A geração aumentada de recuperação está mudando a maneira como os LLMs exploram o conhecimento externo. O problema é que muitos desenvolvedores não entendem o que o RAG realmente faz. Eles se concentram no documento que está no armazenamento de vetores e presumem que a mágica começa e termina com sua recuperação. Mas indexação e recuperação não são a mesma coisa.
A indexação trata de como você escolhe representar o conhecimento. A recuperação trata de quais partes desse conhecimento o modelo consegue ver. Depois de reconhecer essa lacuna, todo o quadro muda. Você começa a perceber quanto controle realmente tem sobre o raciocínio, a velocidade e o aterramento do modelo.
Este guia detalha o que a indexação RAG realmente significa e apresenta maneiras práticas de projetar estratégias de indexação que realmente ajudem seu sistema a pensar melhor, e não apenas a buscar texto.
O que é indexação RAG?
pano a indexação é a base da recuperação. É o processo de transformar o conhecimento bruto em dados numéricos que podem então ser pesquisados por meio de consultas de similaridade. Esses dados numéricos são chamados de embeddings, e os embeddings capturam significado, em vez de apenas texto de nível superficial.
")
Considere isso como construir um mapa semântico pesquisável de sua base de conhecimento. Cada pedaço, resumo ou variante de uma consulta torna-se um ponto ao longo do mapa. Quanto mais organizado for esse mapa, melhor o seu recuperador poderá identificar o conhecimento relevante quando um usuário fizer uma pergunta.
Se sua indexação estiver desativada, como se seus pedaços forem muito grandes, os embeddings estiverem capturando ruído ou sua representação dos dados não representar a intenção do usuário, nenhum LLM o ajudará muito. A qualidade da recuperação sempre dependerá da eficácia com que os dados são indexados, e não da qualidade da sua indexação. aprendizado de máquina modelo é.
Por que isso é importante?
Você não está limitado a recuperar apenas o que indexa. O poder do seu sistema RAG é a eficácia com que o seu índice reflete o significado e não o texto. A indexação articula o quadro através do qual o seu recuperador vê o conhecimento.
Quando você combina sua estratégia de indexação com seus dados e com as necessidades do usuário, a recuperação se tornará mais nítida, os modelos terão menos alucinações e o usuário obterá conclusões precisas. Um índice bem projetado transforma o RAG de um pipeline de recuperação em um verdadeiro mecanismo de raciocínio semântico.
Estratégias de indexação RAG que realmente funcionam
Suponha que temos um documento sobre programação Python:
Doc = """ Python is a flexible programming language extensively utilized in information science, machine studying, and net improvement. It helps a number of paradigms and has a wealthy ecosystem of libraries like NumPy, pandas, and TensorFlow. """ Agora, vamos explorar quando usar cada estratégia de indexação RAG de maneira eficaz e como implementá-la para tal conteúdo para construir um sistema de recuperação de desempenho.
1. Indexação de pedaços
Este é o ponto de partida para a maioria dos pipelines RAG. Você divide documentos grandes em pedaços menores e semanticamente coerentes e incorpora cada um deles usando algum modelo de incorporação. Esses embeddings são então armazenados em um banco de dados vetorial.
Código de exemplo:
# 1. Chunk Indexing
def chunk_indexing(doc, chunk_size=100):
phrases = doc.break up()
chunks = ()
current_chunk = ()
current_len = 0
for phrase in phrases:
current_len += len(phrase) + 1 # +1 for house
current_chunk.append(phrase)
if current_len >= chunk_size:
chunks.append(" ".be a part of(current_chunk))
current_chunk = ()
current_len = 0
if current_chunk:
chunks.append(" ".be a part of(current_chunk))
chunk_embeddings = (embed(chunk) for chunk in chunks)
return chunks, chunk_embeddings
chunks, chunk_embeddings = chunk_indexing(doc_text, chunk_size=50)
print("Chunks:n", chunks)Melhores práticas:
- Sempre mantenha os pedaços em torno de 200-400 tokens para texto curto ou 500-800 para conteúdo técnico longo.
- Certifique-se de evitar dividir frases intermediárias ou parágrafos intermediários, use pontos de quebra lógicos e semânticos para melhor fragmentação.
- É bom usar janelas sobrepostas (20-30%) para que o contexto nos limites não seja perdido.
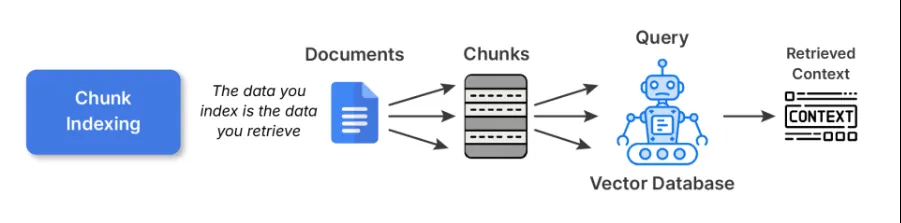
Compensações: A indexação de pedaços é uma indexação simples e de uso geral. No entanto, pedaços maiores podem prejudicar a precisão da recuperação, enquanto pedaços menores podem fragmentar o contexto e sobrecarregar o LLM com peças que não se encaixam.
Leia mais: Construir pipeline RAG usando LlamaIndex
2. Indexação de subbloco
A indexação de subblocos serve como uma camada de refinamento sobre a indexação de blocos. Ao incorporar os pedaços normais, você divide ainda mais o pedaço em subpedaços menores. Ao procurar recuperar, você compara os subblocos com a consulta e, quando esse subbloco corresponde à sua consulta, o bloco pai completo é inserido no LLM.
Por que isso funciona:
Os subblocos proporcionam a capacidade de pesquisar de maneira mais precisa, sutil e exata, ao mesmo tempo que mantêm o amplo contexto necessário para o raciocínio. Por exemplo, você pode ter um longo artigo de pesquisa, e o subparte de um conteúdo desse artigo pode ser a explicação de uma fórmula em um longo parágrafo, melhorando assim a precisão e a interpretabilidade.
Código de exemplo:
# 2. Sub-chunk Indexing
def sub_chunk_indexing(chunk, sub_chunk_size=25):
phrases = chunk.break up()
sub_chunks = ()
current_sub_chunk = ()
current_len = 0
for phrase in phrases:
current_len += len(phrase) + 1
current_sub_chunk.append(phrase)
if current_len >= sub_chunk_size:
sub_chunks.append(" ".be a part of(current_sub_chunk))
current_sub_chunk = ()
current_len = 0
if current_sub_chunk:
sub_chunks.append(" ".be a part of(current_sub_chunk))
return sub_chunks
# Sub-chunks for first chunk (as instance)
sub_chunks = sub_chunk_indexing(chunks(0), sub_chunk_size=30)
sub_embeddings = (embed(sub_chunk) for sub_chunk in sub_chunks)
print("Sub-chunks:n", sub_chunks)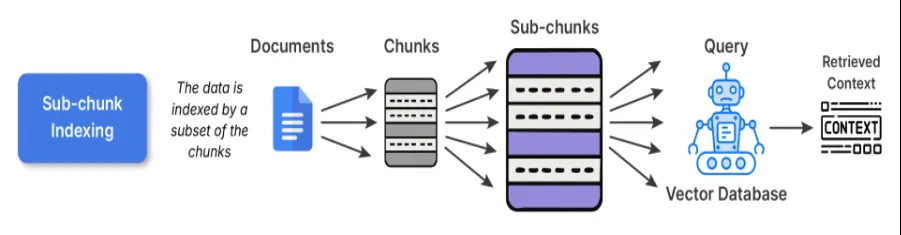
Quando usar: Isto seria vantajoso para conjuntos de dados que contêm múltiplas ideias distintas em cada parágrafo; por exemplo, se você considerar bases de conhecimento como livros didáticos, artigos de pesquisa, and so forth., isso seria o ideally suited.
Troca: O custo é um pouco maior para pré-processamento e armazenamento devido aos embeddings sobrepostos, mas possui um alinhamento substancialmente melhor entre consulta e conteúdo.
3. Indexação de consultas
No caso da indexação de consultas, o texto bruto não é incorporado diretamente. Em vez disso, criamos várias perguntas imaginárias que cada parte poderia responder e, em seguida, incorporamos esse texto. Isso é feito parcialmente para preencher a lacuna semântica de como os usuários perguntam e como seus documentos descrevem as coisas.
Por exemplo, se o seu pedaço disser:
“LangChain possui utilitários para construção de pipelines RAG”
O modelo geraria consultas como:
- Como faço para construir um pipeline RAG em LangChain?
- Quais ferramentas de recuperação o LangChain possui?
Então, quando qualquer usuário actual fizer uma pergunta semelhante, a recuperação atingirá diretamente uma dessas consultas indexadas.
Código de exemplo:
# 3. Question Indexing - generate artificial queries associated to the chunk
def generate_queries(chunk):
# Easy artificial queries for demonstration
queries = (
"What's Python used for?",
"Which libraries does Python assist?",
"What paradigms does Python assist?"
)
query_embeddings = (embed(q) for q in queries)
return queries, query_embeddings
queries, query_embeddings = generate_queries(doc_text)
print("Artificial Queries:n", queries)Melhores práticas:
- Ao escrever consultas de índice, sugiro usar LLMs para produzir de 3 a 5 consultas por bloco.
- Você também pode desduplicar ou agrupar todas as questões que diminuem o índice actual.

Quando usar:
- Sistemas de perguntas e respostas ou um chatbot onde a maioria das interações do usuário é orientada por perguntas em linguagem pure.
- Experiência de pesquisa em que o usuário provavelmente perguntará o que, como ou por que digita as consultas.
Troca: Embora a expansão sintética acrescente tempo e espaço de pré-processamento, ela fornece um aumento significativo na relevância da recuperação para sistemas voltados para o usuário.
4. Indexação resumida
A indexação de resumo permite reformular partes do materials em resumos menores antes de incorporá-los. Você retém o conteúdo completo em outro native e, em seguida, a recuperação é feita nas versões resumidas.
Por que isso é benéfico:
Estruturas, materiais de origem densos ou repetitivos (como planilhas, documentos de políticas, manuais técnicos) em geral são materiais cuja incorporação diretamente da versão em texto bruto captura ruído. Resumir os resumos eliminando os detalhes da superfície menos relevantes e é mais semanticamente significativo para os embeddings.
Por exemplo:
O texto authentic diz: “As leituras de temperatura de 2020 a 2025 variaram de 22 a 42 graus Celsius, com anomalias atribuídas ao El Nino”
O resumo seria: Tendências anuais de temperatura (2020-2025) com anomalias relacionadas ao El Niño.
A representação resumida fornece foco no conceito.
Código de exemplo:
# 4. Abstract Indexing
def summarize(textual content):
# Easy abstract for demonstration (substitute with an precise summarizer for actual use)
if "Python" in textual content:
return "Python: versatile language, utilized in information science and net improvement with many libraries."
return textual content
abstract = summarize(doc_text)
summary_embedding = embed(abstract)
print("Abstract:", abstract)

Quando usar:
- Com dados estruturados (tabelas, CSVs, arquivos de log)
- Conteúdo técnico ou detalhado em que os embeddings terão desempenho inferior ao usar embeddings de texto bruto.
Troca: Os resumos podem correr o risco de perder nuances/precisão factual se os resumos se tornarem muito abstratos. Para pesquisas críticas de domínio, especialmente jurídico, financeiro, and so forth., hyperlink para o texto authentic para fundamentação.
5. Indexação Hierárquica
A indexação hierárquica organiza as informações em vários níveis diferentes, documentos, seção, parágrafo, subparágrafo. Você recupera em etapas, começando com uma introdução ampla para restringir ao contexto específico. O nível superior do componente recupera seções de documentos relevantes e a próxima camada recupera parágrafo ou subparágrafo no contexto específico dentro das seções recuperadas dos últimos documentos.
O que isto significa?
A recuperação hierárquica reduz o ruído no sistema e é útil se você precisar controlar o tamanho do contexto. Isso é especialmente útil ao trabalhar com um grande conjunto de documentos e você não pode extrair tudo de uma vez. Também melhora a interpretabilidade para análises posteriores, pois você pode saber qual documento e qual seção contribuiu para a resposta ultimate.
Código de exemplo:
# 5. Hierarchical Indexing
# Arrange doc into ranges: doc -> chunks -> sub-chunks
hierarchical_index = {
"doc": doc_text,
"chunks": chunks,
"sub_chunks": {chunk: sub_chunk_indexing(chunk) for chunk in chunks}
}
print("Hierarchical index instance:")
print(hierarchical_index)Melhores práticas:
Use vários níveis de incorporação ou uma combinação de incorporação e pesquisa por palavras-chave. Por exemplo, inicialmente recupere documentos apenas com o BM25 e depois recupere com mais precisão esses pedaços ou componentes relevantes com incorporação.
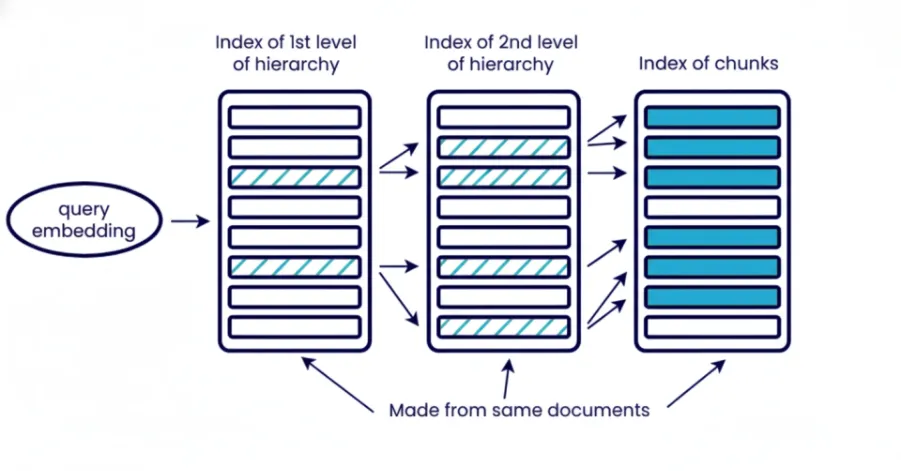
Quando usar:
- RAG em escala empresarial com milhares de documentos.
- Recuperação de fontes longas, como livros, arquivos jurídicos ou PDFs técnicos.
Troca: Maior complexidade devido aos múltiplos níveis de recuperação desejados. Também requer armazenamento e pré-processamento adicionais para metadados/resumos. Aumenta a latência da consulta devido à recuperação em várias etapas e não é adequado para grandes dados não estruturados.
6. Indexação Híbrida (Multimodal)
O conhecimento não está apenas no texto. Em sua forma de indexação híbrida, o RAG faz duas coisas para poder trabalhar com múltiplas formas de dados ou modalidades. O recuperador utiliza embeddings que ele gera a partir de diferentes codificadores especializados ou ajustados para cada uma das modalidades possíveis. E busca resultados de cada um dos embeddings relevantes e os combina para gerar uma resposta usando estratégias de pontuação ou abordagens de fusão tardia.
Aqui está um exemplo de seu uso:
- Usar GRAMPO ou BLIP para imagens e legendas de texto.
- Use embeddings CodeBERT ou StarCoder para processar código.
Código de exemplo:
# 6. Hybrid Indexing (instance with textual content + picture)
# Instance textual content and dummy picture embedding (substitute embed_image with precise mannequin)
def embed_image(image_data):
# Dummy instance: picture information represented as size of string (substitute with CLIP/BLIP encoder)
return (len(image_data) / 1000)
text_embedding = embed(doc_text)
image_embedding = embed_image("image_bytes_or_path_here")
print("Textual content embedding measurement:", len(text_embedding))
print("Picture embedding measurement:", len(image_embedding))
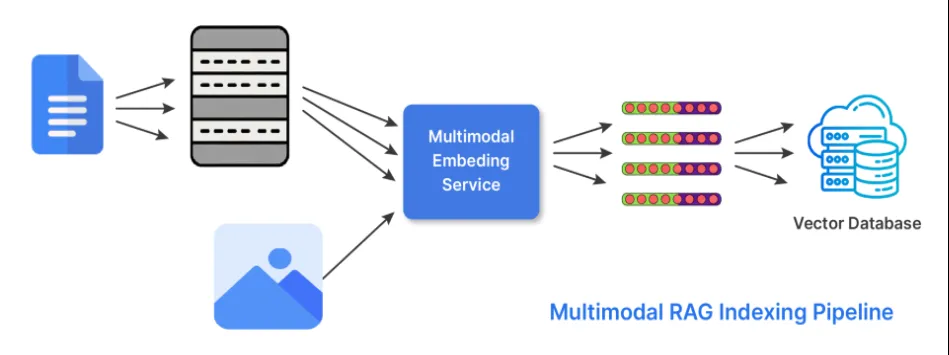
Quando usar a indexação híbrida:
- Ao trabalhar com manuais técnicos ou documentação que contenha imagens ou gráficos.
- Documentação multimodal ou artigos de suporte.
- Catálogos de produtos ou e-commerce.
Troca: É um modelo de lógica e armazenamento mais complicado para recuperação, mas com compreensão contextual muito mais rica na resposta e maior flexibilidade no domínio.
Conclusão
Os sistemas RAG bem sucedidos dependem de estratégias de indexação apropriadas para o tipo de dados e perguntas a serem respondidas. A indexação orienta o que o recuperador encontra e em que o modelo de linguagem se baseará, tornando-a uma base crítica além da recuperação. O tipo de indexação que você usaria pode ser indexação em bloco, subbloco, consulta, resumo, hierárquica ou híbrida, e essa indexação deve seguir a estrutura presente em seus dados, o que aumentará a relevância e eliminará ruídos. Processos de indexação bem projetados reduzirão alucinações e fornecer um sistema preciso e confiável.
Perguntas frequentes
A. A indexação codifica o conhecimento em incorporações, enquanto a recuperação seleciona quais partes codificadas o modelo vê para responder a uma consulta.
R. Eles determinam a precisão com que o sistema pode corresponder às consultas e quanto contexto o modelo obtém para o raciocínio.
R. Use-o quando sua base de conhecimento misturar texto, imagens, código ou outras modalidades e você precisar que o recuperador lide com todos eles.
Sou estagiário de ciência de dados na Analytics Vidhya, trabalhando apaixonadamente no desenvolvimento de soluções avançadas de IA, como aplicativos de IA generativos, grandes modelos de linguagem e ferramentas de IA de ponta que ampliam os limites da tecnologia. Minha função também envolve a criação de conteúdo educacional envolvente para os canais do Analytics Vidhya no YouTube, o desenvolvimento de cursos abrangentes que abrangem todo o espectro de aprendizado de máquina até IA generativa e a criação de blogs técnicos que conectam conceitos fundamentais com as mais recentes inovações em IA. Com isso, pretendo contribuir para a construção de sistemas inteligentes e compartilhar conhecimentos que inspirem e capacitem a comunidade de IA.
Faça login para continuar lendo e desfrutar de conteúdo com curadoria de especialistas.