
Em sistemas inteligentes, as aplicações vão desde robótica autônoma até problemas de manutenção preditiva. Para controlar estes sistemas, os aspectos essenciais são capturados com um modelo. Quando projetamos controladores para esses modelos, quase sempre enfrentamos o mesmo desafio: incerteza. Raramente conseguimos ver o quadro completo. Os sensores são barulhentos, os modelos do sistema são imperfeitos; o mundo nunca se comporta exatamente como esperado.
Think about um robô navegando em torno de um obstáculo para chegar a um native “objetivo”. Abstraímos esse cenário em um ambiente semelhante a uma grade. Uma pedra pode bloquear o caminho, mas o robô não sabe exatamente onde está a pedra. Se assim fosse, o problema seria razoavelmente fácil: planejar uma rota em torno dele. Mas com a incerteza sobre a posição do obstáculo, o robô deve aprender a operar com segurança e eficiência, não importa onde a rocha esteja.
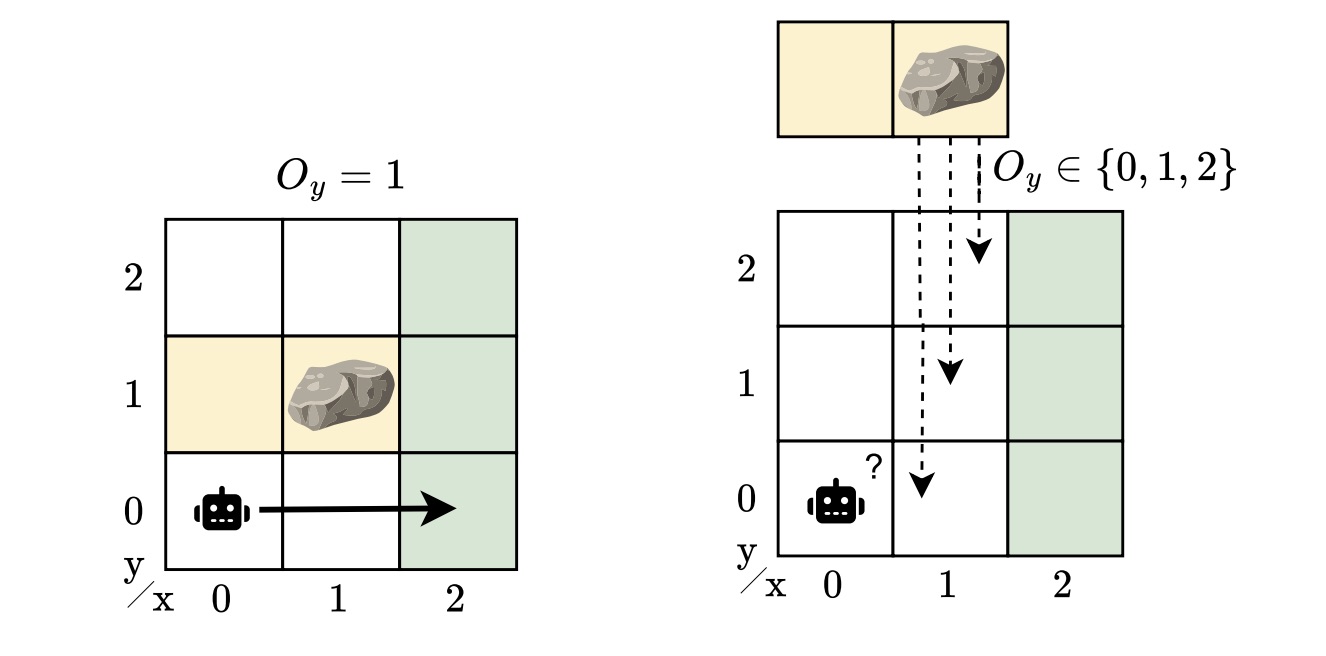
Esta história simples captura um desafio muito mais amplo: projetar controladores que possam lidar com a observabilidade parcial e a incerteza do modelo. Nesta postagem do weblog, irei guiá-lo em nosso artigo IJCAI 2025, “Gradientes robustos de política de memória finita para POMDPs de modelo oculto”onde exploramos o projeto de controladores que funcionam de maneira confiável, mesmo quando o ambiente pode não ser conhecido com precisão.
Quando você não consegue ver tudo
Quando um agente não observa completamente o estado, descrevemos seu problema de tomada de decisão sequencial usando um processo de decisão de Markov parcialmente observável (POMDP). Os POMDPs modelam situações nas quais um agente deve agir, com base na sua política, sem pleno conhecimento do estado subjacente do sistema. Em vez disso, recebe observações que fornecem informações limitadas sobre o estado subjacente. Para lidar com essa ambigüidade e tomar melhores decisões, o agente precisa de alguma forma de memória na sua política de lembrar o que viu antes. Normalmente representamos essa memória usando controladores de estado finito (FSC). Em contraste com as redes neurais, estas são representações políticas práticas e eficientes que codificam estados da memória interna que o agente atualiza à medida que age e observa.
Da observabilidade parcial aos modelos ocultos
Muitas situações raramente se enquadram em um único modelo do sistema. Os POMDPs captam a incerteza nas observações e nos resultados das ações, mas não no modelo em si. Apesar de sua generalidade, POMDPs não podem capturar conjuntos de ambientes parcialmente observáveis. Na realidade, pode haver muitas variações plausíveis, pois sempre há incógnitas – diferentes posições de obstáculos, dinâmicas ligeiramente diferentes ou variação de ruído do sensor. Um controlador para um POMDP não generaliza para perturbações do modelo. No nosso exemplo, a localização da rocha é desconhecida, mas ainda queremos um controlador que funcione em todas as localizações possíveis. Este é um cenário mais realista, mas também mais desafiador.
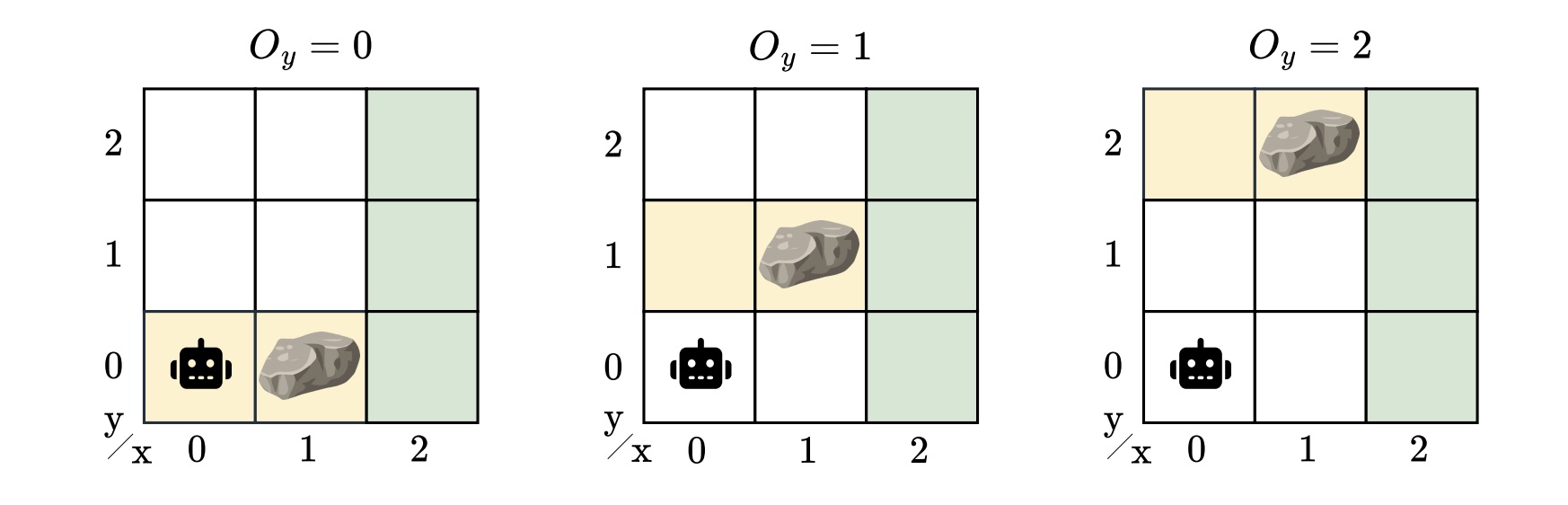
Para capturar isso incerteza do modeloapresentamos o modelo oculto POMDP (HM-POMDP). Em vez de descrever um único ambiente, um HM-POMDP representa um conjunto de possíveis POMDPs que compartilham a mesma estrutura, mas diferem em suas dinâmicas ou recompensas. Um fato importante é que um controlador para um modelo também é aplicável aos demais modelos do conjunto.
O verdadeiro ambiente em que o agente irá operar está “escondido” neste conjunto. Isto significa o o agente deve aprender um controlador que funcione bem em todos os ambientes possíveis. O desafio é que o agente não precisa apenas raciocinar sobre o que não pode ver, mas também sobre o ambiente em que está operando.
Um controlador para um HM-POMDP deve ser robusto: deve funcionar bem em todos os ambientes possíveis. Medimos a robustez de um controlador pela sua desempenho robusto: o desempenho do pior caso em todos os modelos, fornecendo um limite inferior garantido para o desempenho do agente no modelo verdadeiro. Se um controlador funcionar bem mesmo no pior caso, podemos ter certeza de que ele terá um desempenho aceitável em qualquer modelo do conjunto quando implantado.
Para aprender controladores robustos
Então, como projetamos esses controladores?
Nós desenvolvemos o gradiente robusto de política de memória finita RFPG algoritmo, uma abordagem iterativa que alterna entre as duas etapas principais a seguir:
- Avaliação robusta de políticas: Encontre o pior caso. Decide o ambiente no conjunto onde o controlador atual tem o pior desempenho.
- Otimização de políticas: melhore o controlador para o pior caso. Ajuste os parâmetros do controlador com gradientes do pior ambiente atual para melhorar o desempenho robusto.
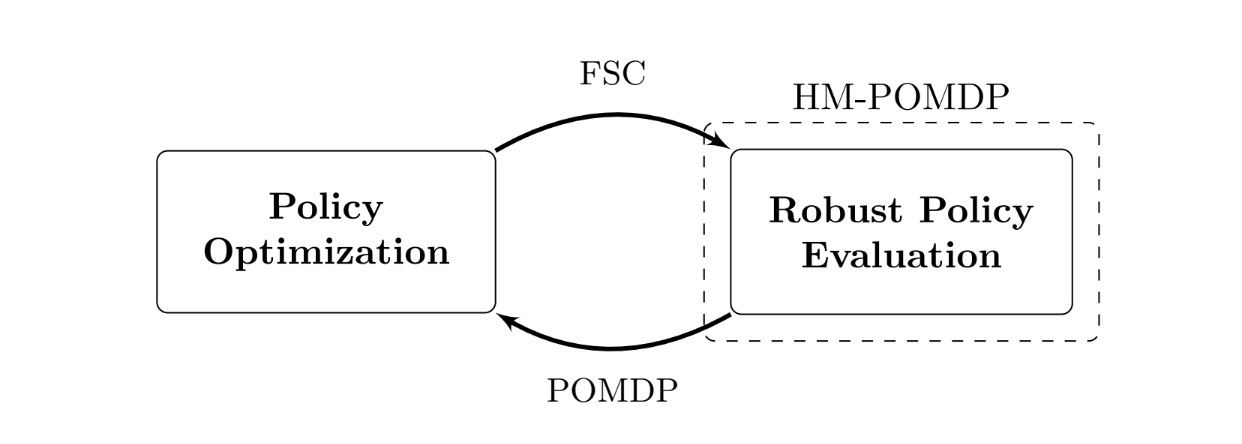
Ao longo do tempo, o controlador aprende um comportamento robusto: o que lembrar e como agir nos ambientes encontrados. A natureza iterativa desta abordagem está enraizada na estrutura matemática de “subgradientes”. Aplicamos essas atualizações baseadas em gradiente, também usadas no aprendizado por reforço, para melhorar o desempenho robusto do controlador. Embora os detalhes sejam técnicos, a intuição é simples: otimizar iterativamente o controlador para os modelos de pior caso melhora seu desempenho robusto em todos os ambientes.
Sob o capô, RFPG utiliza técnicas formais de verificação implementadas na ferramenta PAYNT, explorando semelhanças estruturais para representar grandes conjuntos de modelos e avaliar controladores entre eles. Graças a estes desenvolvimentos, a nossa abordagem escala para HM-POMDPs com muitos ambientes. Na prática, isto significa que podemos raciocinar sobre mais de cem mil modelos.
Qual é o impacto?
Nós testamos RFPG em HM-POMDPs que simularam ambientes com incerteza. Por exemplo, problemas de navegação em que obstáculos ou erros de sensor variavam entre modelos. Nestes testes, RFPG produziram políticas que não só eram mais robustas a estas variações, mas também generalizado melhor para ambientes completamente invisíveis do que várias linhas de base do POMDP. Na prática, isso implica podemos tornar controladores robustos a pequenas variações do modelo. Lembre-se do nosso exemplo em execução, com um robô que navega em um mundo quadriculado onde a localização da rocha é desconhecida. Emocionantemente, RFPG resolve isso de maneira quase best com apenas dois nós de memória! Você pode ver o controlador abaixo.

Ao integrar o raciocínio baseado em modelos com métodos baseados em aprendizagem, desenvolvemos algoritmos para sistemas que levam em conta a incerteza em vez de ignorá-la. Embora os resultados sejam promissores, eles vêm de domínios simulados com espaços discretos; a implantação no mundo actual exigirá o tratamento da natureza contínua de vários problemas. Ainda assim, é praticamente relevante para a tomada de decisões de alto nível e confiável desde o início. No futuro, aumentaremos a escala — por exemplo, usando redes neurais — e tentaremos lidar com lessons mais amplas de variações no modelo, como distribuições sobre incógnitas.
Quer saber mais?
Obrigado por ler! Espero que você tenha achado interessante e tenha uma noção do nosso trabalho. Você pode conhecer mais sobre meu trabalho em marisgg.github.io e sobre nosso grupo de pesquisa em ai-fm.org.
Esta postagem do weblog é baseada no seguinte artigo do IJCAI 2025:
- Maris FL Galesloot, Roman Andriushchenko, Milan Češka, Sebastian Junges e Nils Jansen: “Gradientes robustos de política de memória finita para POMDPs de modelo oculto”. Em IJCAI 2025, páginas 8518–8526.
Para saber mais sobre as técnicas que usamos da ferramenta PAYNT e, de forma mais geral, sobre o uso dessas técnicas para calcular FSCs, consulte o artigo abaixo:
- Roman Andriushchenko, Milan Češka, Filip Macák, Sebastian Junges, Joost-Pieter Katoen: “Uma abordagem guiada pela Oracle para síntese de políticas restritas sob incerteza”. Em JAIR, 2025.
Se você quiser saber mais sobre outra maneira de lidar com a incerteza do modelo, dê uma olhada em nossos outros artigos também. Por exemplo, em nosso artigo ECAI 2025, projetamos controladores robustos usando redes neurais recorrentes (RNNs):
- Maris FL Galesloot, Marnix Suilen, Thiago D. Simão, Steven Carr, Matthijs TJ Spaan, Ufuk Topcu e Nils Jansen: “Planejamento iterativo pessimista com RNNs para POMDPs robustos”. Em ECAI, 2025.
E em nosso artigo NeurIPS 2025, estudamos a avaliação de políticas:
- Merlijn Krale, Eline M. Bovy, Maris FL Galesloot, Thiago D. Simão e Nils Jansen: “Sobre a avaliação de políticas para POMDPs robustos”. Em NeurIPS, 2025.

Maris Galesloot
é candidato a doutorado ELLIS no Instituto de Computação e Ciência da Informação da Radboud College.
Maris Galesloot é doutoranda em ELLIS no Instituto de Computação e Ciência da Informação da Universidade Radboud.