O Amazon SageMaker agora aprimora os resultados da pesquisa em Estúdio unificado Amazon SageMaker com contexto adicional que melhora a transparência e a interpretabilidade. Os usuários podem ver quais campos de metadados correspondem à sua consulta e entender por que cada resultado aparece, aumentando a clareza e a confiança na descoberta de dados. O recurso introduz destaque em linha para termos correspondentes e um painel de explicação que detalha onde e como cada correspondência ocorreu em campos de metadados, como nome, descrição, glossário e esquema. Os resultados de pesquisa aprimorados reduzem o tempo gasto na avaliação de ativos irrelevantes, apresentando evidências de correspondência diretamente nos resultados da pesquisa. Os usuários podem validar rapidamente a relevância sem analisar ativos individuais.
Nesta postagem, demonstramos como usar a pesquisa aprimorada no Amazon SageMaker.
Resultados da pesquisa com contexto
As correspondências de texto incluem correspondência de palavras-chave, começa com, sinônimos e texto semanticamente relacionado. A pesquisa avançada exibe correspondências de texto dos resultados da pesquisa nestes locais:
- Resultado da pesquisa: as correspondências de texto em cada nome, descrição e termos do glossário de cada resultado da pesquisa são destacadas.
- Sobre este painel de resultados: Um novo Sobre este resultado O painel é exibido à direita do resultado da pesquisa destacado. O painel exibe as correspondências de texto para o conteúdo pesquisável do merchandise de resultado, incluindo nome, descrição, termos do glossário, metadados, nomes comerciais e esquema de tabela. A lista de valores exclusivos de correspondência de texto é exibida na parte superior do painel para referência rápida.
Os catálogos de dados contêm milhares de conjuntos de dados, modelos e projetos. Sem transparência, os usuários não podem dizer por que determinados resultados aparecem ou confiar na ordem. Os usuários precisam de evidências da relevância e compreensão da pesquisa.
A pesquisa aprimorada com explicações de correspondência melhora a pesquisa no catálogo de quatro maneiras principais:
1) a transparência aumenta porque os usuários podem ver por que um resultado apareceu e ganhar confiança,
2) a eficiência melhora, pois os destaques e as explicações reduzem o tempo gasto na abertura de ativos irrelevantes,
3) a governança é apoiada mostrando onde e como os termos são correspondidos, auxiliando nos processos de auditoria e conformidade, e
4) a consistência é reforçada pela revelação do glossário e das relações semânticas, o que reduz mal-entendidos e melhora a colaboração entre as equipes.
Como funciona a pesquisa aprimorada
Quando um usuário insere uma consulta, o sistema pesquisa vários campos como nome, descrição, termos do glossário, metadados, nomes comerciais e esquema de tabela. Com transparência de pesquisa aprimorada, cada resultado da pesquisa inclui a lista de correspondências de texto que serviu de base para a inclusão do resultado, incluindo o campo que continha a correspondência de texto e uma parte do valor de texto do campo antes e depois da correspondência de texto, para fornecer contexto. A IU usa essas informações para exibir o texto retornado com a correspondência de texto destacada.
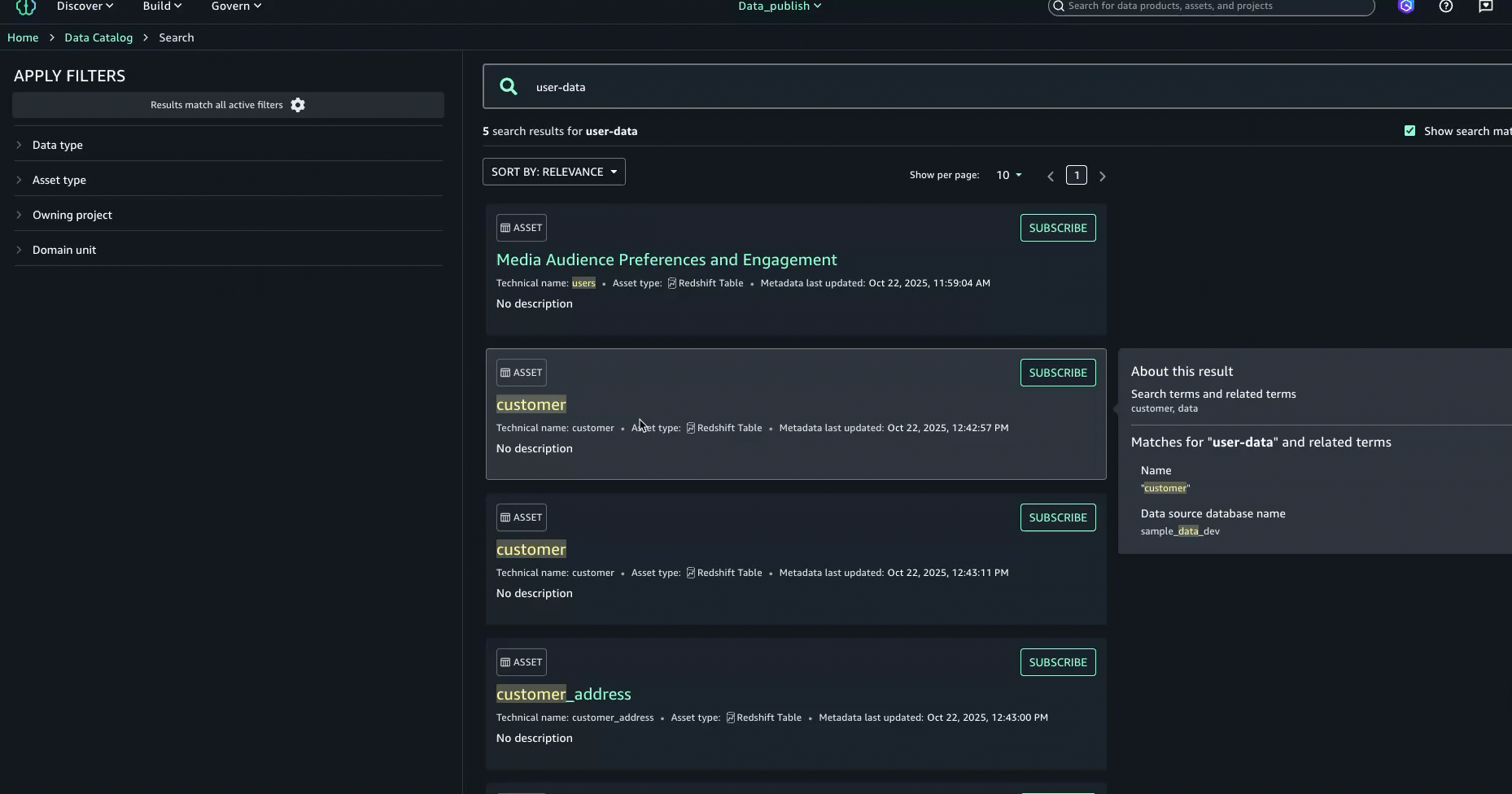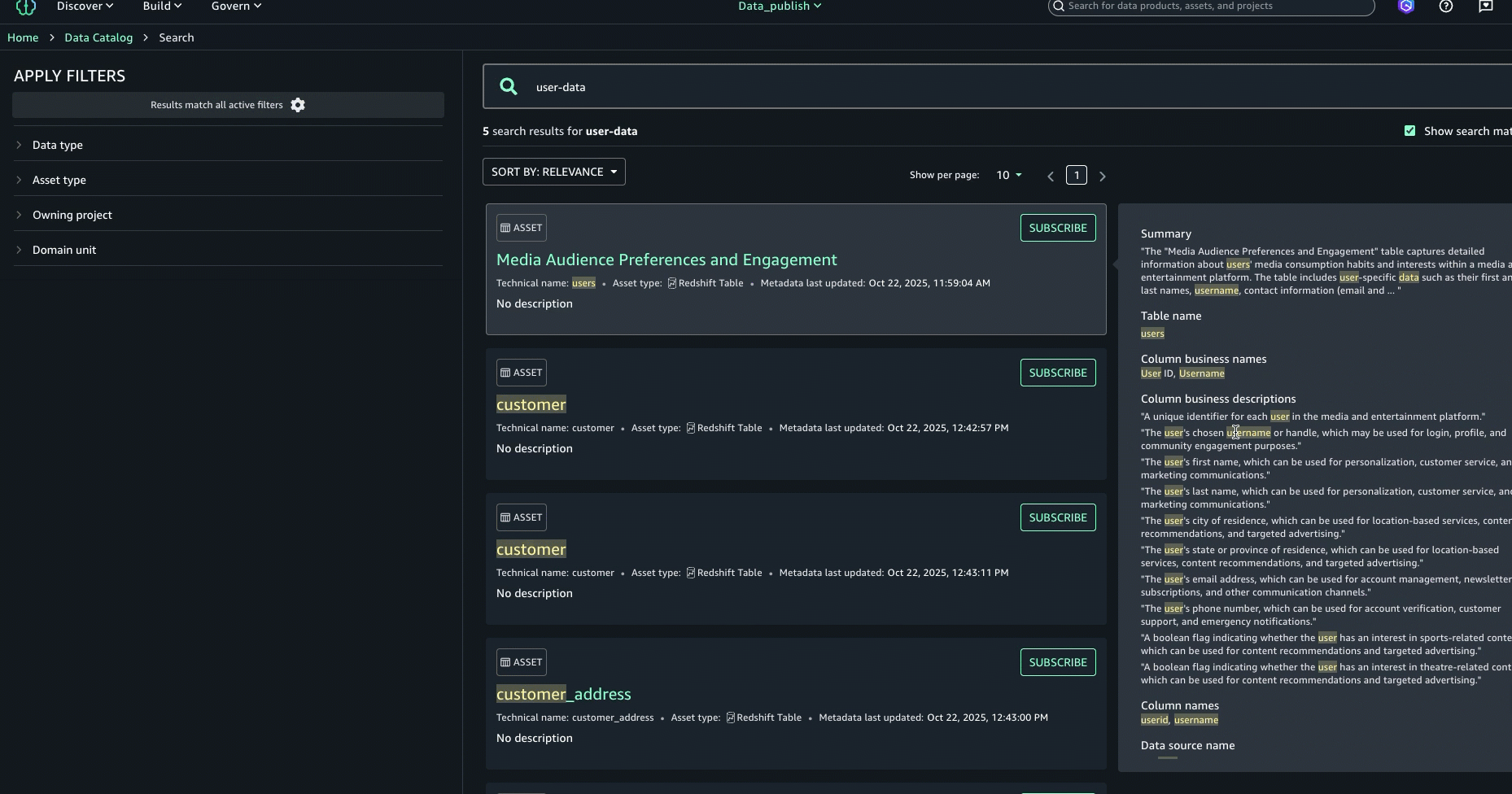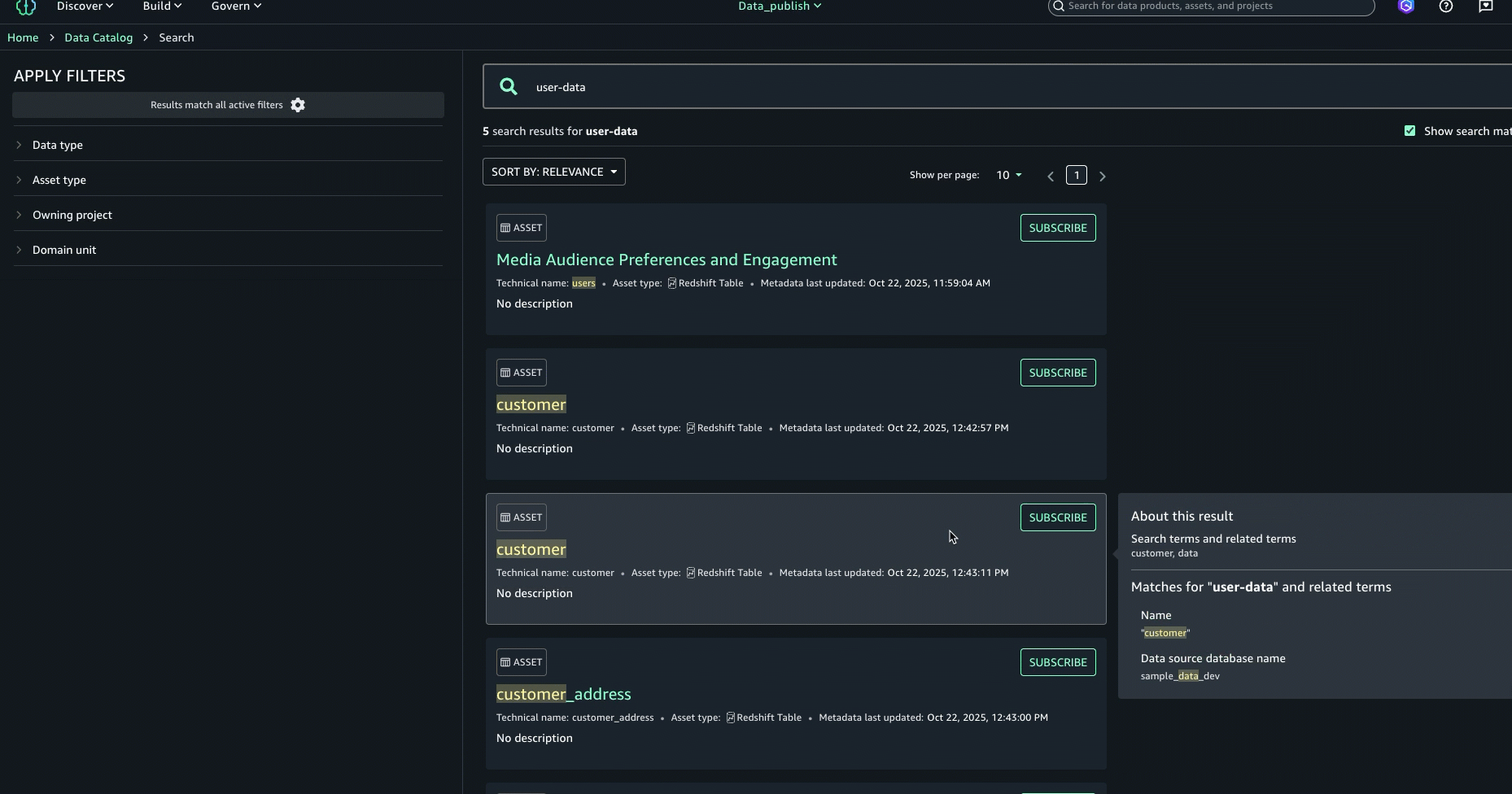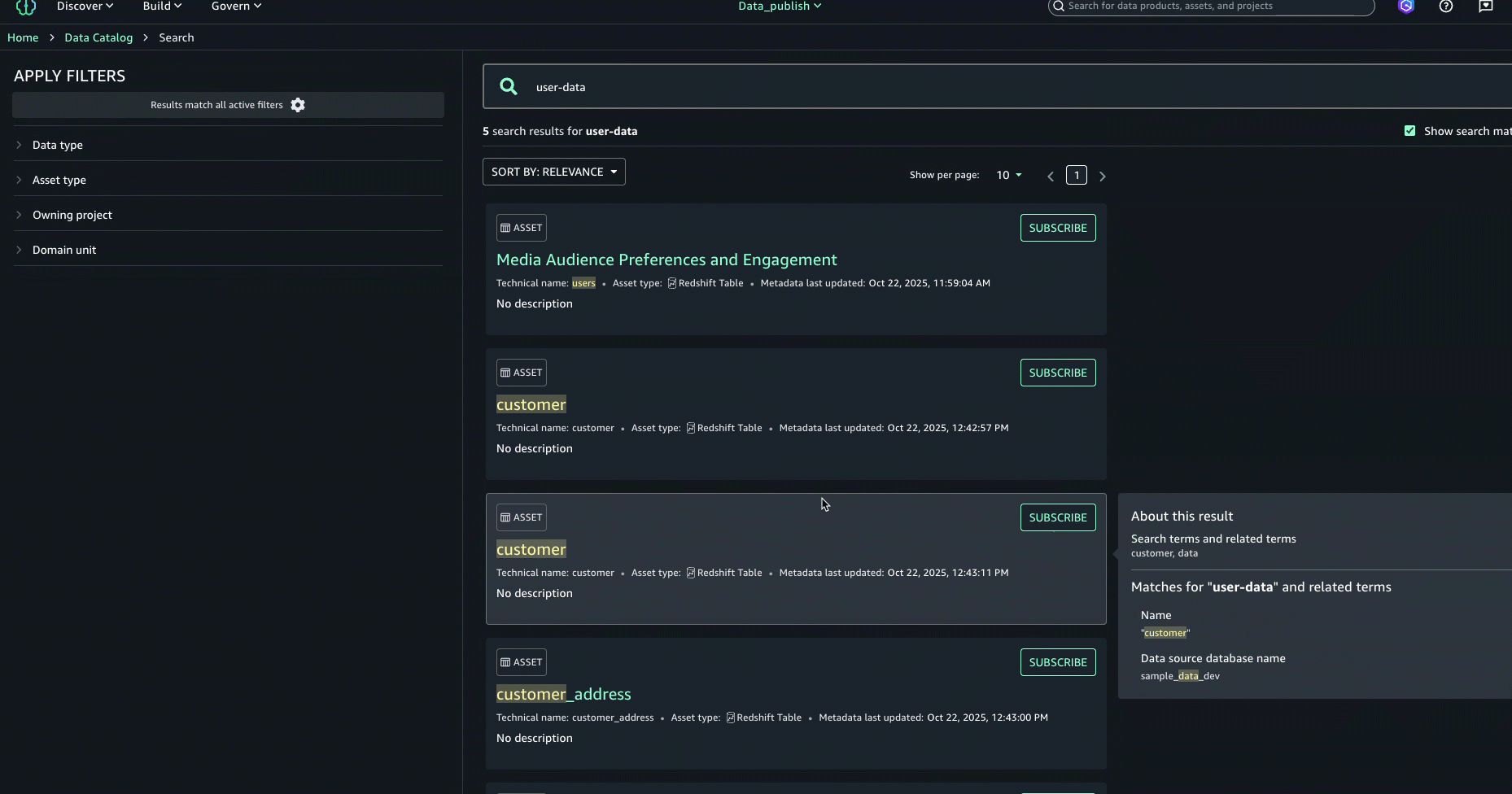
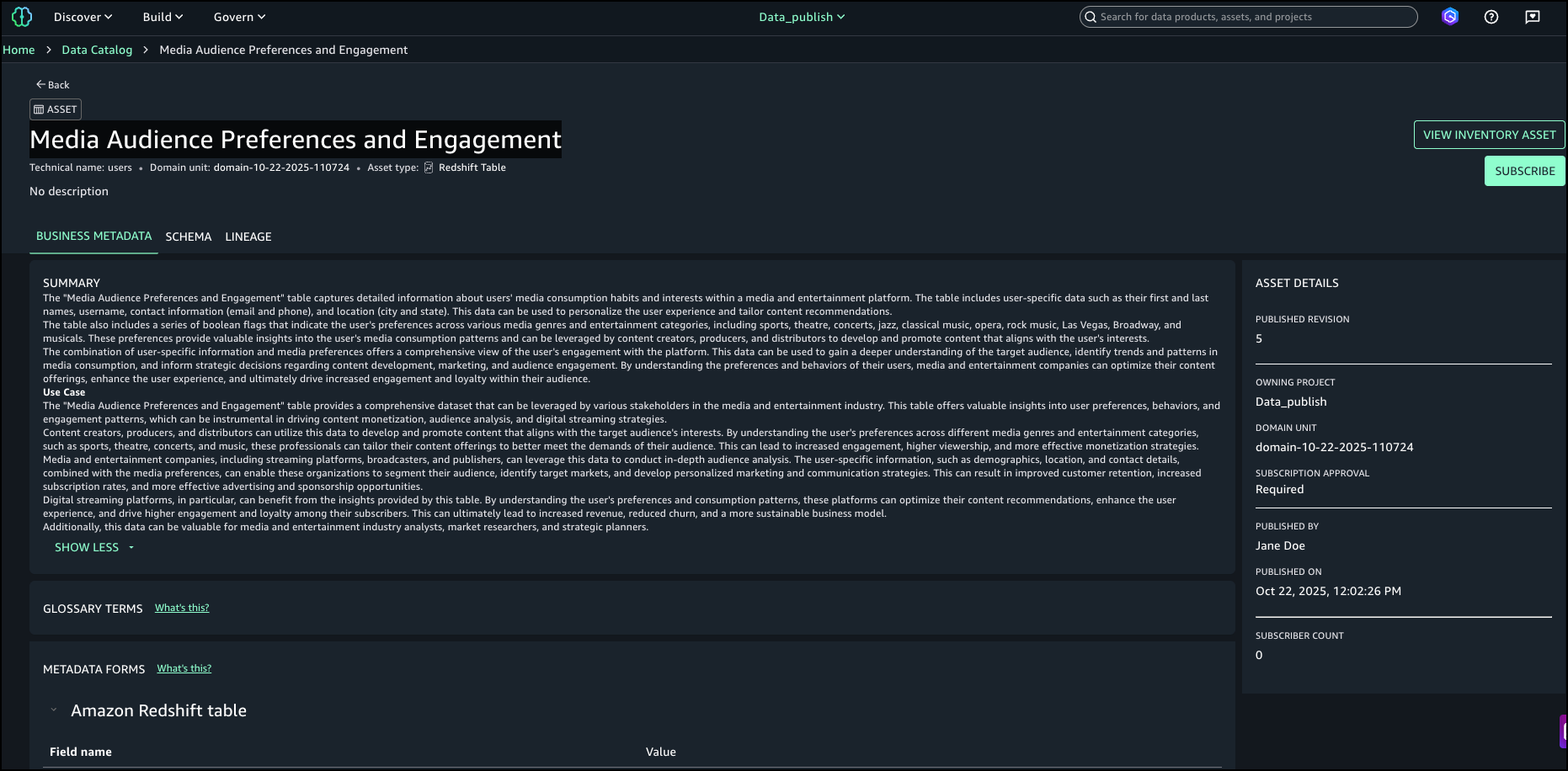
Por exemplo, um administrador pesquisa “previsão de receita” e um ativo é retornado com o nome “Conjunto de dados de previsão de vendas Q2” e uma descrição que contém “valores de vendas projetados”. A palavra vendas é destacado no nome e na descrição, tanto no resultado da pesquisa quanto no painel de correspondências de texto, porque vendas é sinônimo de receita. O painel Sobre este resultado também mostra que a previsão foi correspondida no nome do campo do esquema previsão_de vendas_q2.
Visão geral da solução
Nesta seção demonstramos como usar os recursos de pesquisa aprimorados. Neste exemplo, demonstraremos o uso em uma campanha de advertising and marketing onde precisamos de dados de preferência do usuário. Embora tenhamos vários conjuntos de dados sobre usuários, demonstraremos como a pesquisa aprimorada simplifica a experiência de descoberta.
Pré-requisitos
Para testar esta solução você deve ter um Estúdio unificado Amazon SageMaker domínio configurado com privilégios de proprietário de domínio ou proprietário de unidade de domínio. Você também deve ter um projeto existente para publicar ativos e catalogar ativos. Para obter instruções sobre como criar esses ativos, consulte o Começando guia.
Neste exemplo, criamos um projeto chamado Data_publish e carregamos dados do Amazon Redshift banco de dados de amostra. Para ingerir os dados de amostra no Catálogo SageMaker e gerar metadados de negócios, consulte Crie uma fonte de dados do Amazon SageMaker Unified Studio para o Amazon Redshift no catálogo de projetos.
Descoberta de ativos com pesquisa explicável
Para encontrar ativos com pesquisa explicável:
- Faça login no SageMaker Unified Studio.

- Digite o texto de pesquisa
user-data. Embora obtenhamos os resultados da pesquisa nesta visualização, queremos obter mais detalhes sobre cada um desses conjuntos de dados. Pressione Enter para ir para a pesquisa completa.
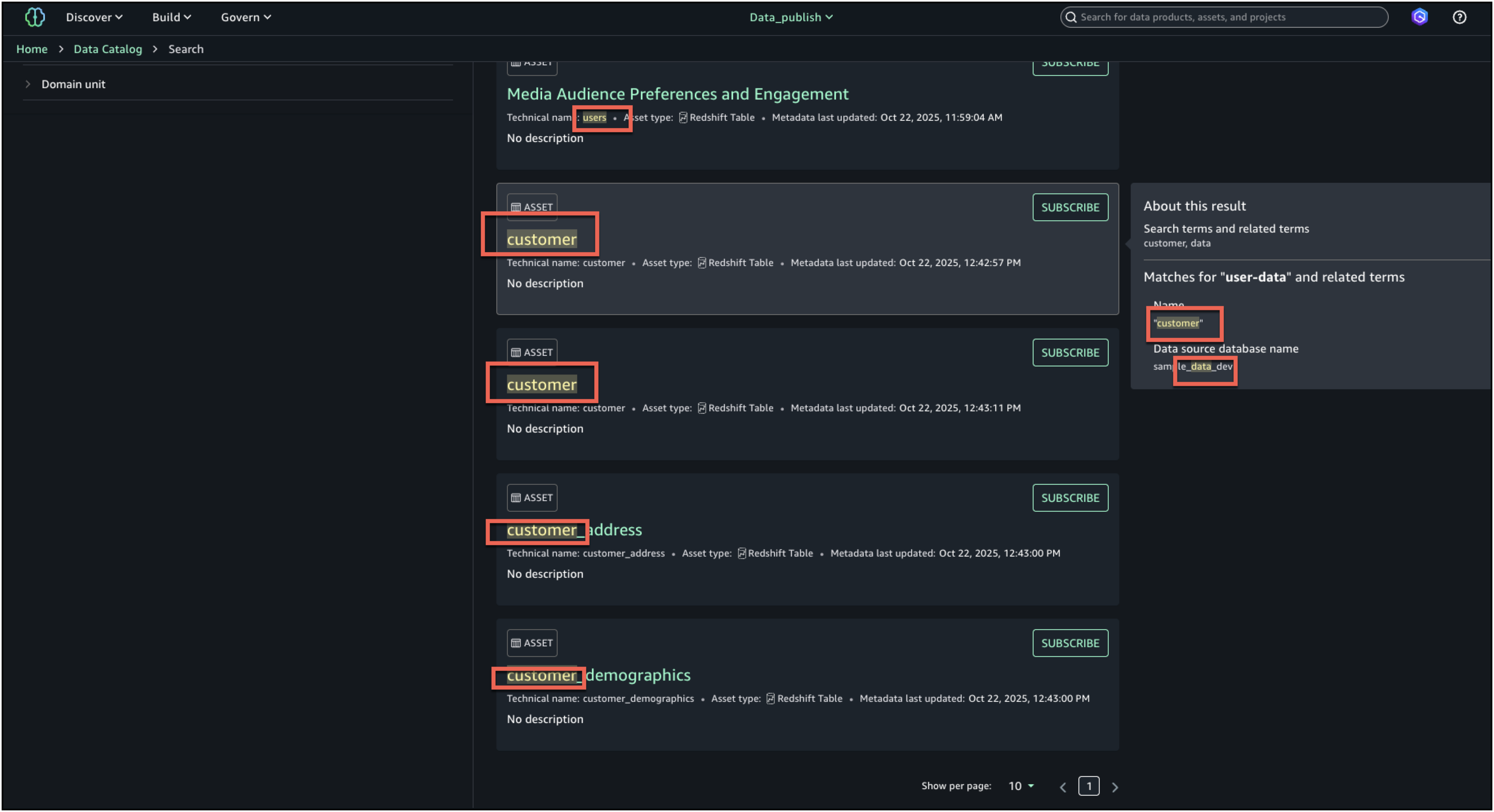
- Na pesquisa completa, os resultados da pesquisa são retornados quando há correspondências de texto com base na pesquisa por palavra-chave, início com, sinônimo e pesquisa semântica. As correspondências de texto são destacadas no conteúdo pesquisável mostrado para cada resultado: no nome, na descrição e nos termos do glossário.

- Para aprimorar ainda mais a experiência de descoberta e encontrar o ativo certo, você pode consultar o Sobre este resultado painel à direita e veja as outras correspondências de texto, por exemplo, no resumo, nome da tabela, nome do banco de dados da fonte de dados ou nome comercial da coluna, para entender melhor por que o resultado foi incluído.

- Depois de examinar os resultados da pesquisa e as explicações de correspondência de texto, identificamos o ativo denominado
Media Viewers Preferences and Engagementcomo o ativo certo para a campanha e o selecionou para análise.

Conclusão
A transparência aprimorada da pesquisa no Amazon SageMaker Unified Studio transforma a descoberta de dados, fornecendo visibilidade clara sobre por que os ativos aparecem nos resultados da pesquisa. O destaque in-line e as explicações detalhadas de correspondência ajudam os usuários a identificar rapidamente conjuntos de dados relevantes, ao mesmo tempo que criam confiança no catálogo de dados. Ao mostrar exatamente quais campos de metadados correspondem às suas consultas, os usuários gastam menos tempo avaliando ativos irrelevantes e mais tempo analisando os dados certos para seus projetos.
A pesquisa aprimorada agora está disponível nas regiões da AWS onde o Amazon SageMaker é compatível.
Para saber mais sobre o Amazon SageMaker, consulte Amazon SageMaker documentação.