Os mecanismos de pesquisa como o Google Pictures, o Bing Visible Search e o Pinterest do Pinterest parecem muito fáceis quando digitamos algumas palavras ou carregamos uma imagem e, instantaneamente, recebemos as imagens semelhantes mais relevantes de bilhões de possibilidades.
Sob o capô, esses sistemas usam enormes pilhas de dados e modelos avançados de aprendizado profundo para transformar imagens e texto em vetores numéricos (chamados incorporação) que vivem no mesmo “espaço semântico”.
Neste artigo, construiremos um Mini versão Desse tipo de mecanismo de pesquisa, mas com um conjunto de dados de animais muito menor com imagens de tigres, leões, elefantes, zebras, girafas, pandas e pinguins.
Você pode seguir a mesma abordagem com outros conjuntos de dados como COCOAssim, Fotos Unsplashou mesmo sua coleção de imagens pessoais.
O que estamos construindo
Nosso mecanismo de pesquisa de imagens será:
- Usar Blip Para gerar automaticamente legendas (descrições) para cada imagem.
- Usar GRAMPO para converter imagens e texto em incorporação.
- Armazenar essas incorporações em um banco de dados vetorial (Chromadb).
- Permite que você pesquise Consulta de texto e recuperar as imagens mais relevantes.
Por que brilhar e clipe?
Blip (Pré-Trelainamento de Imagem da Linguagem de Bootstrapping)
O BLIP é um modelo de aprendizado profundo capaz de produzir descrições textuais para fotos (também conhecidas como legendas de imagem). Se nosso conjunto de dados ainda não tiver uma descrição, o Blip pode criar um olhando para uma imagem, como um tigre, e produzindo algo como “um grande gato laranja com listras pretas deitadas na grama”.
Isso ajuda especialmente onde:
- O conjunto de dados é apenas uma pasta de imagens sem rótulos atribuídos a eles.
- E se você quiser descrições generalizadas mais ricas e naturais para suas imagens.
Leia mais: Legenda de imagem usando aprendizado profundo
Clipe (Linguagem-Imagem Contrastiva Pré-Treinamento)
Clip, por Openai, aprende a se conectar texto e imagens dentro de um espaço vetorial compartilhado.
Pode:
- Converter uma imagem em uma incorporação.
- Converter texto em uma incorporação.
- Evaluate os dois diretamente; Se eles estão próximos neste espaço, significa que eles combinam semanticamente.
Exemplo:
- Texto: “Um animal alto com um pescoço longo” → Vector UM
- Imagem de uma girafa → vetor B
- Se vetores UM e B estão próximos, diz Clip, “Sim, isso provavelmente é uma girafa.”

Implementação passo a passo
Faremos tudo dentro Google Colab, Então você não precisa de nenhuma configuração native. Você pode acessar o caderno deste hyperlink: Incorpingding_similarity_animals
1. Instale dependências
Instalaremos Pytorch, Transformers (para BLIP e CLIP) e Chromadb (Vector Database). Estas são as principais dependências para o nosso mini projeto.
!pip set up transformers torch -q
!pip set up chromadb -q2. Faça o obtain do conjunto de dados
Para esta demonstração, usaremos o Conjunto de dados de animais de Kaggle.
import kagglehub
# Obtain the newest model
path = kagglehub.dataset_download("likhon148/animal-data")
print("Path to dataset recordsdata:", path)Mover para o /contente Diretório em Colab:
!mv /root/.cache/kagglehub/datasets/likhon148/animal-data/variations/1 /content material/Verifique quais aulas temos:
!ls -l /content material/1/animal_dataVocê verá pastas como:
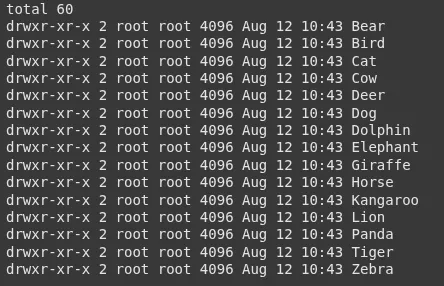
3. Conte imagens por classe
Apenas para ter uma idéia do nosso conjunto de dados.
import os
base_path = "/content material/1/animal_data"
for folder in sorted(os.listdir(base_path)):
folder_path = os.path.be part of(base_path, folder)
if os.path.isdir(folder_path):
depend = len((f for f in os.listdir(folder_path) if os.path.isfile(os.path.be part of(folder_path, f))))
print(f"{folder}: {depend} pictures")Saída:
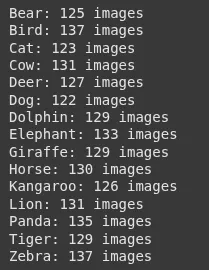
4. Modelo de clipe de carga
Usaremos clipe para incorporação.
from transformers import CLIPProcessor, CLIPModel
import torch
model_id = "openai/clip-vit-base-patch32"
processor = CLIPProcessor.from_pretrained(model_id)
mannequin = CLIPModel.from_pretrained(model_id)
system="cuda" if torch.cuda.is_available() else 'cpu'
mannequin.to(system)5. Modelo de Blip de carga para legenda de imagem
O BLIP criará uma legenda para cada imagem.
from transformers import BlipProcessor, BlipForConditionalGeneration
blip_model_id = "Salesforce/blip-image-captioning-base"
caption_processor = BlipProcessor.from_pretrained(blip_model_id)
caption_model = BlipForConditionalGeneration.from_pretrained(blip_model_id).to(system)6. Put together os caminhos da imagem
Reuniremos todos os caminhos da imagem do conjunto de dados.
image_paths = ()
for root, _, recordsdata in os.stroll(base_path):
for f in recordsdata:
if f.decrease().endswith((".jpg", ".jpeg", ".png", ".bmp", ".webp")):
image_paths.append(os.path.be part of(root, f))7. gerar descrições e incorporações
Para cada imagem:
- Blip gera uma descrição para essa imagem.
- GRAMPO Gera uma imagem incorporada com base nos pixels da imagem.
import pandas as pd
from PIL import Picture
information = ()
for img_path in image_paths:
picture = Picture.open(img_path).convert("RGB")
# BLIP: Generate caption
caption_inputs = caption_processor(picture, return_tensors="pt").to(system)
with torch.no_grad():
out = caption_model.generate(**caption_inputs)
description = caption_processor.decode(out(0), skip_special_tokens=True)
# CLIP: Get picture embeddings
inputs = processor(pictures=picture, return_tensors="pt").to(system)
with torch.no_grad():
image_features = mannequin.get_image_features(**inputs)
image_features = image_features.cpu().numpy().flatten().tolist()
information.append({
"image_path": img_path,
"image_description": description,
"image_embeddings": image_features
})
df = pd.DataFrame(information)8.
Empuramos nossas incorporações em um banco de dados vetorial.
import chromadb
consumer = chromadb.Consumer()
assortment = consumer.create_collection(identify="animal_images")
for i, row in df.iterrows():
assortment.add( # upserting to our chroma assortment
ids=(str(i)),
paperwork=(row("image_description")),
metadatas=({"image_path": row("image_path")}),
embeddings=(row("image_embeddings"))
)
print("✅ All pictures saved in Chroma")9. Crie uma função de pesquisa
Dada uma consulta de texto:
- O clipe o codifica em uma incorporação.
- Chromadb Encontra as incorporações de imagem mais próximas.
- Nós exibimos os resultados.
import matplotlib.pyplot as plt
def search_images(question, top_k=5):
inputs = processor(textual content=(question), return_tensors="pt", truncation=True).to(system)
with torch.no_grad():
text_embedding = mannequin.get_text_features(**inputs)
text_embedding = text_embedding.cpu().numpy().flatten().tolist()
outcomes = assortment.question(
query_embeddings=(text_embedding),
n_results=top_k
)
print("Prime outcomes for:", question)
for i, meta in enumerate(outcomes("metadatas")(0)):
img_path = meta("image_path")
print(f"{i+1}. {img_path} ({outcomes('paperwork')(0)(i)})")
img = Picture.open(img_path)
plt.imshow(img)
plt.axis("off")
plt.present()
return outcomes10. Teste o mecanismo de pesquisa
Experimente algumas consultas:
search_images("a big wild cat with stripes")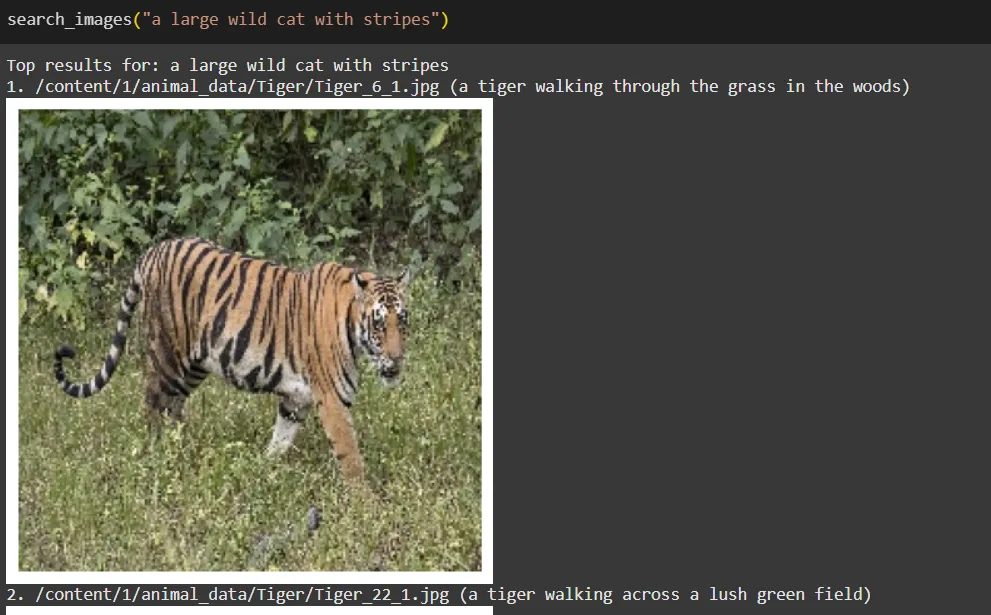
search_images("predator with a mane")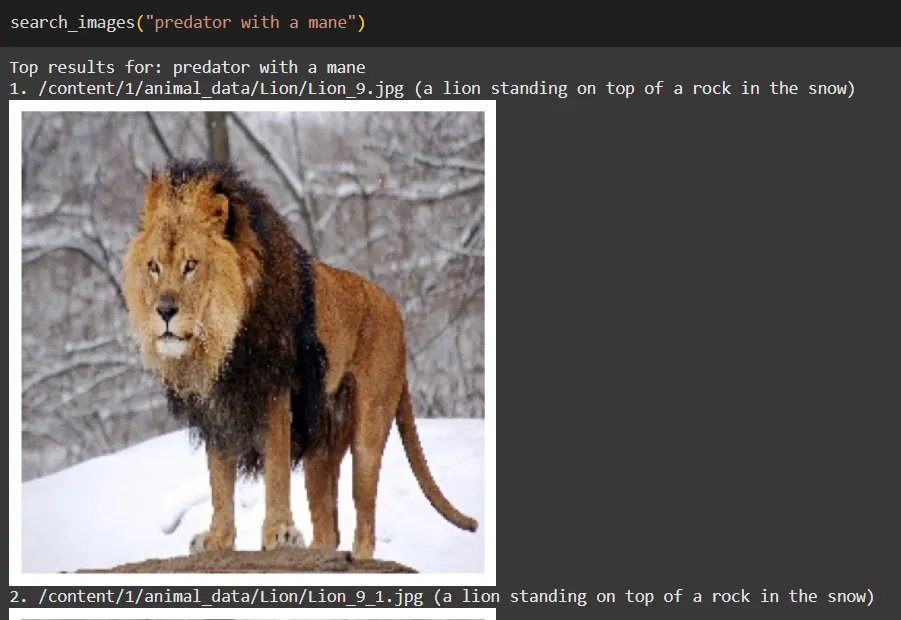
search_images("striped horse-like animal")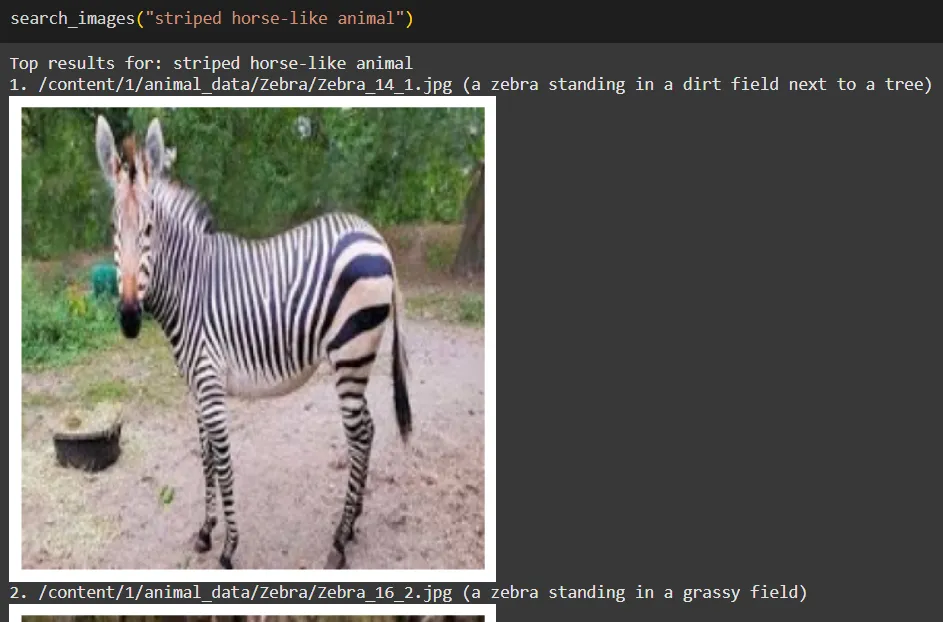
Como funciona em termos simples
- Blip: Olha para cada imagem e escreve uma legenda (isso se torna nosso “texto” para a imagem).
- GRAMPO: Converte legendas e imagens em incorporações no mesmo espaço.
- Chromadb: Armazena essas incorporações e encontra a partida mais próxima quando pesquisarmos.
- Função de pesquisa (retriever): Transforma sua consulta em uma incorporação e pergunta a Chromadb: “Quais imagens estão mais próximas a esta consulta incorporando?”
Lembre -se de que esse mecanismo de pesquisa seria mais eficaz se tivéssemos um conjunto de dados muito maior e, se utilizássemos uma descrição melhor para cada imagem, faria muito incorporação eficaz em nosso espaço de representação unificado.
Limitações
- As legendas do BLIP podem ser genéricas para algumas imagens.
- As incorporações do Clip funcionam bem para conceitos gerais, mas podem ter dificuldades com diferenças muito específicas de domínio ou de granulação fino, a menos que sejam treinadas em dados semelhantes.
- A qualidade da pesquisa depende muito do tamanho e da diversidade do conjunto de dados.
Conclusão
Em resumo, a criação de um mecanismo de pesquisa de imagens em miniatura usando representações vetoriais de texto e imagens oferece oportunidades interessantes para melhorar a recuperação de imagens. Utilizando Blip Para legendas e clipes para incorporação, podemos criar uma ferramenta versátil que se adapta a vários conjuntos de dados, de fotos pessoais a coleções especializadas.
Olhando para o futuro, recursos como a pesquisa de imagem para imagem podem enriquecer ainda mais a experiência do usuário, permitindo fácil descoberta de imagens visualmente semelhantes. Além disso, alavancando maior GRAMPO Modelos e ajustá-los em conjuntos de dados específicos podem aumentar significativamente a precisão da pesquisa.
Este projeto não serve apenas como uma base sólida para a pesquisa de imagens orientada pela IA, mas também convida a exploração e inovação adicionais. Abrace o potencial dessa tecnologia e transforme a maneira como nos envolvemos com imagens.
Perguntas frequentes
A. Blip gera legendas para imagens, criando descrições textuais que podem ser incorporadas e comparadas com as consultas de pesquisa. Isso é útil quando o conjunto de dados já não possui rótulos.
A. Clip converte imagens e texto em incorporação no mesmo espaço vetorial, permitindo comparação direta entre elas para encontrar correspondências semânticas.
A. Chromadb armazena as incorporações e recupera as imagens mais relevantes, encontrando as correspondências mais próximas da incorporação de uma consulta de pesquisa.
Genai Intern @ Analytics Vidhya | Último ano @ vit chennai
Apaixonado por IA e aprendizado de máquina, estou ansioso para mergulhar em papéis como engenheiro de IA/ML ou cientista de dados, onde posso causar um impacto actual. Com um talento especial para o aprendizado rápido e um amor pelo trabalho em equipe, estou animado para trazer soluções inovadoras e avanços de ponta para a mesa. Minha curiosidade me leva a explorar a IA em vários campos e tomar a iniciativa de se aprofundar na engenharia de dados, garantindo que eu fique à frente e entregue projetos impactantes.
Faça login para continuar lendo e desfrutar de conteúdo com curado especialista.