 |
Hoje, estamos anunciando dois novos recursos de treinamento de modelos de IA dentro HyperPod do Amazon SageMaker: treinamento sem pontos de verificação, uma abordagem que mitiga a necessidade de recuperação tradicional baseada em pontos de verificação, permitindo a recuperação de estado ponto a ponto, e treinamento elástico, permitindo que as cargas de trabalho de IA sejam escalonadas automaticamente com base na disponibilidade de recursos.
- Treinamento sem checkpoint – O treinamento sem pontos de verificação elimina ciclos perturbadores de reinício de pontos de verificação, mantendo o ritmo de treinamento apesar das falhas, reduzindo o tempo de recuperação de horas para minutos. Acelere o desenvolvimento do seu modelo de IA, recupere dias dos cronogramas de desenvolvimento e dimensione com confiança os fluxos de trabalho de treinamento para milhares de aceleradores de IA.
- Treinamento elástico – O treinamento elástico maximiza a utilização do cluster à medida que as cargas de trabalho de treinamento se expandem automaticamente para usar a capacidade ociosa à medida que ela se torna disponível e contrai para produzir recursos à medida que cargas de trabalho de maior prioridade, como picos de volumes de inferência. Economize horas de engenharia por semana gastas na reconfiguração de trabalhos de treinamento com base na disponibilidade da computação.
Em vez de gastar tempo gerenciando a infraestrutura de treinamento, essas novas técnicas de treinamento significam que sua equipe pode se concentrar inteiramente em melhorar o desempenho do modelo e, em última análise, colocar seus modelos de IA no mercado com mais rapidez. Ao eliminar as dependências tradicionais dos pontos de verificação e utilizar totalmente a capacidade disponível, você pode reduzir significativamente os tempos de conclusão do treinamento do modelo.
Treinamento sem checkpoint: como funciona
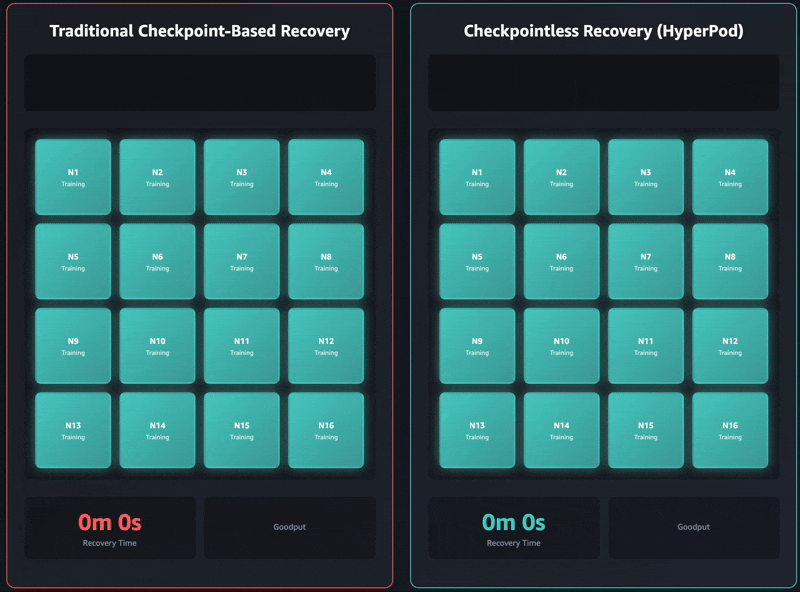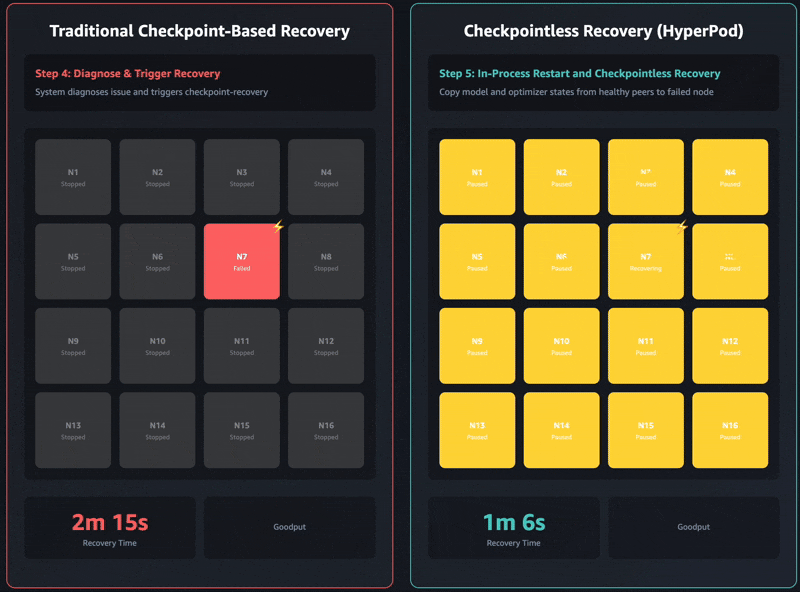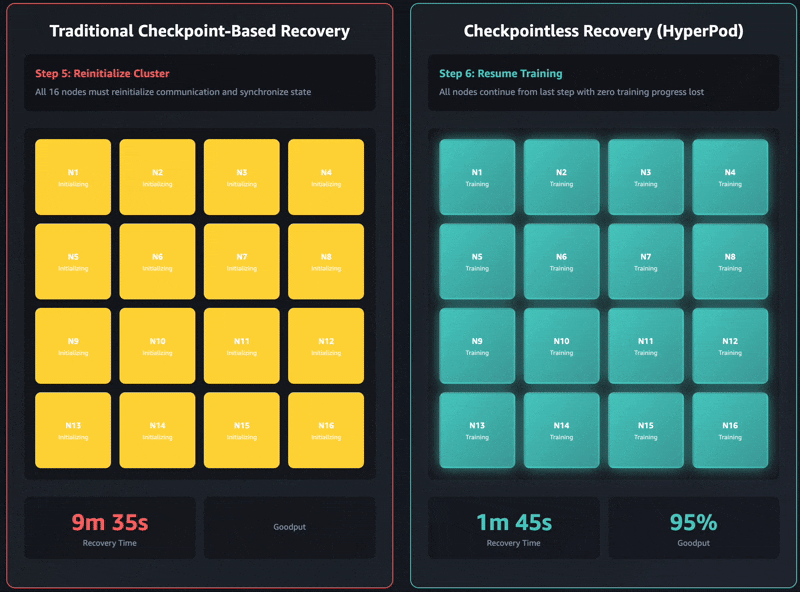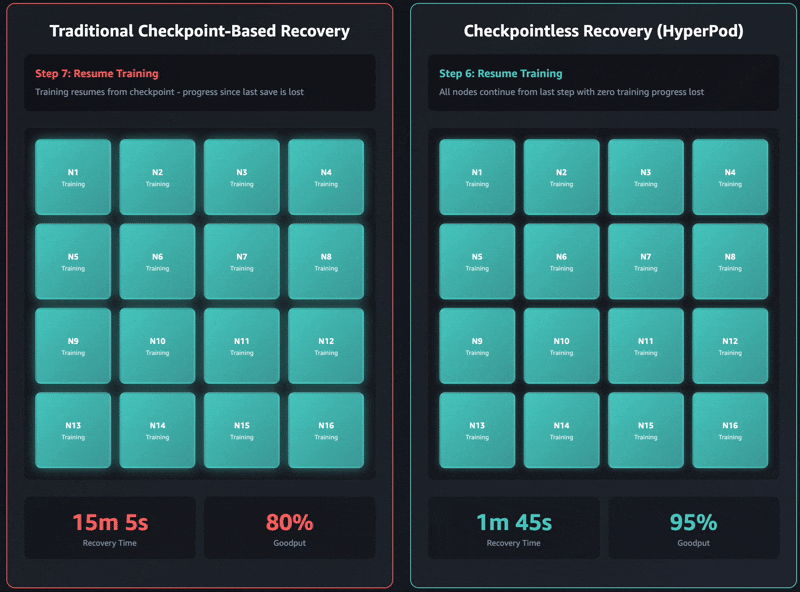
A recuperação tradicional baseada em pontos de verificação tem estes estágios de trabalho sequenciais: 1) encerramento e reinicialização do trabalho, 2) descoberta de processos e configuração de rede, 3) recuperação de pontos de verificação, 4) inicialização do carregador de dados e 5) retomada do loop de treinamento. Quando ocorrem falhas, cada estágio pode se tornar um gargalo e a recuperação do treinamento pode levar até uma hora em clusters de treinamento autogerenciados. Todo o cluster deve aguardar a conclusão de cada estágio antes que o treinamento possa ser retomado. Isso pode fazer com que todo o cluster de treinamento fique ocioso durante as operações de recuperação, o que aumenta os custos e prolonga o tempo de lançamento no mercado.
O treinamento sem checkpoint take away totalmente esse gargalo, mantendo a preservação contínua do estado do modelo em todo o cluster de treinamento. Quando ocorrem falhas, o sistema se recupera instantaneamente usando pares íntegros, evitando a necessidade de uma recuperação baseada em pontos de verificação que exige a reinicialização de todo o trabalho. Como resultado, o treinamento sem pontos de verificação permite a recuperação de falhas em minutos.
O treinamento sem checkpoint foi projetado para adoção incremental e baseado em quatro componentes principais que funcionam juntos: 1) otimizações de inicialização de comunicações coletivas, 2) carregamento de dados mapeados na memória que permite armazenamento em cache, 3) recuperação em processo e 4) replicação de estado ponto a ponto sem checkpoint. Esses componentes são orquestrados através do Operador de treinamento HyperPod que é usado para iniciar o trabalho. Cada componente otimiza uma etapa específica do processo de recuperação e, juntos, permitem a detecção e recuperação automáticas de falhas de infraestrutura em minutos, sem intervenção guide, mesmo com milhares de aceleradores de IA. Você pode ativar progressivamente cada um desses recursos à medida que seu treinamento aumenta.
O mais recente Amazônia Nova modelos foram treinados usando essa tecnologia em dezenas de milhares de aceleradores. Além disso, com base em estudos internos sobre tamanhos de cluster que variam entre 16 GPUs e mais de 2.000 GPUs, o treinamento sem pontos de verificação apresentou melhorias significativas nos tempos de recuperação, reduzindo o tempo de inatividade em mais de 80% em comparação com a recuperação tradicional baseada em pontos de verificação.
Para saber mais, visite página do GitHub de treinamento sem checkpoint para implementação e Treinamento sem ponto de verificação do HyperPod no Guia do desenvolvedor do Amazon SageMaker AI.
Treinamento elástico: como funciona
Em clusters que executam diferentes tipos de cargas de trabalho de IA modernas, a disponibilidade do acelerador pode mudar continuamente ao longo do dia à medida que o treinamento de curta duração é concluído, os picos de inferência ocorrem e diminuem ou os recursos são liberados de experimentos concluídos. Apesar desta disponibilidade dinâmica de aceleradores de IA, as cargas de trabalho de treinamento tradicionais permanecem presas à sua alocação computacional inicial, incapazes de aproveitar os aceleradores ociosos sem intervenção guide. Essa rigidez deixa a valiosa capacidade da GPU sem uso e impede que as organizações maximizem seu investimento em infraestrutura.
 O treinamento elástico transforma a forma como as cargas de trabalho de treinamento interagem com os recursos do cluster. Os trabalhos de treinamento podem ser ampliados automaticamente para utilizar aceleradores disponíveis e contrair normalmente quando os recursos são necessários em outro lugar, tudo isso mantendo a qualidade do treinamento.
O treinamento elástico transforma a forma como as cargas de trabalho de treinamento interagem com os recursos do cluster. Os trabalhos de treinamento podem ser ampliados automaticamente para utilizar aceleradores disponíveis e contrair normalmente quando os recursos são necessários em outro lugar, tudo isso mantendo a qualidade do treinamento.
A elasticidade da carga de trabalho é habilitada por meio do operador de treinamento HyperPod que orquestra decisões de escalonamento por meio da integração com o plano de controle e o agendador de recursos do Kubernetes. Ele monitora continuamente o estado do cluster por meio de três canais principais: eventos do ciclo de vida do pod, alterações na disponibilidade do nó e sinais de prioridade do agendador de recursos. Esse monitoramento abrangente permite a detecção quase instantânea de oportunidades de escalabilidade, seja de recursos recentemente disponíveis ou de solicitações de cargas de trabalho de maior prioridade.
O mecanismo de escalonamento depende da adição e remoção de réplicas paralelas de dados. Quando recursos computacionais adicionais ficam disponíveis, novas réplicas paralelas de dados ingressam no trabalho de treinamento, acelerando o rendimento. Por outro lado, durante eventos de redução (por exemplo, quando uma carga de trabalho de prioridade mais alta solicita recursos), o sistema reduz removendo réplicas em vez de encerrar o trabalho inteiro, permitindo que o treinamento proceed com capacidade reduzida.
Em diferentes escalas, o sistema preserva o tamanho international do lote e adapta as taxas de aprendizagem, evitando que a convergência do modelo seja afetada negativamente. Isso permite que as cargas de trabalho aumentem ou diminuam dinamicamente para utilizar aceleradores de IA disponíveis sem qualquer intervenção guide.
Você pode iniciar o treinamento elástico por meio das receitas do HyperPod para modelos básicos (FMs) disponíveis publicamente, incluindo Llama e GPT-OSS. Além disso, você pode modificar seus scripts de treinamento PyTorch para adicionar manipuladores de eventos elásticos, que permitem que o trabalho seja dimensionado dinamicamente.
Para saber mais, visite o Treinamento elástico HyperPod no Guia do desenvolvedor do Amazon SageMaker AI. Para começar, encontre o Receitas do HyperPod disponível no repositório AWS GitHub.
Agora disponível
Ambos os recursos estão disponíveis em todas as regiões em que o Amazon SageMaker HyperPod está disponível. Você pode usar essas técnicas de treinamento sem custo adicional. Para saber mais, visite o Página do produto SageMaker HyperPod e Página de preços do SageMaker AI.
Experimente e envie suggestions para AWS re:Submit para SageMaker ou por meio de seus contatos habituais do AWS Assist.
– Channy