 |
Hoje estamos apresentando Incorporações multimodais do Amazon Novaum modelo de incorporação multimodal de última geração para agentes geração aumentada de recuperação (RAG) e aplicativos de pesquisa semântica, disponíveis em Base Amazônica. É o primeiro modelo de incorporação unificado que oferece suporte a texto, documentos, imagens, vídeo e áudio por meio de um único modelo para permitir a recuperação crossmodal com precisão líder.
Os modelos de incorporação convertem entradas textuais, visuais e de áudio em representações numéricas chamadas incorporações. Essas incorporações capturam o significado da entrada de uma forma que os sistemas de IA podem comparar, pesquisar e analisar, potencializando casos de uso como pesquisa semântica e RAG.
As organizações buscam cada vez mais soluções para desbloquear insights do crescente quantity de dados não estruturados que estão espalhados por conteúdo de texto, imagem, documento, vídeo e áudio. Por exemplo, uma organização pode ter imagens de produtos, folhetos que contenham infográficos e texto e videoclipes enviados por usuários. Os modelos de incorporação são capazes de extrair valor de dados não estruturados; no entanto, os modelos tradicionais são normalmente especializados para lidar com um tipo de conteúdo. Essa limitação leva os clientes a criar soluções complexas de incorporação crossmodal ou a restringir-se a casos de uso focados em um único tipo de conteúdo. O problema também se aplica a tipos de conteúdo de modalidade mista, como documentos com texto e imagens intercalados ou vídeo com elementos visuais, de áudio e textuais, onde os modelos existentes lutam para capturar relações intermodais de forma eficaz.
O Nova Multimodal Embeddings oferece suporte a um espaço semântico unificado para texto, documentos, imagens, vídeo e áudio para casos de uso como pesquisa crossmodal em conteúdo de modalidade mista, pesquisa com uma imagem de referência e recuperação de documentos visuais.
Avaliando o desempenho dos embeddings multimodais do Amazon Nova
Avaliamos o modelo em uma ampla gama de benchmarks e ele oferece precisão líder pronta para uso, conforme descrito na tabela a seguir.
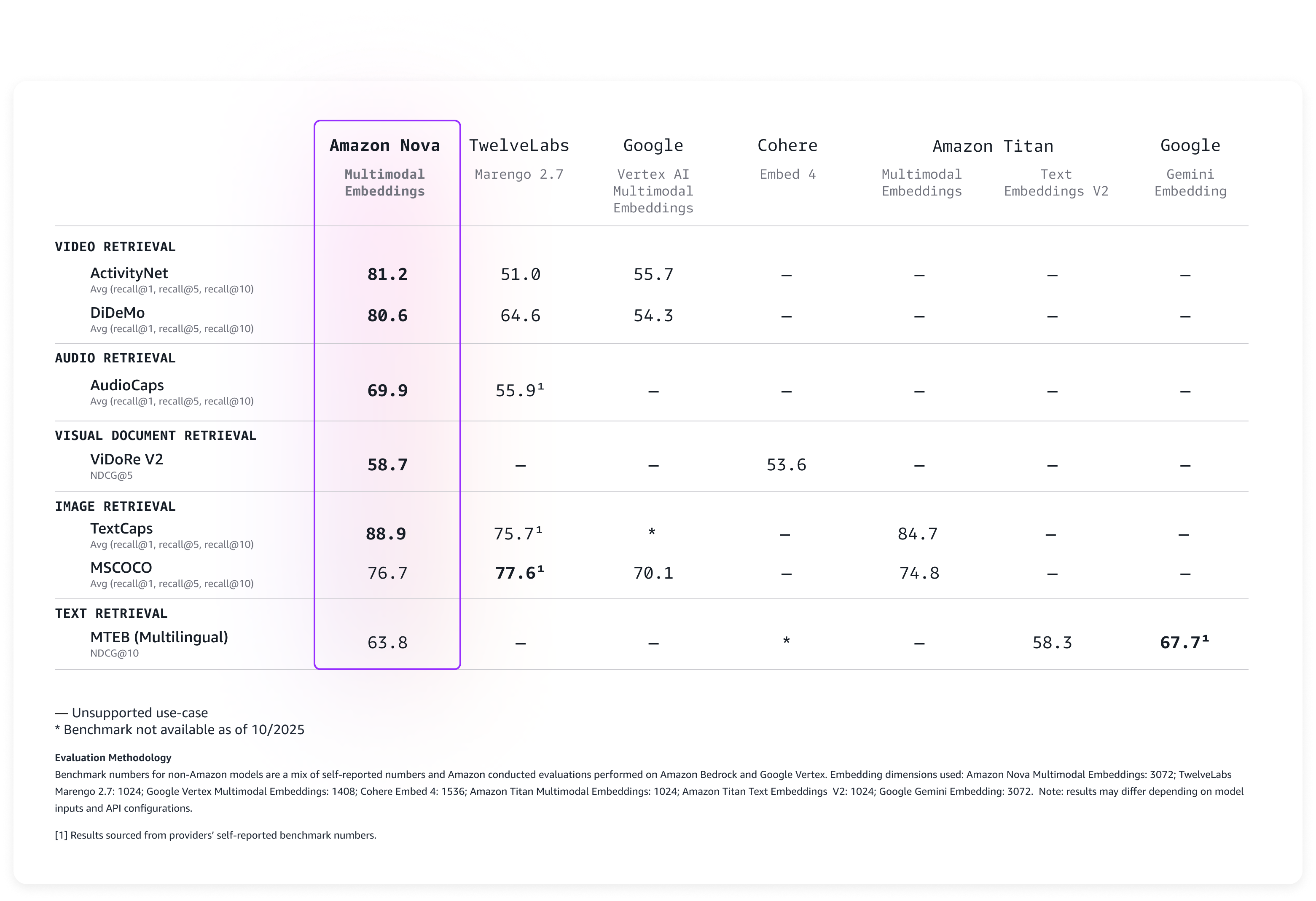
Nova Multimodal Embeddings suporta um comprimento de contexto de até 8K tokens, texto em até 200 idiomas e aceita entradas por meio de APIs síncronas e assíncronas. Além disso, ele oferece suporte à segmentação (também conhecida como “chunking”) para particionar conteúdo de texto, vídeo ou áudio de formato longo em segmentos gerenciáveis, gerando embeddings para cada parte. Por último, o modelo oferece quatro dimensões de incorporação de saída, treinadas usando Aprendizagem de Representação Matryoshka (MRL) que permite recuperação ponta a ponta de baixa latência com alterações mínimas de precisão.
Vamos ver como o novo modelo pode ser utilizado na prática.
Usando incorporações multimodais do Amazon Nova
A introdução ao Nova Multimodal Embeddings segue o mesmo padrão de outros modelos no Amazon Bedrock. O modelo aceita texto, documentos, imagens, vídeo ou áudio como entrada e retorna embeddings numéricos que podem ser usados para pesquisa semântica, comparação de similaridade ou RAG.
Aqui está um exemplo prático usando o SDK da AWS para Python (Boto3) que mostra como criar embeddings de diferentes tipos de conteúdo e armazená-los para recuperação posterior. Para simplificar, usarei Vetores Amazon S3um armazenamento com custo otimizado e suporte nativo para armazenamento e consulta de vetores em qualquer escala, para armazenar e pesquisar os embeddings.
Vamos começar com o básico: converter texto em embeddings. Este exemplo mostra como transformar uma descrição de texto simples em uma representação numérica que captura seu significado semântico. Posteriormente, esses embeddings podem ser comparados com embeddings de documentos, imagens, vídeos ou áudio para encontrar conteúdo relacionado.
Para facilitar o acompanhamento do código, mostrarei uma seção do script por vez. O script completo está incluído no last deste passo a passo.
import json
import base64
import time
import boto3
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
EMBEDDING_DIMENSION = 3072
# Initialize Amazon Bedrock Runtime shopper
bedrock_runtime = boto3.shopper("bedrock-runtime", region_name="us-east-1")
print(f"Producing textual content embedding with {MODEL_ID} ...")
# Textual content to embed
textual content = "Amazon Nova is a multimodal basis mannequin"
# Create embedding
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"textual content": {"truncationMode": "END", "worth": textual content},
},
}
response = bedrock_runtime.invoke_model(
physique=json.dumps(request_body),
modelId=MODEL_ID,
contentType="software/json",
)
# Extract embedding
response_body = json.hundreds(response("physique").learn())
embedding = response_body("embeddings")(0)("embedding")
print(f"Generated embedding with {len(embedding)} dimensions")Agora processaremos o conteúdo visible usando o mesmo espaço de incorporação usando um photograph.jpg arquivo na mesma pasta do script. Isso demonstra o poder da multimodalidade: o Nova Multimodal Embeddings é capaz de capturar o contexto textual e visible em uma única incorporação que fornece melhor compreensão do documento.
Nova Multimodal Embeddings pode gerar embeddings otimizados para a forma como estão sendo usados. Ao indexar um caso de uso de pesquisa ou recuperação, embeddingPurpose pode ser definido para GENERIC_INDEX. Para a etapa de consulta, embeddingPurpose pode ser definido dependendo do tipo de merchandise a ser recuperado. Por exemplo, ao recuperar documentos, embeddingPurpose pode ser definido para DOCUMENT_RETRIEVAL.
# Learn and encode picture
print(f"Producing picture embedding with {MODEL_ID} ...")
with open("photograph.jpg", "rb") as f:
image_bytes = base64.b64encode(f.learn()).decode("utf-8")
# Create embedding
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"picture": {
"format": "jpeg",
"supply": {"bytes": image_bytes}
},
},
}
response = bedrock_runtime.invoke_model(
physique=json.dumps(request_body),
modelId=MODEL_ID,
contentType="software/json",
)
# Extract embedding
response_body = json.hundreds(response("physique").learn())
embedding = response_body("embeddings")(0)("embedding")
print(f"Generated embedding with {len(embedding)} dimensions")Para processar conteúdo de vídeo, uso a API assíncrona. Esse é um requisito para vídeos maiores que 25 MB quando codificados como Base64. Primeiro, carrego um vídeo native em um bucket S3 no mesmo Região AWS.
aws s3 cp presentation.mp4 s3://my-video-bucket/movies/Este exemplo mostra como extrair embeddings de componentes visuais e de áudio de um arquivo de vídeo. O recurso de segmentação divide vídeos mais longos em partes gerenciáveis, tornando prático pesquisar horas de conteúdo com eficiência.
# Initialize Amazon S3 shopper
s3 = boto3.shopper("s3", region_name="us-east-1")
print(f"Producing video embedding with {MODEL_ID} ...")
# Amazon S3 URIs
S3_VIDEO_URI = "s3://my-video-bucket/movies/presentation.mp4"
S3_EMBEDDING_DESTINATION_URI = "s3://my-embedding-destination-bucket/embeddings-output/"
# Create async embedding job for video with audio
model_input = {
"taskType": "SEGMENTED_EMBEDDING",
"segmentedEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"video": {
"format": "mp4",
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"supply": {
"s3Location": {"uri": S3_VIDEO_URI}
},
"segmentationConfig": {
"durationSeconds": 15 # Phase into 15-second chunks
},
},
},
}
response = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": S3_EMBEDDING_DESTINATION_URI
}
},
)
invocation_arn = response("invocationArn")
print(f"Async job began: {invocation_arn}")
# Ballot till job completes
print("nPolling for job completion...")
whereas True:
job = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn)
standing = job("standing")
print(f"Standing: {standing}")
if standing != "InProgress":
break
time.sleep(15)
# Verify if job accomplished efficiently
if standing == "Accomplished":
output_s3_uri = job("outputDataConfig")("s3OutputDataConfig")("s3Uri")
print(f"nSuccess! Embeddings at: {output_s3_uri}")
# Parse S3 URI to get bucket and prefix
s3_uri_parts = output_s3_uri(5:).cut up("/", 1) # Take away "s3://" prefix
bucket = s3_uri_parts(0)
prefix = s3_uri_parts(1) if len(s3_uri_parts) > 1 else ""
# AUDIO_VIDEO_COMBINED mode outputs to embedding-audio-video.jsonl
# The output_s3_uri already contains the job ID, so simply append the filename
embeddings_key = f"{prefix}/embedding-audio-video.jsonl".lstrip("/")
print(f"Studying embeddings from: s3://{bucket}/{embeddings_key}")
# Learn and parse JSONL file
response = s3.get_object(Bucket=bucket, Key=embeddings_key)
content material = response('Physique').learn().decode('utf-8')
embeddings = ()
for line in content material.strip().cut up('n'):
if line:
embeddings.append(json.hundreds(line))
print(f"nFound {len(embeddings)} video segments:")
for i, section in enumerate(embeddings):
print(f" Phase {i}: {section.get('startTime', 0):.1f}s - {section.get('endTime', 0):.1f}s")
print(f" Embedding dimension: {len(section.get('embedding', ()))}")
else:
print(f"nJob failed: {job.get('failureMessage', 'Unknown error')}")Com nossos embeddings gerados, precisamos de um native para armazená-los e pesquisá-los de forma eficiente. Este exemplo demonstra a configuração de um armazenamento de vetores usando vetores do Amazon S3, que fornece a infraestrutura necessária para pesquisa de similaridade em escala. Pense nisso como a criação de um índice pesquisável onde conteúdo semanticamente semelhante se agrupa naturalmente. Ao adicionar uma incorporação ao índice, uso os metadados para especificar o formato authentic e o conteúdo que está sendo indexado.
# Initialize Amazon S3 Vectors shopper
s3vectors = boto3.shopper("s3vectors", region_name="us-east-1")
# Configuration
VECTOR_BUCKET = "my-vector-store"
INDEX_NAME = "embeddings"
# Create vector bucket and index (if they do not exist)
strive:
s3vectors.get_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Vector bucket {VECTOR_BUCKET} already exists")
besides s3vectors.exceptions.NotFoundException:
s3vectors.create_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Created vector bucket: {VECTOR_BUCKET}")
strive:
s3vectors.get_index(vectorBucketName=VECTOR_BUCKET, indexName=INDEX_NAME)
print(f"Vector index {INDEX_NAME} already exists")
besides s3vectors.exceptions.NotFoundException:
s3vectors.create_index(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
dimension=EMBEDDING_DIMENSION,
dataType="float32",
distanceMetric="cosine"
)
print(f"Created index: {INDEX_NAME}")
texts = (
"Machine studying on AWS",
"Amazon Bedrock supplies basis fashions",
"S3 Vectors allows semantic search"
)
print(f"nGenerating embeddings for {len(texts)} texts...")
# Generate embeddings utilizing Amazon Nova for every textual content
vectors = ()
for textual content in texts:
response = bedrock_runtime.invoke_model(
physique=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingDimension": EMBEDDING_DIMENSION,
"textual content": {"truncationMode": "END", "worth": textual content}
}
}),
modelId=MODEL_ID,
settle for="software/json",
contentType="software/json"
)
response_body = json.hundreds(response("physique").learn())
embedding = response_body("embeddings")(0)("embedding")
vectors.append({
"key": f"textual content:{textual content(:50)}", # Distinctive identifier
"information": {"float32": embedding},
"metadata": {"sort": "textual content", "content material": textual content}
})
print(f" ✓ Generated embedding for: {textual content}")
# Add all vectors to retailer in a single name
s3vectors.put_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
vectors=vectors
)
print(f"nSuccessfully added {len(vectors)} vectors to the shop in a single put_vectors name!")Este exemplo last demonstra a capacidade de pesquisar diferentes tipos de conteúdo com uma única consulta, encontrando o conteúdo mais semelhante, independentemente de ter origem em texto, imagens, vídeos ou áudio. As pontuações de distância ajudam você a entender o quanto os resultados estão relacionados à sua consulta authentic.
# Textual content to question
query_text = "basis fashions"
print(f"nGenerating embeddings for question '{query_text}' ...")
# Generate embeddings
response = bedrock_runtime.invoke_model(
physique=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": EMBEDDING_DIMENSION,
"textual content": {"truncationMode": "END", "worth": query_text}
}
}),
modelId=MODEL_ID,
settle for="software/json",
contentType="software/json"
)
response_body = json.hundreds(response("physique").learn())
query_embedding = response_body("embeddings")(0)("embedding")
print(f"Trying to find comparable embeddings...n")
# Seek for high 5 most comparable vectors
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
queryVector={"float32": query_embedding},
topK=5,
returnDistance=True,
returnMetadata=True
)
# Show outcomes
print(f"Discovered {len(response('vectors'))} outcomes:n")
for i, lead to enumerate(response("vectors"), 1):
print(f"{i}. {end result('key')}")
print(f" Distance: {end result('distance'):.4f}")
if end result.get("metadata"):
print(f" Metadata: {end result('metadata')}")
print()A pesquisa crossmodal é uma das principais vantagens dos embeddings multimodais. Com a pesquisa crossmodal, você pode consultar texto e encontrar imagens relevantes. Você também pode pesquisar vídeos usando descrições de texto, encontrar clipes de áudio que correspondam a determinados tópicos ou descobrir documentos com base em seu conteúdo visible e textual. Para sua referência, o script completo com todos os exemplos anteriores mesclados está aqui:
import json
import base64
import time
import boto3
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
EMBEDDING_DIMENSION = 3072
# Initialize Amazon Bedrock Runtime shopper
bedrock_runtime = boto3.shopper("bedrock-runtime", region_name="us-east-1")
print(f"Producing textual content embedding with {MODEL_ID} ...")
# Textual content to embed
textual content = "Amazon Nova is a multimodal basis mannequin"
# Create embedding
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"textual content": {"truncationMode": "END", "worth": textual content},
},
}
response = bedrock_runtime.invoke_model(
physique=json.dumps(request_body),
modelId=MODEL_ID,
contentType="software/json",
)
# Extract embedding
response_body = json.hundreds(response("physique").learn())
embedding = response_body("embeddings")(0)("embedding")
print(f"Generated embedding with {len(embedding)} dimensions")
# Learn and encode picture
print(f"Producing picture embedding with {MODEL_ID} ...")
with open("photograph.jpg", "rb") as f:
image_bytes = base64.b64encode(f.learn()).decode("utf-8")
# Create embedding
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"picture": {
"format": "jpeg",
"supply": {"bytes": image_bytes}
},
},
}
response = bedrock_runtime.invoke_model(
physique=json.dumps(request_body),
modelId=MODEL_ID,
contentType="software/json",
)
# Extract embedding
response_body = json.hundreds(response("physique").learn())
embedding = response_body("embeddings")(0)("embedding")
print(f"Generated embedding with {len(embedding)} dimensions")
# Initialize Amazon S3 shopper
s3 = boto3.shopper("s3", region_name="us-east-1")
print(f"Producing video embedding with {MODEL_ID} ...")
# Amazon S3 URIs
S3_VIDEO_URI = "s3://my-video-bucket/movies/presentation.mp4"
# Amazon S3 output bucket and site
S3_EMBEDDING_DESTINATION_URI = "s3://my-video-bucket/embeddings-output/"
# Create async embedding job for video with audio
model_input = {
"taskType": "SEGMENTED_EMBEDDING",
"segmentedEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"video": {
"format": "mp4",
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"supply": {
"s3Location": {"uri": S3_VIDEO_URI}
},
"segmentationConfig": {
"durationSeconds": 15 # Phase into 15-second chunks
},
},
},
}
response = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": S3_EMBEDDING_DESTINATION_URI
}
},
)
invocation_arn = response("invocationArn")
print(f"Async job began: {invocation_arn}")
# Ballot till job completes
print("nPolling for job completion...")
whereas True:
job = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn)
standing = job("standing")
print(f"Standing: {standing}")
if standing != "InProgress":
break
time.sleep(15)
# Verify if job accomplished efficiently
if standing == "Accomplished":
output_s3_uri = job("outputDataConfig")("s3OutputDataConfig")("s3Uri")
print(f"nSuccess! Embeddings at: {output_s3_uri}")
# Parse S3 URI to get bucket and prefix
s3_uri_parts = output_s3_uri(5:).cut up("/", 1) # Take away "s3://" prefix
bucket = s3_uri_parts(0)
prefix = s3_uri_parts(1) if len(s3_uri_parts) > 1 else ""
# AUDIO_VIDEO_COMBINED mode outputs to embedding-audio-video.jsonl
# The output_s3_uri already contains the job ID, so simply append the filename
embeddings_key = f"{prefix}/embedding-audio-video.jsonl".lstrip("/")
print(f"Studying embeddings from: s3://{bucket}/{embeddings_key}")
# Learn and parse JSONL file
response = s3.get_object(Bucket=bucket, Key=embeddings_key)
content material = response('Physique').learn().decode('utf-8')
embeddings = ()
for line in content material.strip().cut up('n'):
if line:
embeddings.append(json.hundreds(line))
print(f"nFound {len(embeddings)} video segments:")
for i, section in enumerate(embeddings):
print(f" Phase {i}: {section.get('startTime', 0):.1f}s - {section.get('endTime', 0):.1f}s")
print(f" Embedding dimension: {len(section.get('embedding', ()))}")
else:
print(f"nJob failed: {job.get('failureMessage', 'Unknown error')}")
# Initialize Amazon S3 Vectors shopper
s3vectors = boto3.shopper("s3vectors", region_name="us-east-1")
# Configuration
VECTOR_BUCKET = "my-vector-store"
INDEX_NAME = "embeddings"
# Create vector bucket and index (if they do not exist)
strive:
s3vectors.get_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Vector bucket {VECTOR_BUCKET} already exists")
besides s3vectors.exceptions.NotFoundException:
s3vectors.create_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Created vector bucket: {VECTOR_BUCKET}")
strive:
s3vectors.get_index(vectorBucketName=VECTOR_BUCKET, indexName=INDEX_NAME)
print(f"Vector index {INDEX_NAME} already exists")
besides s3vectors.exceptions.NotFoundException:
s3vectors.create_index(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
dimension=EMBEDDING_DIMENSION,
dataType="float32",
distanceMetric="cosine"
)
print(f"Created index: {INDEX_NAME}")
texts = (
"Machine studying on AWS",
"Amazon Bedrock supplies basis fashions",
"S3 Vectors allows semantic search"
)
print(f"nGenerating embeddings for {len(texts)} texts...")
# Generate embeddings utilizing Amazon Nova for every textual content
vectors = ()
for textual content in texts:
response = bedrock_runtime.invoke_model(
physique=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"textual content": {"truncationMode": "END", "worth": textual content}
}
}),
modelId=MODEL_ID,
settle for="software/json",
contentType="software/json"
)
response_body = json.hundreds(response("physique").learn())
embedding = response_body("embeddings")(0)("embedding")
vectors.append({
"key": f"textual content:{textual content(:50)}", # Distinctive identifier
"information": {"float32": embedding},
"metadata": {"sort": "textual content", "content material": textual content}
})
print(f" ✓ Generated embedding for: {textual content}")
# Add all vectors to retailer in a single name
s3vectors.put_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
vectors=vectors
)
print(f"nSuccessfully added {len(vectors)} vectors to the shop in a single put_vectors name!")
# Textual content to question
query_text = "basis fashions"
print(f"nGenerating embeddings for question '{query_text}' ...")
# Generate embeddings
response = bedrock_runtime.invoke_model(
physique=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": EMBEDDING_DIMENSION,
"textual content": {"truncationMode": "END", "worth": query_text}
}
}),
modelId=MODEL_ID,
settle for="software/json",
contentType="software/json"
)
response_body = json.hundreds(response("physique").learn())
query_embedding = response_body("embeddings")(0)("embedding")
print(f"Trying to find comparable embeddings...n")
# Seek for high 5 most comparable vectors
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
queryVector={"float32": query_embedding},
topK=5,
returnDistance=True,
returnMetadata=True
)
# Show outcomes
print(f"Discovered {len(response('vectors'))} outcomes:n")
for i, lead to enumerate(response("vectors"), 1):
print(f"{i}. {end result('key')}")
print(f" Distance: {end result('distance'):.4f}")
if end result.get("metadata"):
print(f" Metadata: {end result('metadata')}")
print()Para aplicações de produção, os embeddings podem ser armazenados em qualquer banco de dados vetorial. Serviço Amazon OpenSearch oferece integração nativa com o Nova Multimodal Embeddings no lançamento, facilitando a construção de aplicativos de pesquisa escalonáveis. Como mostrado nos exemplos anteriores, Vetores Amazon S3 fornece uma maneira simples de armazenar e consultar embeddings com os dados do seu aplicativo.
Coisas para saber
Nova Multimodal Embeddings oferece quatro opções de dimensões de saída: 3.072, 1.024, 384 e 256. Dimensões maiores fornecem representações mais detalhadas, mas requerem mais armazenamento e computação. Dimensões menores oferecem um equilíbrio prático entre desempenho de recuperação e eficiência de recursos. Essa flexibilidade ajuda você a otimizar suas aplicações específicas e requisitos de custo.
O modelo lida com comprimentos de contexto substanciais. Para entradas de texto, ele pode processar até 8.192 tokens de uma só vez. As entradas de vídeo e áudio suportam segmentos de até 30 segundos, e o modelo pode segmentar arquivos mais longos. Esse recurso de segmentação é particularmente útil ao trabalhar com arquivos de mídia grandes: o modelo os divide em partes gerenciáveis e cria incorporações para cada segmento.
O modelo inclui recursos de IA responsáveis integrados ao Amazon Bedrock. O conteúdo enviado para incorporação passa pelos filtros de segurança de conteúdo do Amazon Bedrock, e o modelo inclui medidas de justiça para reduzir preconceitos.
Conforme descrito nos exemplos de código, o modelo pode ser invocado por meio de APIs síncronas e assíncronas. A API síncrona funciona bem para aplicativos em tempo actual onde você precisa de respostas imediatas, como o processamento de consultas de usuários em uma interface de pesquisa. A API assíncrona lida com cargas de trabalho insensíveis à latência com mais eficiência, tornando-a adequada para processar conteúdo grande, como vídeos.
Disponibilidade e preços
Incorporações multimodais do Amazon Nova está disponível hoje no Amazon Bedrock no Leste dos EUA (Norte da Virgínia) Região AWS. Para informações detalhadas sobre preços, visite o Página de preços do Amazon Bedrock.
Para saber mais, consulte o Guia do usuário do Amazon Nova para documentação abrangente e Livro de receitas do modelo Amazon Nova no GitHub para exemplos práticos de código.
Se você estiver usando um assistente com tecnologia de IA para desenvolvimento de software program, como Desenvolvedor Amazon Q ou Kirovocê pode configurar o Servidor API MCP da AWS para ajudar os assistentes de IA a interagir com os serviços e recursos da AWS e o Servidor AWS Information MCP para fornecer documentação atualizada, exemplos de código, conhecimento sobre a disponibilidade regional de APIs da AWS e recursos do CloudFormation.
Comece a criar aplicativos multimodais baseados em IA com o Nova Multimodal Embeddings hoje mesmo e compartilhe seu suggestions por meio de AWS re:Submit para Amazon Bedrock ou seus contatos habituais do AWS Assist.
– Danilo