 Imagem fornecida pelos autores – gerada usando Gemini.
Imagem fornecida pelos autores – gerada usando Gemini.
Para muitos de nós, a inteligência synthetic (IA) se tornou parte da vida cotidiana, e a taxa na qual atribuímos papéis anteriormente humanos aos sistemas de IA não mostra sinais de desaceleração. Os sistemas de IA são os ingredientes cruciais de muitas tecnologias-por exemplo, carros autônomos, planejamento urbano inteligente, assistentes digitais-em um número crescente de domínios. No centro de muitas dessas tecnologias, há agentes autônomos – sistemas projetados para agir em nome dos seres humanos e tomar decisões sem supervisão direta. Para agir de maneira eficaz no mundo actual, esses agentes devem ser capazes de realizar uma ampla gama de tarefas, apesar das condições ambientais possivelmente imprevisíveis, o que geralmente requer alguma forma de aprendizado de máquina (ML) para alcançar o comportamento adaptativo.
Aprendizagem de reforço (RL) (6) se destaca como uma poderosa técnica de ML para os agentes de treinamento alcançarem o comportamento splendid em ambientes estocásticos. Os agentes da RL aprendem interagindo com seu ambiente: para todas as ações que tomam, recebem recompensas ou multas específicas do contexto. Com o tempo, eles aprendem comportamentos que maximizam as recompensas esperadas ao longo de seu tempo de execução.
Imagem fornecida pelos autores – gerada usando Gemini.
Os agentes da RL podem dominar uma ampla variedade de tarefas complexas, desde ganhar videogames até controlar sistemas ciber-físicos, como carros autônomos, muitas vezes superando o que os humanos especializados são capazes. Esse comportamento splendid e eficiente, no entanto, se deixado totalmente irrestrito, pode ser desanimador ou até perigoso para os humanos que isso afeta. Isso motiva o esforço de pesquisa substancial em RL seguroonde técnicas especializadas são desenvolvidas para garantir que os agentes da RL atendam aos requisitos de segurança específicos. Esses requisitos são frequentemente expressos em idiomas formais, como lógica temporal linear (LTL)que estende a lógica clássica (verdadeira/falsa) com operadores temporais, permitindo -nos especificar condições como “algo que deve sempre manter” ou “algo que deve eventualmente ocorrer”. Ao combinar a adaptabilidade do ML com a precisão da lógica, os pesquisadores desenvolveram métodos poderosos para os agentes de treinamento agirem de maneira eficaz e segura.
No entanto, a segurança não é tudo. De fato, como os agentes baseados em RL recebem cada vez mais papéis que substituem ou interagem de perto com os seres humanos, surge um novo desafio: garantir que seu comportamento também seja compatível com o Normas sociais, legais e éticas Essa estrutura da sociedade humana, que muitas vezes vai além de restrições simples, garantindo a segurança. Por exemplo, um carro autônomo pode seguir perfeitamente as restrições de segurança (por exemplo, evitando colisões), mas ainda adota comportamentos que, apesar de tecnicamente seguros, violam as normas sociais, parecendo bizarras ou rudes na estrada, o que pode causar outros motoristas (humanos) a reagir de maneiras inseguras.
As normas são tipicamente expressas como obrigações (“você deve fazê -lo”), permissões (“você tem permissão para fazê -lo”) e proibições (“você é proibido de fazê -lo”), que não são declarações que podem ser verdadeiras ou falsas, como fórmulas lógicas clássicas. Em vez disso, são conceitos deontic: eles descrevem o que é certo, errado ou permitido – comportamento splendid ou aceitável, em vez do que é realmente o caso. Esta nuance introduz várias dinâmicas difíceis ao raciocínio sobre normas, que muitas lógicas (como LTL) lutam para lidar. Mesmo sistemas normativos todos os dias, como regulamentos de direção, podem apresentar essas complicações; Embora algumas normas possam ser muito simples (por exemplo, nunca excedem 50 km / h dentro dos limites da cidade), outras podem ser mais complexas, como em:
- Mantenha sempre 10 metros entre o seu veículo e os veículos na frente e atrás de você.
- Se houver menos de 10 metros entre você e o veículo atrás de você, você deve desacelerar Para colocar mais espaço entre você e o veículo à sua frente.
(2) é um exemplo de um obrigação contrária a serviço (CTD), uma obrigação que você deve seguir especificamente em uma situação em que outra Primário A obrigação (1) já foi violada, por exemplo, compensar ou reduzir os danos. Embora estudados extensivamente nos campos do raciocínio normativo e da lógica deôntica, essas normas podem ser problemáticas para muitos métodos básicos de RL seguros com base na aplicação de restrições de LTL, como foi discutido em (4).
No entanto, aí são Abordagens para RL segura que mostram mais potencial. Um exemplo notável é o Parafuso de restrição Técnica, introduzida por De Giacomo et al. (2). Nomeado após um dispositivo usado no universo de Guerra nas Estrelas para conter o comportamento dos dróides, esse método influencia as ações de um agente para se alinhar com as regras especificadas, enquanto ainda permite que ele persegue seus objetivos. Ou seja, o parafuso de restrição modifica o comportamento que um agente da RL aprende, para que também respeite um conjunto de especificações. Essas especificações, expressas em uma variante de LTL (LTLF (3)), são emparelhadas com sua própria recompensa. A idéia central é simples, mas poderosa: junto com as recompensas que o agente recebe ao explorar o ambiente, adicionamos uma recompensa adicional sempre que suas ações satisfazem a especificação correspondente, cutucando -a para se comportar de maneiras que se alinham aos requisitos de segurança individuais. A atribuição de recompensas específicas a especificações individuais nos permite modelar dinâmicas mais complicadas, como, por exemplo, obrigações do CTD, atribuindo uma recompensa por obedecer à obrigação principal e uma recompensa diferente por obedecer à obrigação do CTD.
Ainda assim, os problemas com as normas de modelagem persistem; Por exemplo, muitas normas (se não a maioria) são condicionais. Considere a obrigação afirmando que “se os pedestres estiverem presentes em uma travessia de pedestres, os veículos próximos devem parar”. Se um agente fosse recompensado toda vez que essa regra estivesse satisfeita, ela também receberia recompensas em situações em que a norma não está realmente em vigor. Isso ocorre porque, na lógica, uma implicação também se mantém quando o antecedente (“os pedestres estão presentes”) é falso. Como resultado, o agente é recompensado sempre que os pedestres não estão por perto e podem aprender a prolongar seu tempo de execução, a fim de acumular essas recompensas por efetivamente não fazer nada, em vez de perseguir com eficiência sua tarefa pretendida (por exemplo, chegar a um destino). Em (5) mostramos que existem cenários em que um agente ignorará as normas ou aprenderá esse comportamento de “procrastinação”, não importa quais recompensas escolhemos. Como resultado, introduzimos Parafusos de restrição normativos (NRBS), um passo à frente para aplicar normas em agentes RL. Ao contrário do parafuso de restrição unique, que incentivou a conformidade, fornecendo recompensas adicionais, a versão normativa, em vez disso, pune a norma violações. Esse design é inspirado na visão andersoniana da lógica deontica (1), que trata as obrigações como regras cuja violação necessariamente desencadeia uma sanção. Assim, a estrutura não depende mais do comportamento aceitável para reforçar, mas aplica as normas, garantindo que as violações carregam penalidades tangíveis. Embora eficazes para gerenciar dinâmicas normativas intrincadas, como obrigações condicionais, contrárias e exceções às normas, os NRBs dependem do ajuste de recompensa de tentativa e erro para implementar a adesão das normas e, portanto, pode ser pesada, especialmente ao tentar resolver conflitos entre normas. Além disso, eles exigem reciclagem para acomodar as atualizações de normas e não se prestam a garantir que as políticas ideais minimizem as violações das normas.
Nossa contribuição
Construindo no NRBS, apresentamos Parafusos de restrição normativos ordenados (ONRBS)uma estrutura para orientar os agentes de aprendizagem de reforço a cumprir as normas sociais, legais e éticas, abordando as limitações dos NRBs. Nesta abordagem, cada norma é tratada como um objetivo em um problema de aprendizado de reforço de múltiplos objetivos (MORL). Reformular o problema dessa maneira nos permite:
- Show que, quando as normas não conflitam, um agente que aprende o comportamento splendid minimiza as violações das normas ao longo do tempo.
- Expresse as relações entre as normas em termos de um sistema de classificação que descreve qual norma deve ser priorizada quando ocorrer um conflito.
- Use as técnicas MORL para determinar algoritmicamente a magnitude necessária das punições que atribuímos de modo que É garantido que, desde que um agente aprenda o comportamento splendid, as normas serão violadas o mínimo possível, priorizando as normas com a classificação mais alta.
- Acomodam mudanças em nossos sistemas normativos ao “desativar” ou “reativar” normas específicas.
Testamos nossa estrutura em um ambiente do mundo da rede inspirado nos jogos de estratégia, onde um agente aprende a coletar recursos e entregá-los a áreas designadas. Essa configuração nos permite demonstrar a capacidade da estrutura de lidar com os complexos cenários normativos que observamos acima, juntamente com a priorização direta de normas conflitantes e atualizações de normas. Por exemplo, a figura abaixo
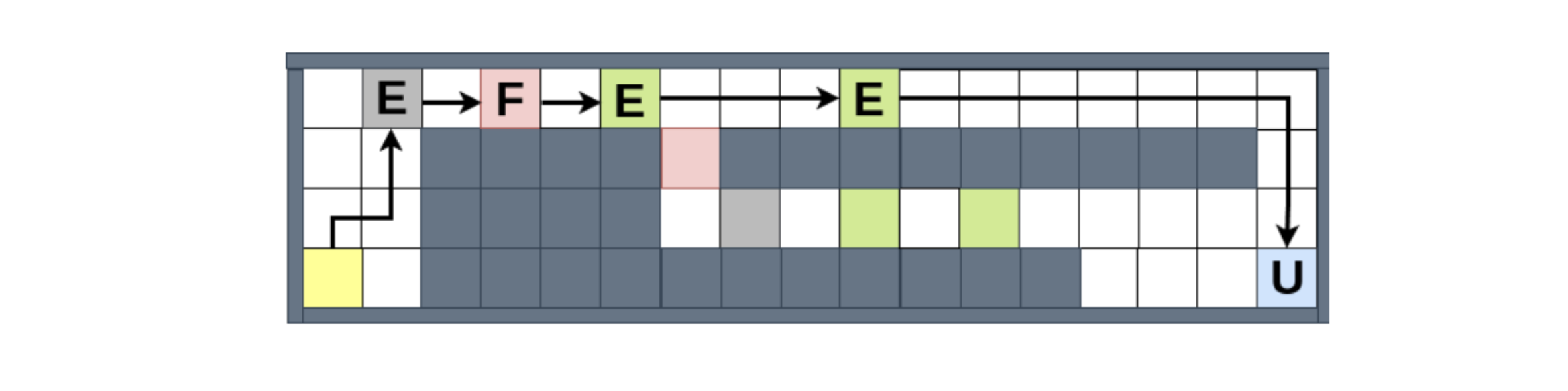
Exibe como o agente lida com conflitos de norma, quando é obrigado a (1) evitar as áreas perigosas (rosa) e (2) atingir a área do mercado (azul) por um determinado prazo, supondo que a segunda norma tenha prioridade. Podemos ver que ele escolhe violar (1) uma vez, porque, caso contrário, ficará preso no início do mapa, incapaz de cumprir (2). No entanto, quando dada a possibilidade de violar (1) mais uma vez, ele escolhe o caminho compatível, mesmo que o caminho violador permitiria coletar mais recursos e, portanto, mais recompensas do meio ambiente.
Em resumo, combinando a RL com a lógica, podemos construir agentes de IA que não funcionam apenas, eles funcionam corretamente.
Este trabalho ganhou um Prêmio de Papel Distinguished em Ijcai 2025. Leia o artigo integralmente: Combinando Morl com parafusos de restrição para aprender comportamento normativoEmery A. Neufeld, Agata Ciabattoni e Radu Florin Tulcan.
Agradecimentos
Esta pesquisa foi financiada pelo Projeto Viena Science and Expertise Fund (WWTF) ICT22-023 e pelo Fundo de Ciência Austríaca (FWF) 10.55776/COE12 Cluster of Excellence Bilateral AI.
Referências
(1) Alan Ross Anderson. Uma redução da lógica deontica para a lógica modal alética. Mente67 (265): 100-103, 1958.
(2) Giuseppe de Giacomo, Luca iocchi, Marco Favorito e Fabio Patrizi. Fundamentos para parafusos de restrição: Aprendizagem de reforço com especificações de restrição LTLF/LDLF. Em Anais da Conferência Internacional sobre Planejamento e Agenda AutomatizadosQuantity 29, páginas 128-136, 2019.
(3) Giuseppe de Giacomo e Moshe y Vardi. Lógica temporal linear e lógica dinâmica linear em traços finitos. Em IjcaiQuantity 13, páginas 854-860, 2013.
(4) Emery Neufeld, Ezio Bartocci e Agata Ciabattoni. Sobre o aprendizado normativo de reforço por meio de aprendizado de reforço seguro. Em Prima 2022, 2022.
(5) Emery a Neufeld, Agata Ciabattoni e Radu Florin Tulcan. Conformidade de normas em agentes de aprendizado de reforço por meio de parafusos de restrição. Em Sistemas jurídicos de conhecimento e informação Jurix 2024páginas 119-130. IOS Press, 2024.
(6) Richard S. Sutton e Andrew G. Barto. Aprendizagem de reforço – uma introdução. Computação adaptativa e aprendizado de máquina. MIT Press, 1998.

Agata Ciabattoni é professor da TU Wien.

Emery Neufeld é pesquisador de pós -doutorado da TU Wien.