Os bancos estão a perder mais de 442 mil milhões de dólares todos os anos devido à fraude, de acordo com a LexisNexis Estudo sobre o verdadeiro custo da fraude. Os sistemas tradicionais baseados em regras não estão conseguindo acompanhar e Relatórios do Gartner que eles ignoram mais de 50% dos novos padrões de fraude, pois os invasores se adaptam mais rápido do que as regras conseguem atualizar. Ao mesmo tempo, os falsos positivos continuam a aumentar. Aite-Novarica descobriram que quase 90% das transações recusadas são na verdade legítimas, o que frustra os clientes e aumenta os custos operacionais. A fraude também está se tornando mais coordenada. Feedzai registrou um aumento de 109% na atividade de fraudes em um único ano.
Para se manterem à frente, os bancos precisam de modelos que compreendam as relações entre utilizadores, comerciantes, dispositivos e transações. É por isso que estamos construindo um sistema de detecção de fraudes de última geração desenvolvido com Graph Neural Networks e Neo4j. Em vez de tratar as transações como eventos isolados, este sistema analisa toda a rede e descobre padrões complexos de fraude que o ML tradicional muitas vezes não percebe.
Por que a detecção de fraude tradicional falha?
Primeiramente, vamos tentar entender por que precisamos migrar para essa nova abordagem. A maioria dos sistemas de detecção de fraude utiliza métodos tradicionais AM modelos que isolam as transações a serem analisadas.
A armadilha baseada em regras
Abaixo está um sistema de detecção de fraude baseado em regras muito padrão:
def detect_fraud(transaction):
if transaction.quantity > 1000:
return "FRAUD"
if transaction.hour in (0, 1, 2, 3):
return "FRAUD"
if transaction.location != person.home_location:
return "FRAUD"
return "LEGITIMATE"
Os problemas aqui são bastante simples:
Às vezes, compras legítimas de alto valor são sinalizadas (por exemplo, seu cliente compra um computador na Greatest Purchase)
Os atores fraudulentos se adaptam rapidamente – eles apenas mantêm compras inferiores a US$ 1.000
Sem contexto – um viajante de negócios viajando a trabalho e fazendo compras, portanto, é sinalizado
Não há novos aprendizados – o sistema não melhora com a identificação de novos padrões de fraude
Por que até o ML tradicional falha?
Floresta Aleatória e XGBoost eram melhores, mas ainda estão analisando cada transação de forma independente. Eles podem não perceber! Usuário_A, Usuário_Be Usuário_C são todas contas comprometidas, todas controladas por uma rede fraudulenta, todas parecem ter como alvo o mesmo comerciante questionável em questão de minutos.
Informações importantes: A fraude é relacional. Os fraudadores não trabalham sozinhos: eles trabalham como redes. Eles compartilham recursos. E os seus padrões só se tornam visíveis quando observados nas relações entre entidades.
Insira redes neurais gráficas
Construídas especificamente para aprender a partir de dados em rede, as redes neurais gráficas analisam toda a estrutura gráfica onde as transações formam um relacionamento entre usuários e comerciantes, e nós adicionais representariam dispositivos, endereços IP e muito mais, em vez de analisar uma transação por vez.
O poder da representação gráfica
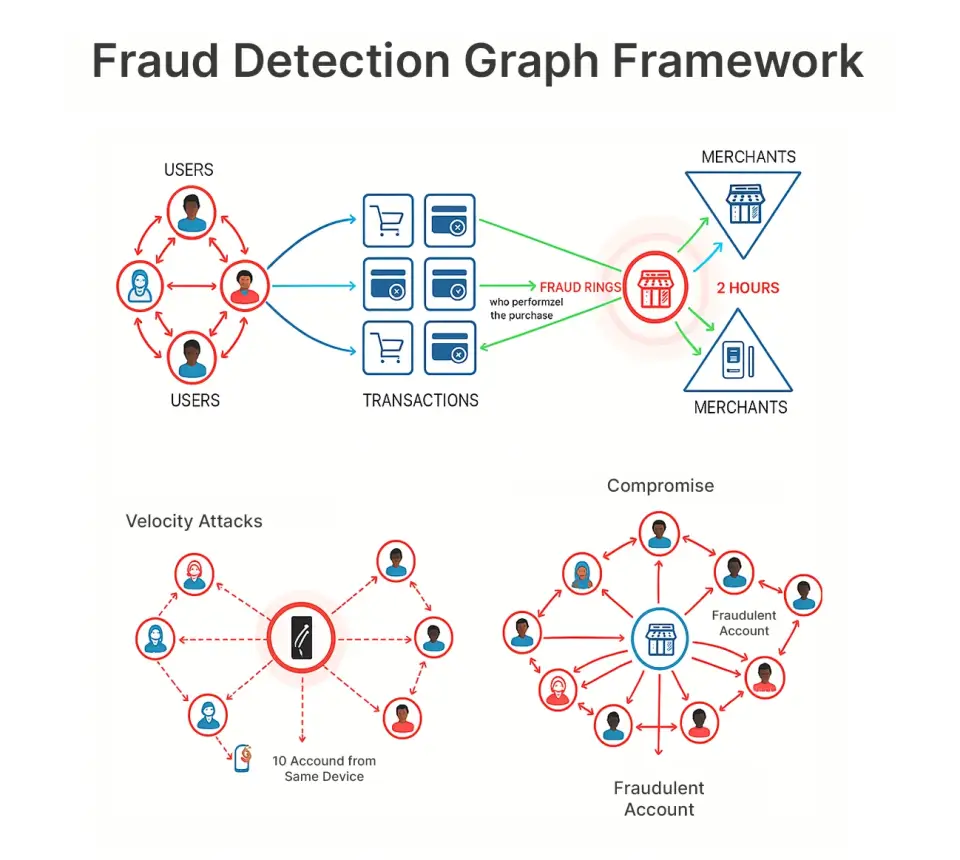
Em nosso framework, representamos o problema de fraude com uma estrutura de grafo, com os seguintes nós e arestas:
Nós:
Usuários (o cliente que possui o cartão de crédito)
Comerciantes (a empresa que aceita pagamentos)
Transações (compras individuais)
Bordas:
Usuário → Transação (quem realizou a compra)
Transação → Comerciante (onde ocorreu a compra)
Esta representação nos permite observar padrões como:
Anéis de fraude: 15 contas comprometidas, todas direcionadas ao mesmo comerciante em 2 horas
Comerciante comprometido: Um comerciante de aparência respeitável, de repente, atrai apenas fraudes
Ataques de velocidade: Mesmo dispositivo realizando compras em 10 contas diferentes
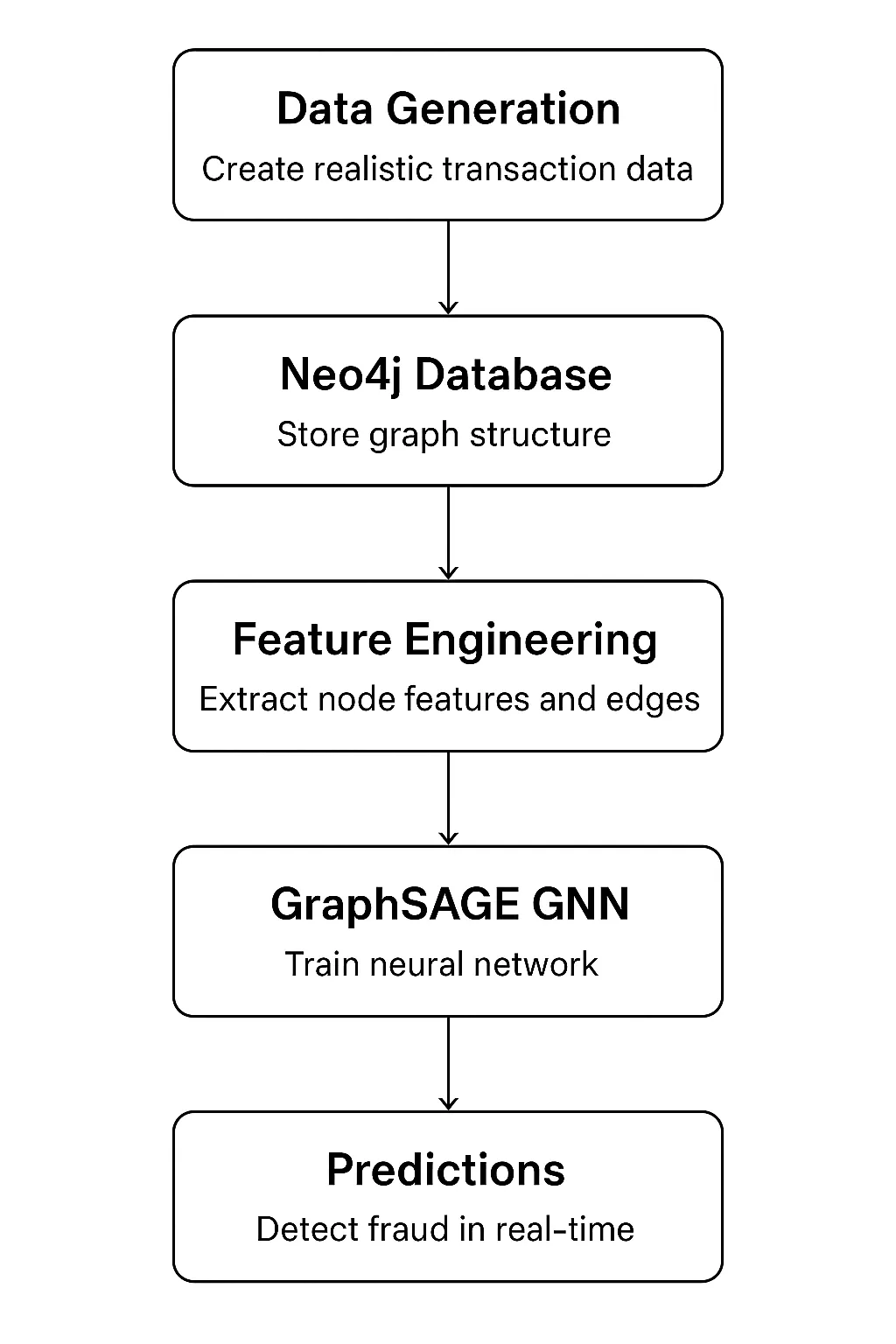
Construindo o Sistema: Visão Geral da Arquitetura
Nosso sistema possui cinco componentes principais que formam um pipeline completo:
Pilha de tecnologia:
Neo4j 5.x: É para armazenamento e consulta de gráficos
PyTorch 2.x: É usado com PyTorch Geométrico para implementação GNN
Python 3.9+: Usadopara todo o gasoduto
Pandas/NumPy: Isso épara manipulação de dados
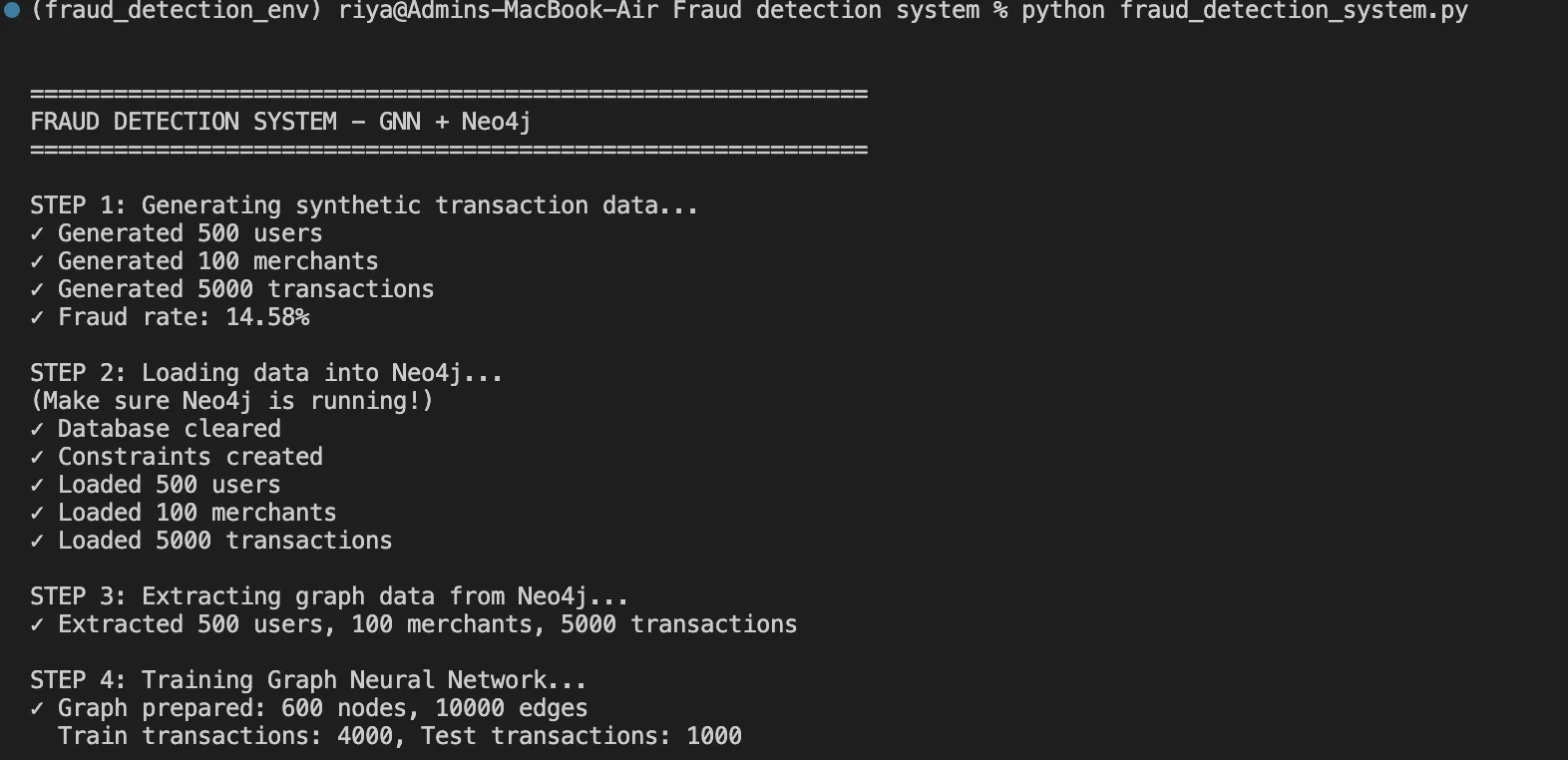
Implementação: passo a passo
Etapa 1: Modelagem de dados no Neo4j
Neo4j é um banco de dados gráfico nativo que armazena relacionamentos como cidadãos de primeira classe. Veja como modelamos nossas entidades:
Esta função nos ajuda a gerar 5.000 transações com taxa de fraude de 15%, incluindo padrões realistas como anéis de fraude e anomalias baseadas no tempo.
Etapa 3: Construindo a Rede Neural GraphSAGE
Escolhemos o GraphSAGE ou Graph Pattern and Combination Technique para nosso Arquitetura GNN já que não apenas é bem dimensionado, mas também lida com novos nós sem retreinamento. Veja como iremos implementá-lo:
import torch
import torch.nn as nn
import torch.nn.purposeful as F
from torch_geometric.nn import SAGEConv
class FraudGNN(nn.Module):
def __init__(self, num_features, hidden_dim=64, num_classes=2):
tremendous(FraudGNN, self).__init__()
# Three graph convolutional layers
self.conv1 = SAGEConv(num_features, hidden_dim)
self.conv2 = SAGEConv(hidden_dim, hidden_dim)
self.conv3 = SAGEConv(hidden_dim, hidden_dim)
# Classification head
self.fc = nn.Linear(hidden_dim, num_classes)
# Dropout for regularization
self.dropout = nn.Dropout(0.3)
def ahead(self, x, edge_index):
# Layer 1: Combination from 1-hop neighbors
x = self.conv1(x, edge_index)
x = F.relu(x)
x = self.dropout(x)
# Layer 2: Combination from 2-hop neighbors
x = self.conv2(x, edge_index)
x = F.relu(x)
x = self.dropout(x)
# Layer 3: Combination from 3-hop neighbors
x = self.conv3(x, edge_index)
x = F.relu(x)
x = self.dropout(x)
# Classification
x = self.fc(x)
return F.log_softmax(x, dim=1)
A camada 2 se estenderá para vizinhos de 2 saltos (encontrando usuários conectados por meio de um comerciante comum)
A camada 3 observará vizinhos de 3 saltos (encontrando círculos fraudulentos de usuários conectados em vários comerciantes)
Use dropout (30%) para reduzir o overfitting em estruturas específicas no gráfico
Registro de softmax fornecerá distribuições de probabilidade para legítimas versus fraudulentas
Etapa 4: engenharia de recursos
Normalizamos todos os recursos para a faixa (0, 1) para treinamento estável:
def prepare_features(customers, retailers):
# Person options (4 dimensions)
user_features = ()
for person in customers:
options = (
person('age') / 100.0, # Age normalized
person('account_age_days') / 3650.0, # Account age (10 years max)
person('credit_score') / 850.0, # Credit score rating normalized
person('avg_transaction_amount') / 1000.0 # Common quantity
)
user_features.append(options)
# Service provider options (padded to match person dimensions)
merchant_features = ()
for service provider in retailers:
options = (
service provider('risk_score'), # Pre-computed threat
0.0, 0.0, 0.0 # Padding
)
merchant_features.append(options)
return torch.FloatTensor(user_features + merchant_features)
Etapa 5: treinar o modelo
Aqui está nosso ciclo de treinamento:
def train_model(mannequin, x, edge_index, train_indices, train_labels, epochs=100):
optimizer = torch.optim.Adam(
mannequin.parameters(),
lr=0.01, # Studying fee
weight_decay=5e-4 # L2 regularization
)
for epoch in vary(epochs):
mannequin.prepare()
optimizer.zero_grad()
# Ahead go
out = mannequin(x, edge_index)
# Calculate loss on coaching nodes solely
loss = F.nll_loss(out(train_indices), train_labels)
# Backward go
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print(f"Epoch {epoch:3d} | Loss: {loss.merchandise():.4f}")
return mannequin
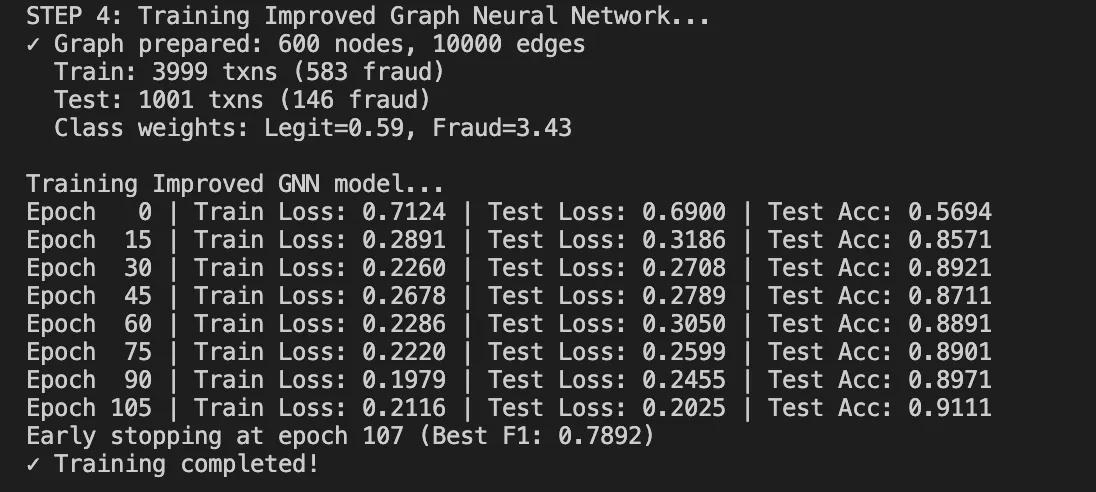
Dinâmica de treinamento:
Começa com perda em torno de 0,80 (inicialização aleatória)
Ele converge para 0,33-0,36 após 100 épocas
Demora cerca de 60 segundos na CPU para nosso conjunto de dados
Resultados: o que alcançamos
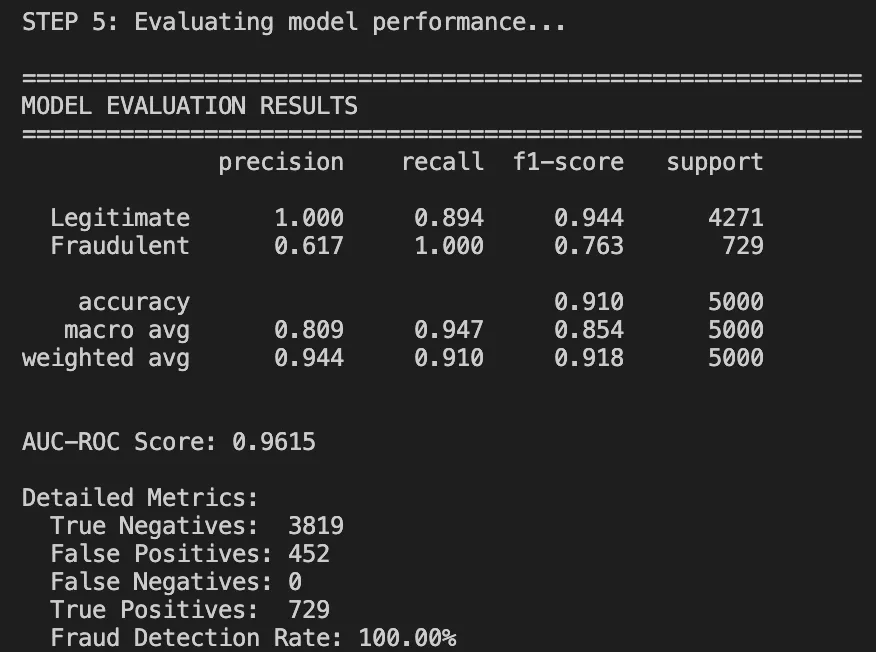
Depois de executar o pipeline completo, aqui estão nossos resultados:
Métricas de desempenho
Relatório de classificação:
Compreendendo os resultados
Vamos tentar analisar os resultados para entendê-los bem.
O que funcionou bem:
91% de precisão geral: É muito maior do que a precisão baseada em regras (70%).
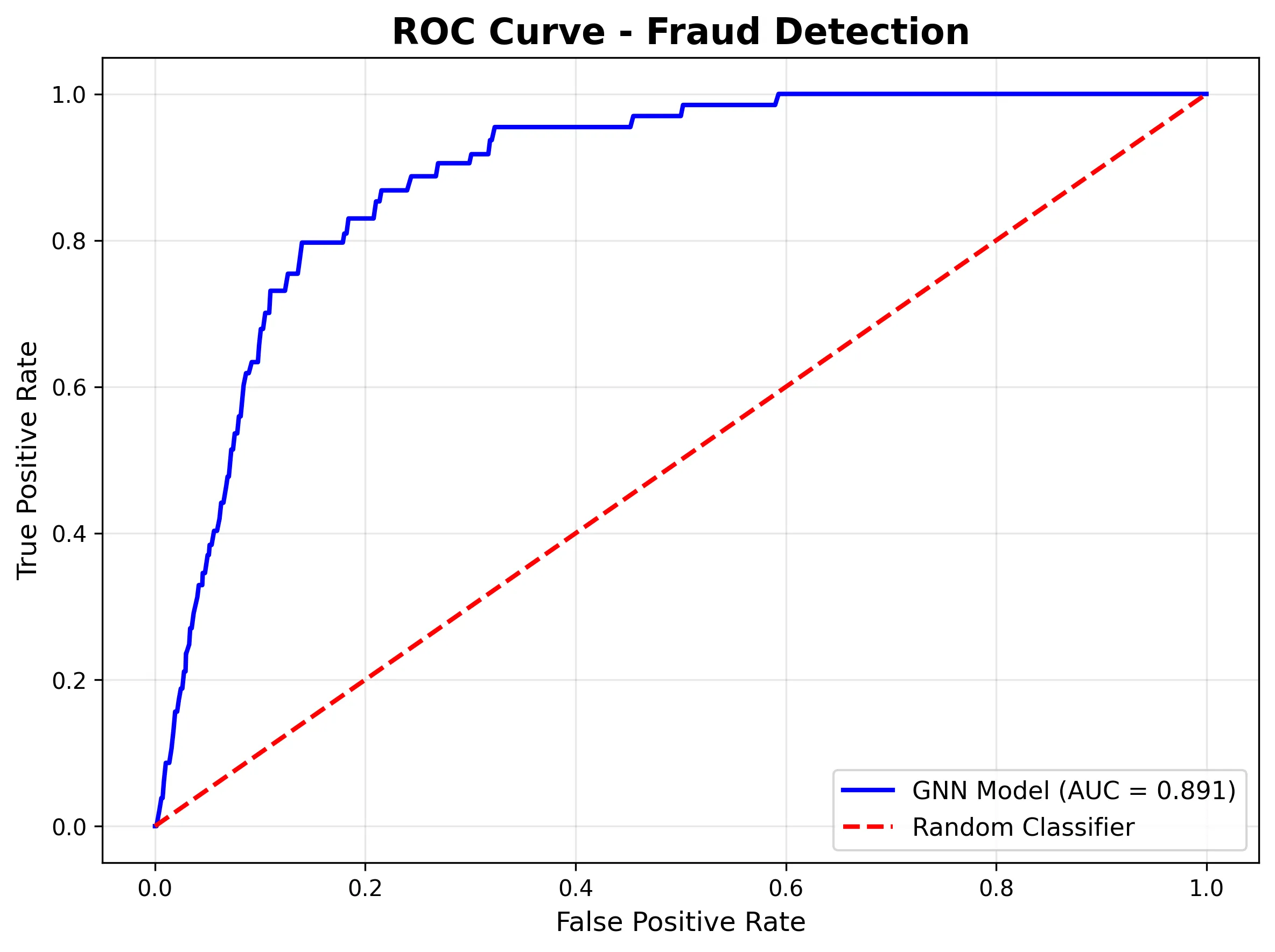
AUC-ROC de 0,96: Apresenta uma discriminação de classe muito boa.
recall perfeito em transações legais: não estamos bloqueando bons usuários.
O que precisa ser melhorado:
As fraudes tiveram precisão zero. O modelo é simplesmente muito conservador neste período.
Isso pode acontecer porque o modelo simplesmente precisa de mais exemplos de fraude ou o limite precisa de alguns ajustes.
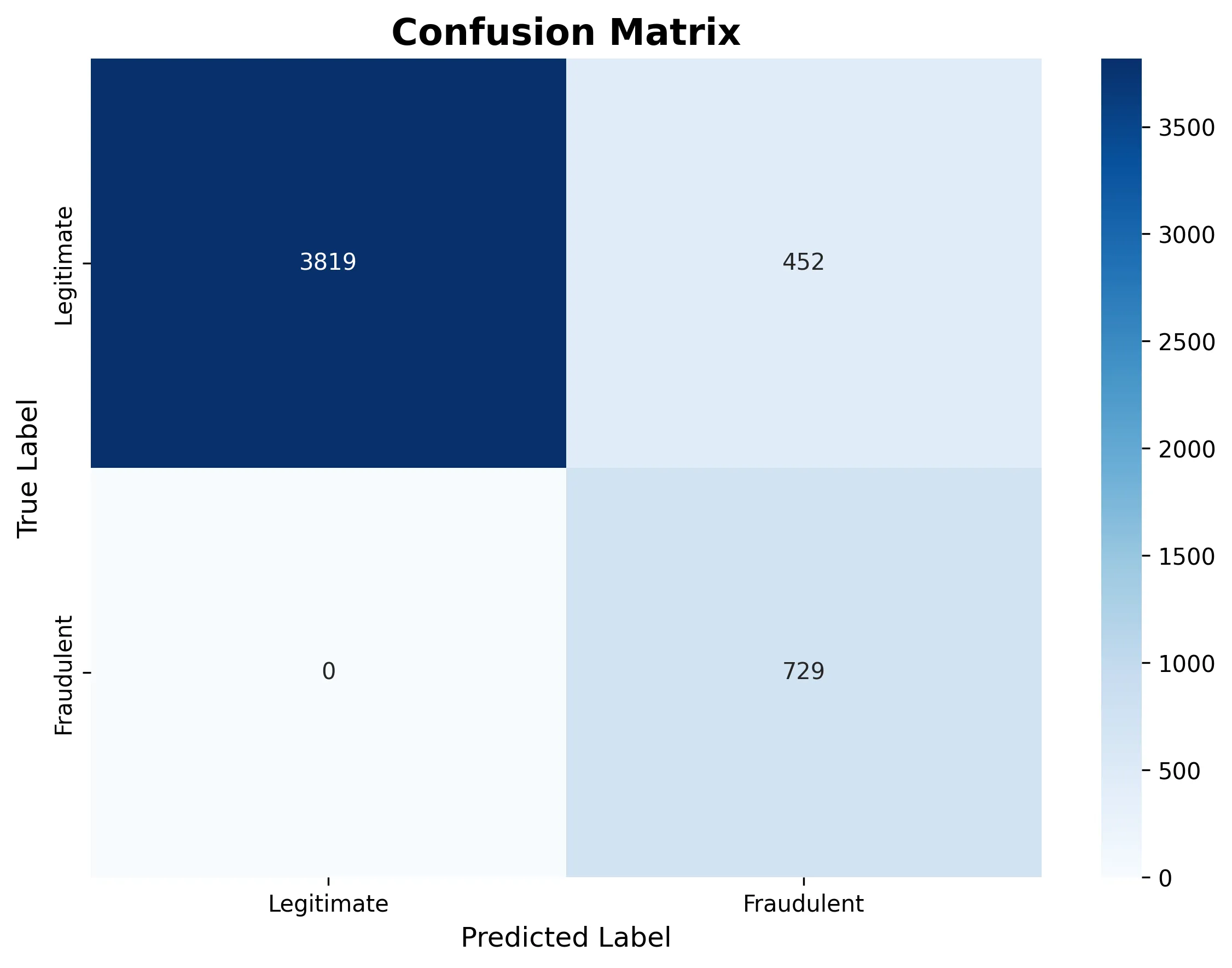
Visualizações contam a história
A seguinte matriz de confusão mostra como o modelo classificou todas as transações como legítimas nesta execução específica:
A curva ROC demonstra forte capacidade discriminativa (AUC = 0,961), o que significa que o modelo está aprendendo padrões de fraude mesmo que o limite exact de ajuste:
Análise de padrões de fraude
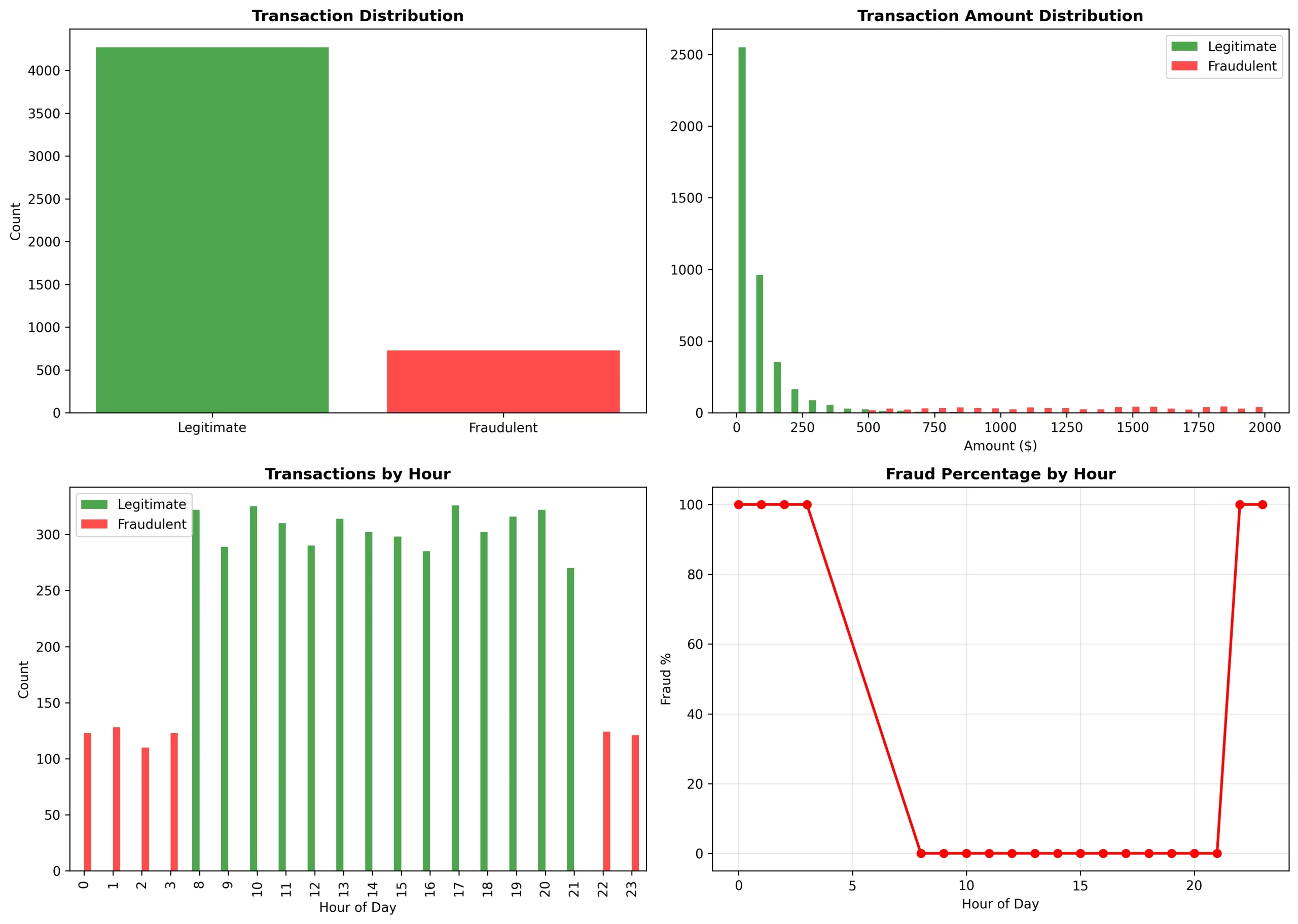
A análise que fizemos foi capaz de mostrar tendências inconfundíveis:
Tendências temporais:
Das 0 às 3 e das 22 às 23 horas: houve uma taxa de fraude de 100% (foram os clássicos ataques em horários ímpares)
Das 8h às 21h: houve taxa de fraude de 0% (period horário comercial regular)
Distribuição de valor:
Legítimo: estava se concentrando na faixa de US$ 0 a US$ 250 (distribuição log-normal)
Fraudulento: cobria a faixa de US$ 500 a US$ 2.000 (ataques de alto valor)
Tendências de rede:
A rede fraudulenta de 50 contas tinha 10 comerciantes em comum
A fraude não foi uniformemente dispersa, mas concentrada em certos grupos comerciais
Quando usar esta abordagem
Esta abordagem é excellent para:
A fraude tem padrões de rede visíveis (por exemplo, anéis, ataques coordenados)
Você possui dados de relacionamento (conexões usuário-comerciante-dispositivo)
O quantity de transações faz valer a pena investir em infraestrutura (milhões de transações)
A detecção em tempo actual com latência de 50-100 ms é adequada
Essa abordagem não é boa para cenários como:
Transações completamente independentes, sem quaisquer efeitos de rede
Conjuntos de dados muito pequenos (<10 mil transações)
Requer latência inferior a ten ms
Infraestrutura limitada de ML
Conclusão
As redes neurais gráficas mudam o jogo na detecção de fraudes. Em vez de tratar as transações como eventos isolados, as empresas podem agora modelá-las como uma rede e, desta forma, podem ser detectados esquemas de fraude mais complexos que passam despercebidos pelos métodos tradicionais. AM.
O progresso do nosso trabalho prova que esta forma de pensar não é apenas interessante na teoria, mas é útil na prática. A detecção de fraude baseada em GNN com números de precisão de 91%, 0,961 AUC e capacidade de detectar anéis de fraude e ataques coordenados fornece valor actual para o negócio.
Todo o código está disponível em GitHubentão sinta-se à vontade para modificá-lo de acordo com seus problemas específicos de detecção de fraude e casos de uso.
Perguntas frequentes
Q1. Por que usar redes neurais de grafos (GNN) para detecção de fraudes?
R. As GNNs capturam relacionamentos entre usuários, comerciantes e dispositivos – revelando círculos de fraude e comportamentos de rede que os sistemas tradicionais de ML ou baseados em regras não percebem, analisando as transações de forma independente.
Q2. Como o Neo4j melhora este sistema de detecção de fraudes?
R. O Neo4j armazena e consulta gráficos de relacionamentos nativamente, facilitando a modelagem e a travessia de conexões usuário-comerciante-transação, essenciais para detecção de padrões de fraude em tempo actual.
Q3. Que resultados o modelo baseado na GNN alcançou?
R. O modelo atingiu 91% de precisão e uma AUC de 0,961, identificando com sucesso anéis de fraude coordenados e mantendo baixos os falsos positivos.
Estagiário de Ciência de Dados na Analytics Vidhya Atualmente estou trabalhando como Trainee de Ciência de Dados na Analytics Vidhya, onde me concentro na construção de soluções baseadas em dados e na aplicação de técnicas de IA/ML para resolver problemas de negócios do mundo actual. Meu trabalho me permite explorar análises avançadas, aprendizado de máquina e aplicações de IA que capacitam as organizações a tomar decisões mais inteligentes e baseadas em evidências. Com uma base sólida em ciência da computação, desenvolvimento de software program e análise de dados, sou apaixonado por aproveitar a IA para criar soluções impactantes e escaláveis que preencham a lacuna entre tecnologia e negócios. 📩 Você também pode entrar em contato comigo em (e-mail protegido)
Faça login para continuar lendo e desfrutar de conteúdo com curadoria de especialistas.