazon RDS para os campos corretos nos seus índices de serviço do OpenEarch.
Para uma visão geral abrangente das definições de configuração para o pipeline, consulte o Documentação do OpenEarch Knowledge Prepper. Você deve configurar AWS Identification and Entry Administration (Iam) papéis para o pipeline. Para instruções, consulte Configure a função de pipeline.
Depois de configurar a integração na ingestão de opensearch, o pipeline cria automaticamente índices que você pode visualizar OpenEnsearch painéis. A ingestão do OpenEarch primeiro aciona uma exportação automática do seu banco de dados Aurora ou Amazon RDS para a Amazon S3 e, em seguida, carrega esses dados de instantâneos do S3 no seu cluster OpenSearch para criar os índices iniciais. Após essa carga inicial, a ingestão do OpenEarch captura continuamente as alterações usando logs binários (binlog) para bancos de dados baseados em MySQL ou logs-Forward WRITE (WAL) para bancos de dados baseados em PostgreSQL. Dessa forma, seus índices OpenEarch permanecem sincronizados com o seu banco de dados de origem quase em tempo actual. Você pode ver seus índices nos painéis do OpenEarch, invocando:
GET _cat/indices
Exemplo de resposta:

Demonstrando sincronização de dados quase em tempo actual
Considere as cinco primeiras entradas na tabela de funcionários:

Quando você faz alterações no seu banco de dados, o OpenSearch Ingestion Atualiza o Serviço de Amazon OpenEarch com os dados de alteração. Por exemplo, o código a seguir atualiza o salário de um funcionário:
UPDATE hr.workers SET SALARY = 26000 WHERE EMPLOYEE_ID = 100;

A Amazon Aurora envia um aviso de alteração, o seu pipeline de ingestão de opensearch o pega e a ingestão do OpenEarch envia o registro alterado para o OpenSearch em quase tempo actual. Você pode verificar isso com uma consulta OpenSearch:
GET workers/_search
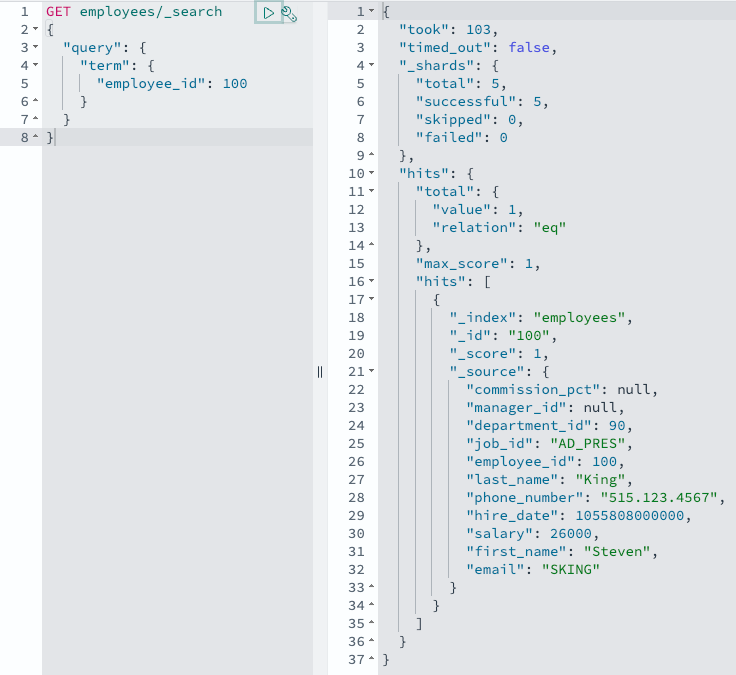
Detalhes importantes sobre esse recurso:
- Monitoramento – Acompanhe o desempenho do pipeline e a sincronização de dados por meio CloudWatch Métricas e o painel de ingestão do OpenEarch
- Limitações -Requer implantação da mesma região e da mesma conta, chaves primárias para a sincronização splendid e atualmente não possui suporte à instrução de linguagem de definição de dados (DDL)
Conclusão
A Amazon Aurora ou a integração do Amazon RDS com o Amazon OpenEarch Service agora está disponível em todas as regiões da AWS, onde a ingestão do OpenEarch está disponível.
Para saber mais, consulte a documentação da AWS para a integração Aurora ou Amazon RDS com o Amazon OpenSearch Service:
Sobre os autores
 Michael Torio é um arquiteto de soluções especializadas associadas da AWS focado no Amazon OpenEarch Service baseado em Mountain View, CA. Michael gosta de ajudar os clientes a aproveitar as tecnologias em nuvem para resolver seus desafios de negócios.
Michael Torio é um arquiteto de soluções especializadas associadas da AWS focado no Amazon OpenEarch Service baseado em Mountain View, CA. Michael gosta de ajudar os clientes a aproveitar as tecnologias em nuvem para resolver seus desafios de negócios.
 Sohaib Katariwala é um arquiteto de soluções especializadas sênior da AWS focado no Amazon OpenEarch Service baseado em Chicago, IL. Seus interesses são em todos os dados e análises. Mais especificamente, ele adora ajudar os clientes a usar a IA em sua estratégia de dados para resolver desafios modernos.
Sohaib Katariwala é um arquiteto de soluções especializadas sênior da AWS focado no Amazon OpenEarch Service baseado em Chicago, IL. Seus interesses são em todos os dados e análises. Mais especificamente, ele adora ajudar os clientes a usar a IA em sua estratégia de dados para resolver desafios modernos.
 Arjun Nambiar é um gerente de produto do Amazon OpenEarch Service. Ele se concentra nas tecnologias de ingestão que permitem a ingestão de dados de uma ampla variedade de fontes no serviço de opensearch da Amazon em escala. Arjun está interessado em sistemas distribuídos em larga escala e tecnologias centradas na nuvem, e é baseado em Seattle, Washington.
Arjun Nambiar é um gerente de produto do Amazon OpenEarch Service. Ele se concentra nas tecnologias de ingestão que permitem a ingestão de dados de uma ampla variedade de fontes no serviço de opensearch da Amazon em escala. Arjun está interessado em sistemas distribuídos em larga escala e tecnologias centradas na nuvem, e é baseado em Seattle, Washington.