À medida que as organizações adotam cada vez mais as mesas de iceberg do Apache para suas arquiteturas de knowledge lake em Amazon Net Companies (AWS), manter essas tabelas se torna essential para o sucesso a longo prazo. Sem manutenção adequada, as tabelas de iceberg podem enfrentar vários desafios: desempenho degradado da consulta, retenção desnecessária de dados antigos que devem ser removidos e um declínio na eficiência dos custos de armazenamento. Essas questões podem afetar significativamente a eficácia e a economia do seu Information Lake. As operações regulares de manutenção da tabela ajudam a garantir que suas tabelas de iceberg permaneçam com alto desempenho, compatíveis com políticas de retenção de dados e econômicas para cargas de trabalho de produção. Para ajudá -lo a gerenciar suas mesas de iceberg em escala, Aws cola Automatizou essas operações de manutenção de mesa de iceberg: compactação com classificar e ordem z e Expiração de instantâneos e gerenciamento de dados órfãos. Após o lançamento do recurso, muitos clientes permitiram a otimização de tabela automatizada por meio Catálogo de dados da AWS Glue para reduzir a carga operacional.
A Arquitetura de Lakehouse do Amazon Sagema agora automatiza agora Otimização de mesas de iceberg Armazenado na Amazon S3 com configuração no nível do catálogo, otimizando o armazenamento em suas mesas de iceberg e melhorando o desempenho da consulta. Anteriormente, otimizando as tabelas de iceberg no catálogo de dados da AWS Glue exigia a atualização de configurações para cada tabela individualmente. Agora, você pode ativar a otimização automática para novas tabelas de iceberg com a configuração única do catálogo de dados. Uma vez ativado, para qualquer nova tabela ou tabela atualizada, o catálogo de dados otimiza continuamente as tabelas compactando arquivos pequenos, removendo instantâneos e arquivos não referenciados que não são mais necessários.
Esta postagem demonstra um fluxo de ponta a ponta para ativar a configuração de otimização de tabela de nível do catálogo.
Pré -requisitos
Os seguintes pré-requisitos são obrigados a usar as novas otimizações de tabela no nível do catálogo:
Ativar otimizações de tabela no nível do catálogo
O administrador do Information Lake pode permitir a otimização da tabela no nível do catálogo no Formação do lago AWS console. Full as seguintes etapas:
- No console de formação do lago Aws, escolha Catálogos no painel de navegação.
- Selecione o catálogo a ser ativado com otimizações de tabela no nível do catálogo.
- Escolher Otimizações de tabela guia e escolha Editar em Otimizações de tabelacomo mostrado na captura de tela a seguir.

- Em Opções de otimizaçãoselecione CompactaçãoAssim, Retenção de instantâneose Exclusão de arquivos órfãoscomo mostrado na captura de tela a seguir.
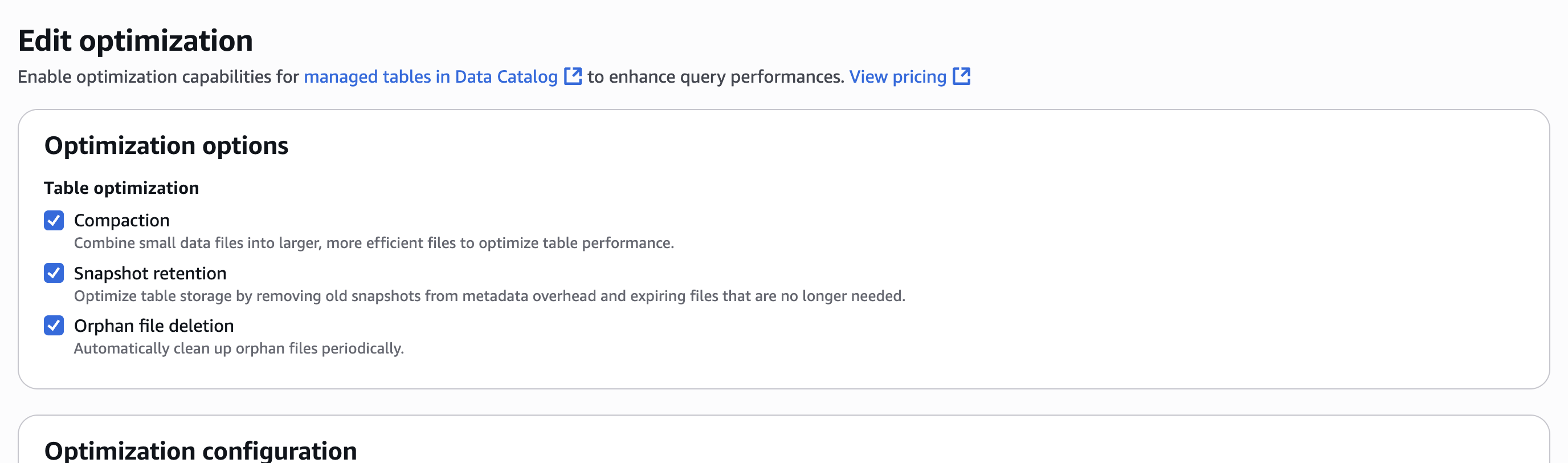
- Selecione um papel IAM. Consulte Pré -requisitos de otimização de tabela para permissões.
- Escolher Conceder permissões necessárias.
- Escolher Reconheço que os dados expirados serão excluídos como parte dos otimizadores.
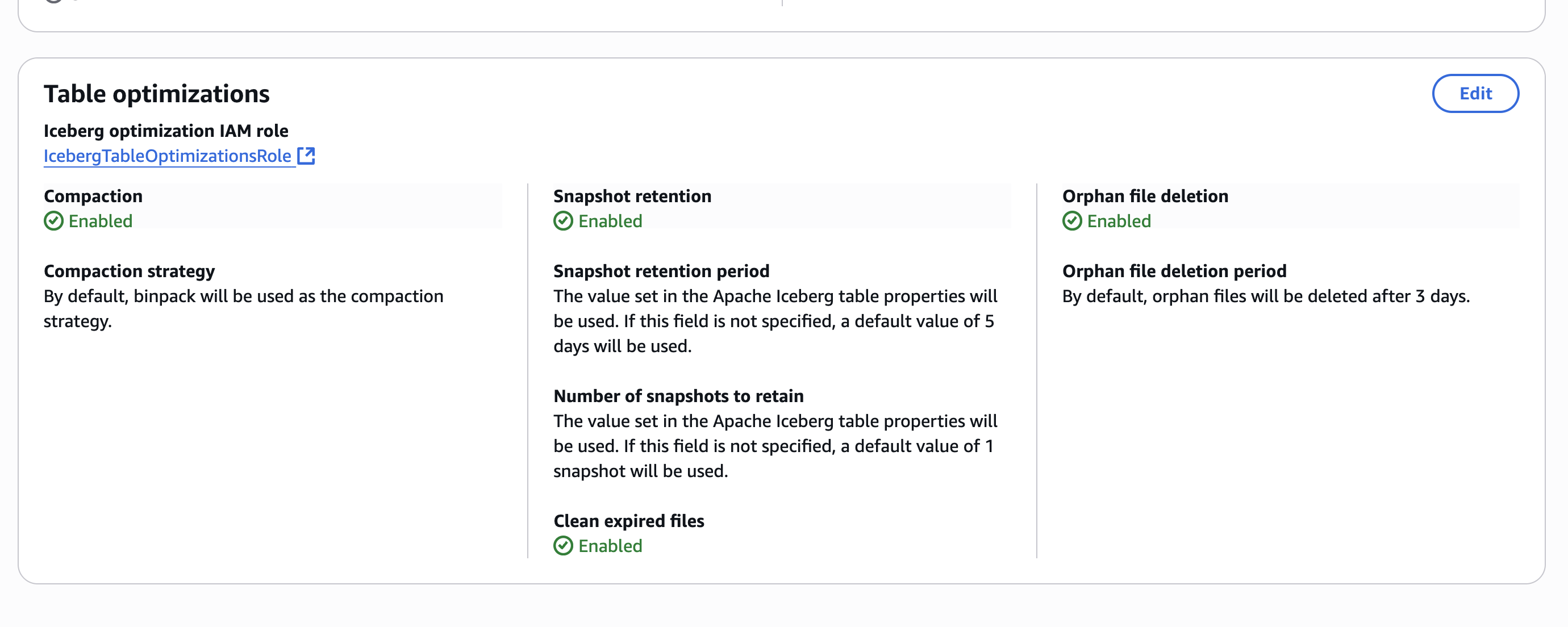
Depois de ativar as otimizações da tabela no nível do catálogo, a configuração é exibida no console de formação do lago AWS, como mostrado na captura de tela a seguir.
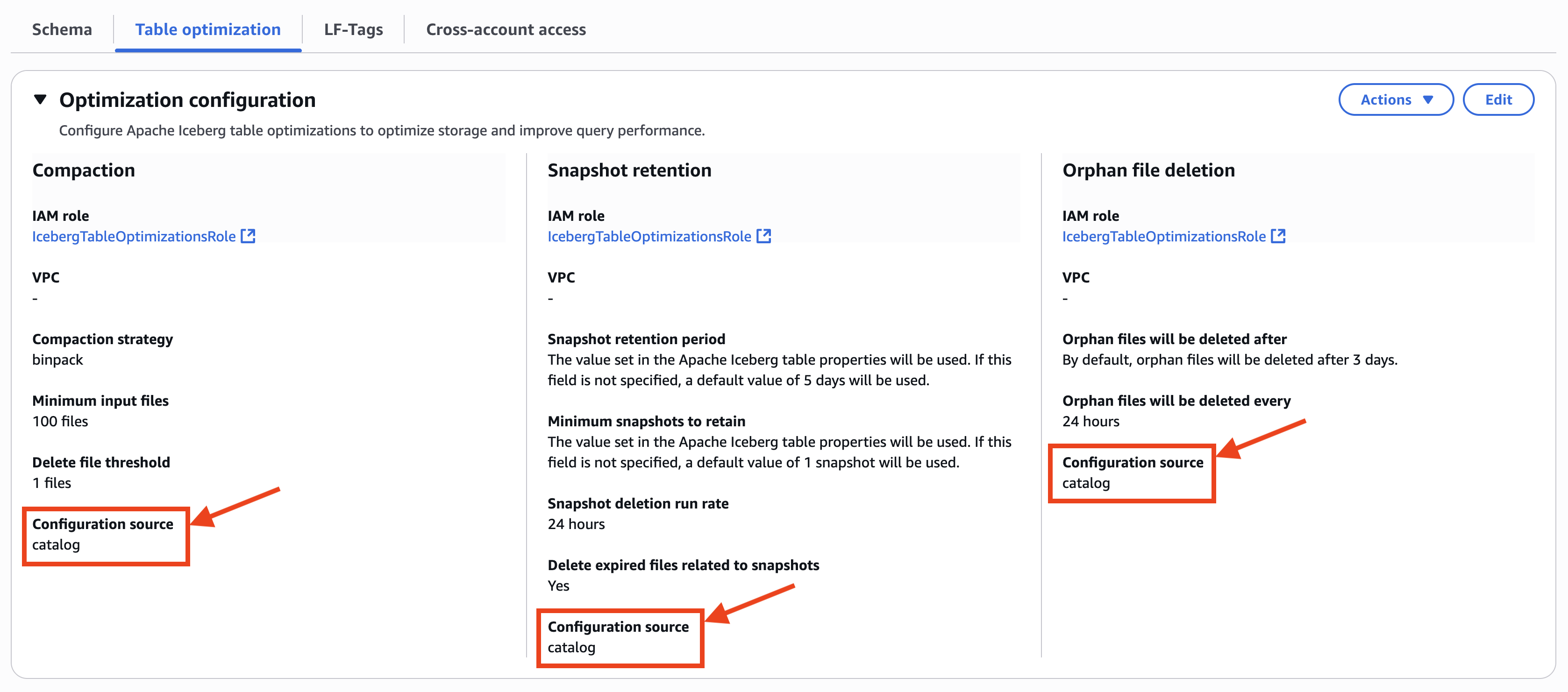
Quando você seleciona uma mesa de iceberg registrada no catálogo, você pode confirmar que a configuração de otimizações da tabela é herdada da visualização da tabela porque Fonte de configuração exhibits catálogocomo mostrado na captura de tela a seguir.
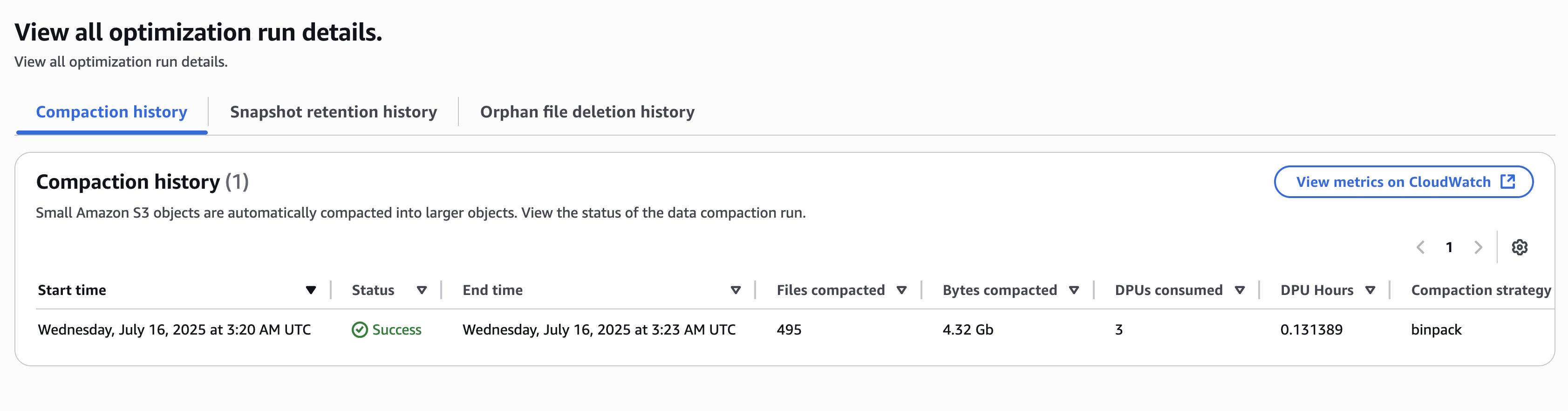
O histórico de otimizações da tabela é exibido na visualização da tabela. O resultado a seguir mostra uma das execuções de compactação pelas otimizações da tabela.
As otimizações de tabela no nível do catálogo para todos os bancos de dados e tabelas de iceberg estão agora ativados.
Personalize a configuração de otimizações de tabela no catálogo e no nível da mesa
Embora a otimização no nível do catálogo aplique configurações comuns em todos os bancos de dados e mesas de iceberg em seu catálogo, você pode aplicar estratégias diferentes para tabelas específicas de iceberg. Você pode usar o catálogo de dados da AWS Glue para ativar o otimizações no nível do catálogo e no nível da tabela com base em características específicas da tabela e padrões de acesso. Por exemplo, além de configurar a compactação no nível do catálogo com a estratégia de bin-pack para tabelas de iceberg de uso geral, você pode aplicar a estratégia de classificação no nível da mesa às tabelas com consultas frequentes de alcance em colunas de registro de knowledge e hora.
Esta seção mostra a configuração de otimizações de nível de catálogo e específicas da tabela por meio de um cenário prático. Think about uma tabela de análise em tempo actual com operações de gravação frequentes que gerem mais arquivos órfãos devido a atualizações de metadados constantes. Os usuários também executam consultas seletivas filtrando colunas específicas, o que torna a estratégia de ordem de classificação preferível. Full as seguintes etapas:
- Selecione outra tabela de iceberg no mesmo catálogo de antes para configurar as otimizações no nível da mesa no console de formação do lago AWS. Neste ponto, as otimizações de tabela no nível do catálogo são configuradas para esta tabela.
- Escolher Editar em Configuração de otimizaçãocomo mostrado na captura de tela a seguir.
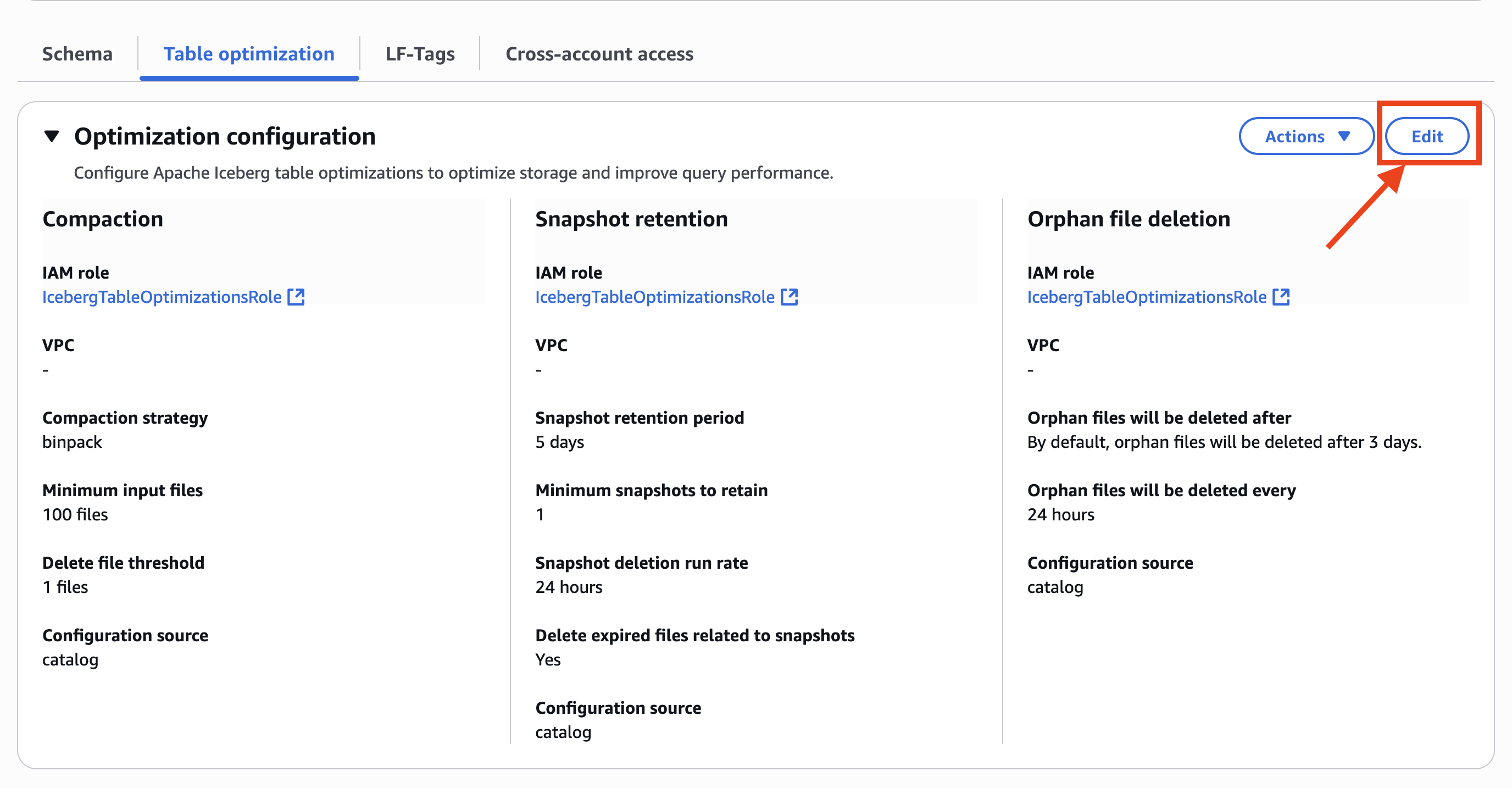
- Em Opções de otimizaçãoescolher CompactaçãoAssim, Retenção de instantâneose Exclusão de arquivos órfãos.
- Em Configuração de otimizaçãoescolher Personalize configurações.
- Selecione o mesmo papel do IAM.
- Em Configuração de compactaçãoselecione Organizarcomo mostrado na captura de tela a seguir. Também configure 80 arquivos para Arquivos de entrada mínimosque é um limite do número de arquivos para acionar a compactação. Para configurar Organizaruma ordem de classificação precisa ser definida em sua mesa de iceberg. Você pode definir a ordem de classificação com Spark SQL, como
ALTER TABLE db.tbl WRITE ORDERED BY.
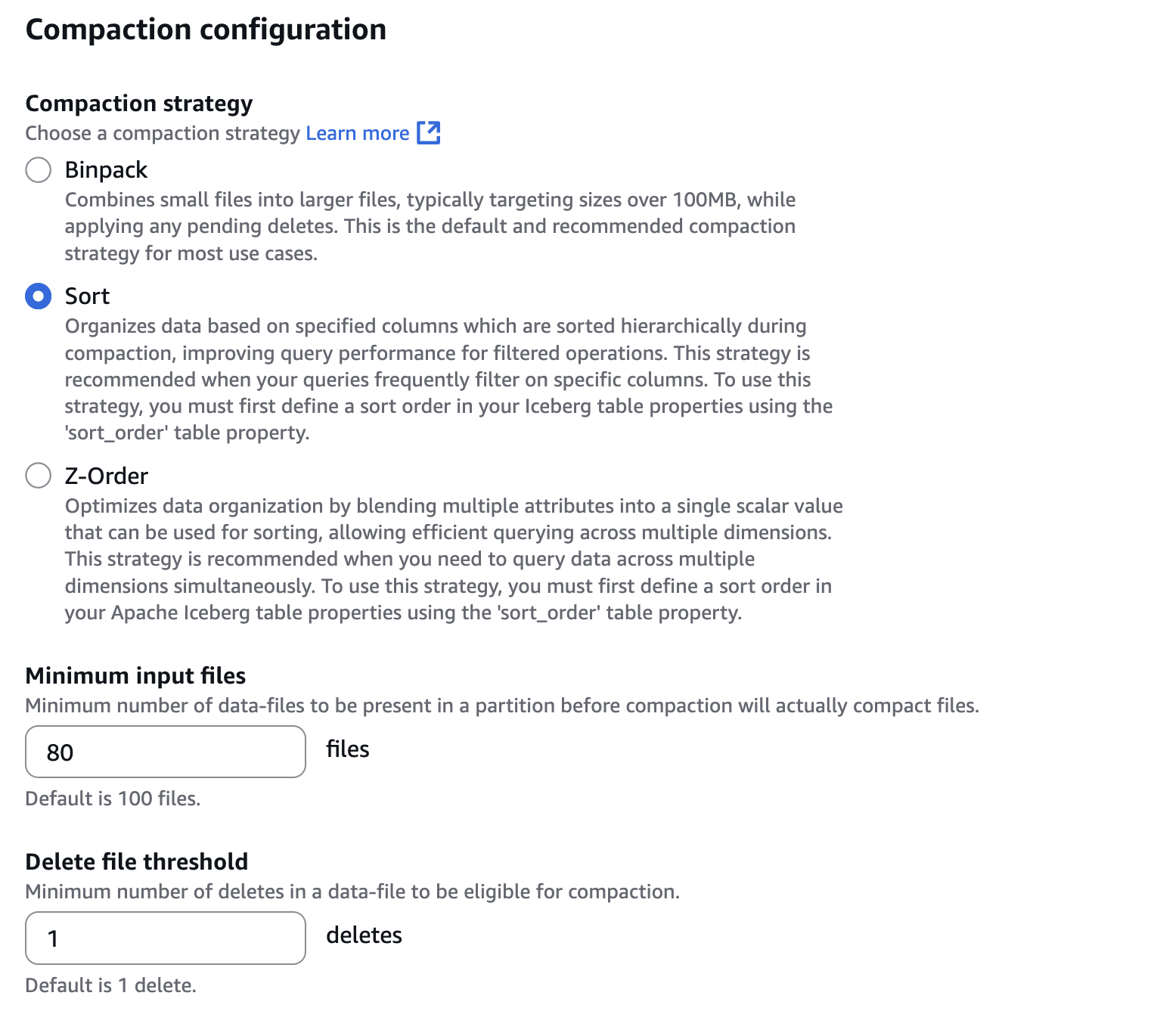
- Em Configuração de retenção de instantâneos e Taxa de execução de exclusão de instantâneosselecione Especifique um valor personalizado em horas. Em seguida, configure 12 horas para o intervalo entre dois trabalhos de exclusão, conforme mostrado na captura de tela a seguir.

- Em Configuração de exclusão de arquivos órfãosconfigure 1 dia para Os arquivos no native da tabela fornecidos com um tempo de criação mais antigos do que esse número de dias serão excluídos se não forem mais referenciados pelos metadados da tabela de iceberg do Apache.

- Escolher Conceder permissões necessárias.
- Escolher Reconheço que os dados expirados serão excluídos como parte dos otimizadores.
- Escolher Salvar.
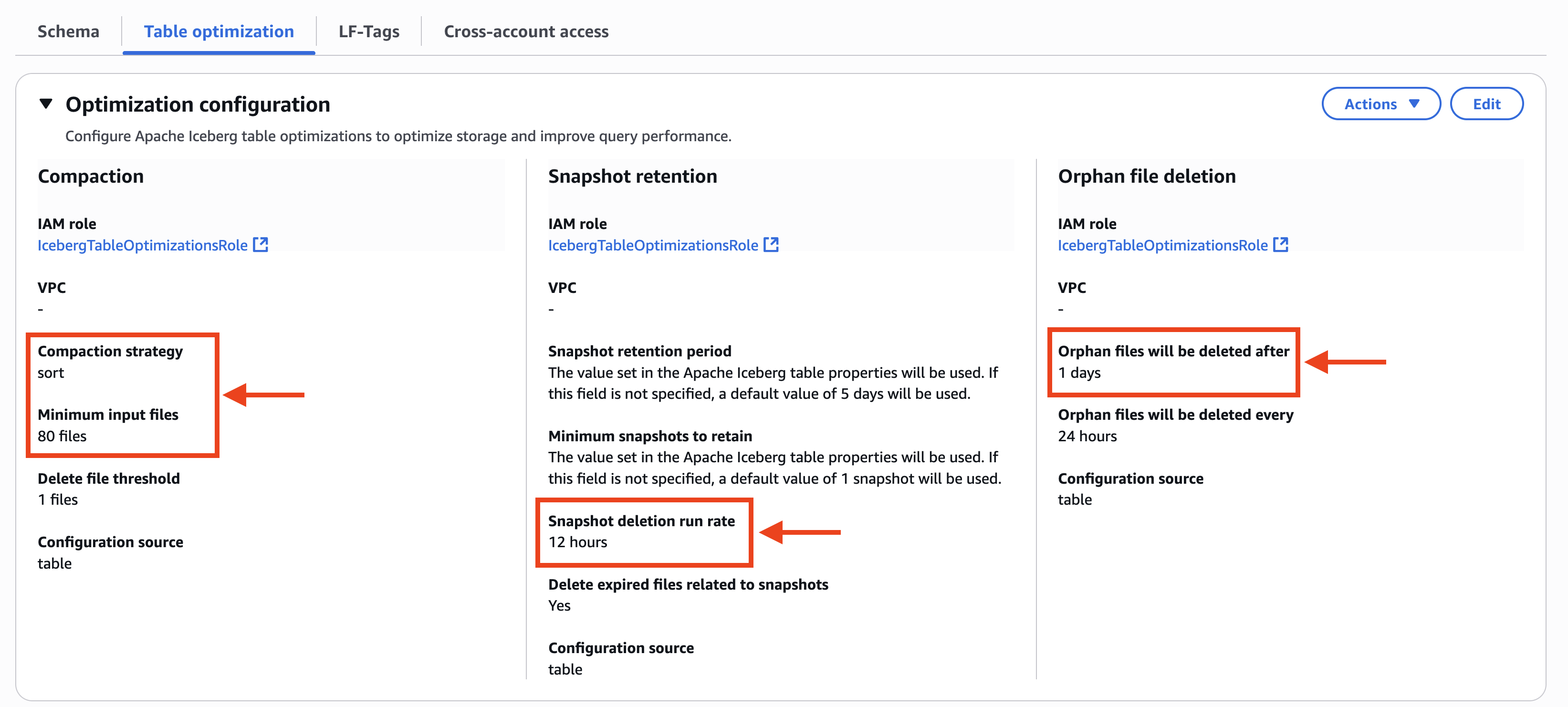
- O Otimização da tabela A guia no console de formação do AWS Lake exibe a configuração personalizada dos otimizadores de tabela. Em CompactaçãoAssim, Estratégia de compactação está configurado para organizar e Arquivos de entrada mínimos também está configurado para 80 arquivos. Em Retenção de instantâneosAssim, Taxa de execução de exclusão de instantâneos está configurado para 12 horas. Em Exclusão de arquivos órfãosAssim, Os arquivos órfãos serão excluídos depois está configurado para 1 diacomo mostrado na captura de tela a seguir.
O histórico de compactação mostra organizar como sua estratégia de compactação no nível da mesa, mesmo que a estratégia no nível do catálogo seja configurada para Binpack, como mostrado na captura de tela a seguir.
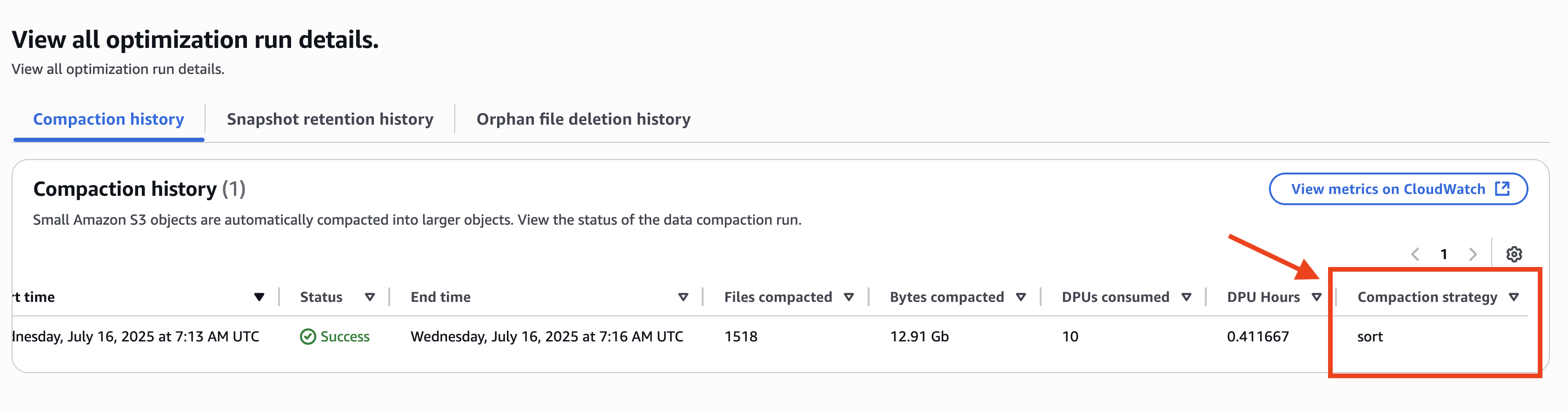
Nesse cenário, as otimizações específicas da tabela são configuradas junto com as otimizações no nível do catálogo. Combinar a tabela e otimizações no nível do catálogo significa que você pode gerenciar com mais flexibilidade as deleções e comções de dados da tabela de iceberg.
Conclusão
Nesta postagem, demonstramos como ativar e gerenciar o uso da arquitetura da Amazon Sagemaker Lakehouse com o recurso de otimização de tabela de dados do catálogo do catálogo da AWS Glue para tabelas de iceberg. Esse aprimoramento simplifica significativamente o gerenciamento de tabelas de iceberg porque você pode ativar operações de manutenção automatizadas em todas as tabelas com uma única configuração. Em vez de definir as configurações de otimização para tabelas individuais, agora você pode manter todo o seu Information Lake com mais eficiência, reduzindo a sobrecarga operacional e garantindo políticas de otimização consistentes. Recomendamos permitir a otimização da tabela no nível do catálogo para ajudá-lo a manter um knowledge Lake bem organizado, de alto desempenho e econômico, ao mesmo tempo em que libera suas equipes para se concentrar em obter valor de seus dados.
Experimente esse recurso para o seu próprio caso de uso e compartilhe seus comentários e perguntas nos comentários. Para saber mais sobre o otimizador de tabela de catálogo de dados da AWS Glue, visite Otimizando mesas de iceberg.
Reconhecimento: um agradecimento especial a todos que contribuíram para o desenvolvimento e o lançamento da otimização do nível do catálogo: Siddharth Padmanabhan Ramanarayanan, Dhrithi Chidananda, Noella Jiang, Sangeet Lohariwala, Shyam Rathi, Anuj Jigneshkumar Vakil, e Jeremy.
Sobre os autores
 Tomohiro Tanaka é um engenheiro sênior de suporte em nuvem na Amazon Net Companies (AWS). Ele é apaixonado por ajudar os clientes a usar o Apache Iceberg para seus lagos de dados na AWS. Em seu tempo livre, ele gosta de uma pausa para o café com seus colegas e fazer café em casa.
Tomohiro Tanaka é um engenheiro sênior de suporte em nuvem na Amazon Net Companies (AWS). Ele é apaixonado por ajudar os clientes a usar o Apache Iceberg para seus lagos de dados na AWS. Em seu tempo livre, ele gosta de uma pausa para o café com seus colegas e fazer café em casa.
 Noritaka Sekiyama é um principal arquiteto de large knowledge da AWS Analytics Companies. Ele é responsável pela construção de artefatos de software program para ajudar os clientes. Em seu tempo livre, ele gosta de andar de bicicleta em sua bicicleta de estrada.
Noritaka Sekiyama é um principal arquiteto de large knowledge da AWS Analytics Companies. Ele é responsável pela construção de artefatos de software program para ajudar os clientes. Em seu tempo livre, ele gosta de andar de bicicleta em sua bicicleta de estrada.
 Sandeep Adwankar é gerente sênior de produtos da Amazon Net Companies (AWS). Com sede na área da baía da Califórnia, ele trabalha com clientes em todo o mundo para traduzir requisitos de negócios e técnicos em produtos que os clientes podem usar para melhorar a maneira como gerenciam, protegem e acessa dados.
Sandeep Adwankar é gerente sênior de produtos da Amazon Net Companies (AWS). Com sede na área da baía da Califórnia, ele trabalha com clientes em todo o mundo para traduzir requisitos de negócios e técnicos em produtos que os clientes podem usar para melhorar a maneira como gerenciam, protegem e acessa dados.
 Siddharth Padmanabhan Ramanarayanan é um engenheiro sênior de software program na equipe da AWS Glue e da AWS Lake Formation, onde ele se concentra na criação de sistemas distribuídos escaláveis para cargas de trabalho de análise de dados. Ele é apaixonado por ajudar os clientes a otimizar sua infraestrutura em nuvem por desempenho e eficiência de custos.
Siddharth Padmanabhan Ramanarayanan é um engenheiro sênior de software program na equipe da AWS Glue e da AWS Lake Formation, onde ele se concentra na criação de sistemas distribuídos escaláveis para cargas de trabalho de análise de dados. Ele é apaixonado por ajudar os clientes a otimizar sua infraestrutura em nuvem por desempenho e eficiência de custos.