Os relatórios ESG ou relatórios ambientais, sociais e de governança muitas vezes parecem esmagadores porque os dados vêm de muitos lugares e levam muito tempo para serem reunidos. As equipes passam a maior parte do tempo coletando números em vez de interpretar o que eles significam. A Agentic AI muda essa dinâmica. Em vez de um chatbot respondendo a perguntas, você recebe um grupo coordenado de ajudantes de IA que trabalham como uma equipe de reportagem dedicada. Eles coletam informações, verificam-nas em relação às regras relevantes e preparam rascunhos de resumos claros para que os humanos possam se concentrar nos insights em vez de na papelada.
Neste guia, apresentaremos, passo a passo, um pipeline prático e centrado no desenvolvedor para relatórios ESG, abrangendo:
- Agregação de dados: Empregue agentes simultâneos para obter dados de APIs e documentos e depois indexe-os usando pesquisa vetorial (por exemplo, embeddings OpenAI + FAISS).
- Verificações de conformidade: Execute regras regulatórias (como CSRD ou Taxonomia da UE) por meio de lógica de código ou consultas SQL para destacar quaisquer problemas.
- Relatório inteligente: Direcione a criação de um relatório narrativo usando Retrieval-Augmented Technology (RAG) e cadeias LLM e entregue-o como um PDF.
Etapa 1: Agregação de dados ESG com agentes de IA
Inicialmente é necessário coletar todos os dados pertinentes por meios paralelos. Para ilustrar, um agente pode obter as pesquisas ESG mais recentes por meio de API arXivoutro pode procurar atualizações regulatórias recentes por meio de uma API de notícias e um terceiro pode classificar os documentos ESG internos da empresa.
Em um experimento, três “agentes de pesquisa” específicos operaram simultaneamente para fazer consultas ao arXiv, um índice interno do Azure AI Search, e a fontes de notícias. Depois disso, cada agente forneceu seus dados à base de conhecimento central. Podemos emular esse processo em Pitão empregando threads junto com um armazenamento de vetores para pesquisa de documentos:
import requests
import concurrent.futures
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# ESG Information Aggregation and RAG Pipeline Instance
# 1. Exterior Search Features
# Instance: search arXiv for ESG-related papers
def search_arxiv(question, max_results=3):
"""Searches the arXiv API for papers."""
url = (
f"http://export.arxiv.org/api/question?"
f"search_query=all:{question}&max_results={max_results}"
)
res = requests.get(url)
# (Parse the XML response; right here we simply return uncooked textual content for brevity)
return res.textual content(:200) # present first 200 chars of end result
# Instance: search information utilizing a hypothetical API (change with an actual information API)
def search_news(question, api_key):
"""Searches a hypothetical information API (wants substitute with an actual one)."""
# NOTE: This can be a placeholder URL and won't work and not using a actual information API
url = f"https://newsapi.instance.com/search?q={question}&apiKey={api_key}"
strive:
# Simulate a request; it will possible fail with a 404/SSL error
res = requests.get(url, timeout=5)
articles = res.json().get("articles", ())
return (article("title") for article in articles(:3))
besides requests.exceptions.RequestException as e:
return (f"Error fetching information (API Placeholder): {e}")
# 2. Inner Doc Indexing Perform (for RAG)
def build_vector_index(pdf_paths):
"""Hundreds, splits, and embeds PDF paperwork right into a FAISS vector retailer."""
splitter = CharacterTextSplitter(chunk_size=800, chunk_overlap=100)
all_docs = ()
# NOTE: PyPDFLoader requires the information 'annual_report.pdf' and 'energy_audit.pdf' to exist
for path in pdf_paths:
strive:
loader = PyPDFLoader(path)
pages = loader.load()
docs = splitter.split_documents(pages)
all_docs.prolong(docs)
besides Exception as e:
print(f"Warning: Couldn't load PDF {path}. Skipping. Error: {e}")
if not all_docs:
# Return a easy object or elevate an error if no paperwork have been loaded
print("Error: No paperwork have been efficiently loaded to construct the index.")
return None
embeddings = OpenAIEmbeddings()
vector_index = FAISS.from_documents(all_docs, embeddings)
return vector_index
# --- Foremost Execution ---
# Paths to inside ESG PDFs (should exist in the identical listing or have full path)
pdf_files = ("annual_report.pdf", "energy_audit.pdf")
# Run exterior searches and doc indexing in parallel
print("Beginning parallel information fetching and index constructing...")
with concurrent.futures.ThreadPoolExecutor() as executor:
# Exterior Searches
future_arxiv = executor.submit(search_arxiv, "web zero 2030")
# NOTE: Substitute 'YOUR_NEWS_API_KEY' with a sound key for an actual information API
future_news = executor.submit(
search_news,
"EU CSRD regulation",
"YOUR_NEWS_API_KEY"
)
# Construct vector index (will print warnings if PDFs do not exist)
future_index = executor.submit(build_vector_index, pdf_files)
# Gather outcomes
arxiv_data = future_arxiv.end result()
news_data = future_news.end result()
vector_index = future_index.end result()
print("n--- Aggregated Outcomes ---")
print("ArXiv fetched information snippet:", arxiv_data)
print("High information titles:", news_data)
if vector_index:
print("nFAISS Vector Index efficiently constructed.")
# Instance continuation: Initialize the RAG chain
# llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# qa_chain = RetrievalQA.from_chain_type(
# llm=llm,
# retriever=vector_index.as_retriever()
# )
# print("RAG setup full. Prepared to question inside paperwork.")
else:
print("RAG setup skipped because of failed vector index creation.")Saída:


Aqui, usamos um pool de threads para chamar fontes diferentes simultaneamente. Um thread busca documentos arXiv, outro chama uma API de notícias e outro cria um armazenamento vetorial de documentos internos. O índice vetorial usa embeddings OpenAI armazenados no FAISS, permitindo a pesquisa em linguagem pure nos documentos.
Consultando os dados agregados
Com os dados coletados, os agentes podem consultá-los through linguagem pure. Por exemplo, podemos usar LangChainpipeline RAG do para fazer perguntas sobre os documentos indexados:
# Create a retriever from the FAISS index
retriever = vector_index.as_retriever(
search_type="similarity",
search_kwargs={"ok": 4}
)
# Initialize an LLM (e.g., GPT-4) and a RetrievalQA chain
llm = ChatOpenAI(temperature=0, mannequin="gpt-4")
qa_chain = RetrievalQA(llm=llm, retriever=retriever)
# Ask a pure language query about ESG information
reply = qa_chain.run("What have been the Scope 2 emissions for 2023?")
print("RAG reply:", reply)Esse pano A abordagem permite que o agente recupere segmentos relevantes do documento (por meio de pesquisa por similaridade) e então gere uma resposta. Numa demonstração, um agente converteu consultas em inglês simples para SQL para obter dados numéricos (por exemplo, “Emissões de Âmbito 2 em 2024”) da base de dados de emissões. Da mesma forma, podemos incorporar uma etapa de consulta SQL, se necessário, por exemplo, usando SQLite em Python:
import sqlite3
# Instance: retailer some emissions information in SQLite
conn = sqlite3.join(':reminiscence:')
cursor = conn.cursor()
cursor.execute("CREATE TABLE emissions (12 months INTEGER, scope2 REAL)")
cursor.execute("INSERT INTO emissions VALUES (2023, 1725.4)")
conn.commit()
# Easy SQL question for numeric information
cursor.execute("SELECT scope2 FROM emissions WHERE 12 months=2023")
scope2_emissions = cursor.fetchone()(0)
print("Scope 2 emissions 2023 (from DB):", scope2_emissions) Na prática, você poderia integrar um LangChain SQL Agent para converter linguagem pure em SQL automaticamente. Independentemente da fonte, todos esses pontos de dados – desde PDFs, APIs e bancos de dados – alimentam uma base de conhecimento unificada para o pipeline de relatórios.
Etapa 2: verificações automatizadas de conformidade
O processo de garantia de conformidade é o próximo passo após a coleta das métricas brutas. A mistura de lógica de código e suporte LLM pode ajudar nesse sentido. Por exemplo, podemos mapear as regras do domínio (como os critérios da Taxonomia da UE) e depois realizar verificações:
# Instance ESG metrics extracted from information aggregation
metrics = {
"scope1_tCO2": 980,
"scope2_tCO2": 1725.4,
"renewable_percent": 25, # p.c of power from renewables
"water_usage_liters": 50000,
"reported_water_liters": 48000
}
# Easy rule-based compliance checks
def run_compliance_checks(metrics):
"""
Runs fundamental checks in opposition to predefined ESG compliance guidelines.
"""
points = ()
# Instance rule 1: EU Taxonomy requires >= 30% renewable power
if metrics("renewable_percent") < 30:
points.append("Renewables under EU taxonomy threshold (30%).")
# Instance rule 2: Consistency examine (tolerance of 1000 liters)
if abs(metrics("water_usage_liters") - metrics("reported_water_liters")) > 1000:
points.append("Water utilization mismatch between operations information and monetary report.")
return points
# Execute the checks
compliance_issues = run_compliance_checks(metrics)
print("Compliance points discovered:", compliance_issues)Esta função simples identifica quaisquer regras que tenham sido violadas. Na vida actual, talvez você obtenha regras de uma base de conhecimento ou configuração. As verificações de conformidade são frequentemente divididas em funções em sistemas baseados em agentes. Os agentes de Critérios/Mapeamento vinculam os dados extraídos aos campos de divulgação específicos ou aos critérios da taxonomia enquanto os agentes de Cálculo realizam as verificações ou conversões numéricas. Para citar um exemplo, um dos agentes poderia verificar se uma determinada atividade está em conformidade com os critérios “Não causar danos significativos” estabelecidos pela Taxonomia ou poderia derivar as emissões totais por meio de consultas de texto em SQL.
Exemplo de texto para SQL (opcional)
LangChain fornece ferramentas SQL para automatizar esta etapa. Por exemplo, pode-se criar um SQL Agent que examina o esquema do seu banco de dados e gera consultas. Aqui está um esboço usando SQLDatabase do LangChain:
from langchain.brokers import create_sql_agent
from langchain.sql_database import SQLDatabase
# Arrange a SQLite DB (similar as above)
db = SQLDatabase.from_uri("sqlite:///:reminiscence:", include_tables=("emissions"))
# Create an agent that may reply questions utilizing the DB
sql_agent = create_sql_agent(llm=llm, db=db, verbose=False)
query_result = sql_agent.run("What's the whole Scope 2 emissions for 2023?")
print("SQL Agent end result:", query_result)Este agente fará uma introspecção na tabela de emissões e produzirá uma consulta para calcular a resposta, verificando-a antes de retornar um resultado. (Na prática, certifique-se de que as permissões do seu banco de dados estejam bloqueadas, pois a execução do SQL gerado pelo modelo apresenta riscos.)
Etapa 3: Relatórios inteligentes generativos com agentes RAG
Após a validação, a etapa remaining é a elaboração do relatório narrativo. Aqui, um agente de síntese pega os dados limpos e escreve divulgações legíveis por humanos. Podemos usar cadeias LLM para isso, muitas vezes com pano incluir figuras e citações específicas. Por exemplo, podemos solicitar ao modelo as principais métricas e deixá-lo redigir um resumo:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Put together a immediate template to generate an government abstract
prompt_template = """
Write a concise government abstract of the ESG report utilizing the information under.
Embrace key figures and context:
{summary_data}
"""
template = PromptTemplate(
input_variables=("summary_data"),
template=prompt_template
)
# Instance information to incorporate within the abstract
findings = f"""
- Scope 1 CO2 emissions: {metrics('scope1_tCO2')} tCO2e
- Scope 2 CO2 emissions: {metrics('scope2_tCO2')} tCO2e
- Renewable power share: {metrics('renewable_percent')}%
"""
chain = LLMChain(llm=ChatOpenAI(temperature=0.2), immediate=template)
summary_text = chain.run({"summary_data": findings})
print("Generated abstract:n", summary_text)Saída:
=== ANSWER ===
Within the **Sustainability Annual Report 2024**, the reported emissions are as follows:- **Scope 1 Emissions**: 980 tCO2e
- **Scope 2 Emissions**: 1,725.4 tCO2eThe full emissions quantity to **2,705.4 tCO2e**.
A notable compliance hole is recognized within the **Vitality Audit Abstract - 2024**, the place the renewable power share is reported at **28%**, which is under the regulatory goal of **30%**. This means a necessity for enchancment in renewable power utilization to satisfy compliance requirements.
Moreover, the report highlights a suggestion so as to add **500 kW** of rooftop photo voltaic to reinforce renewable power capability.
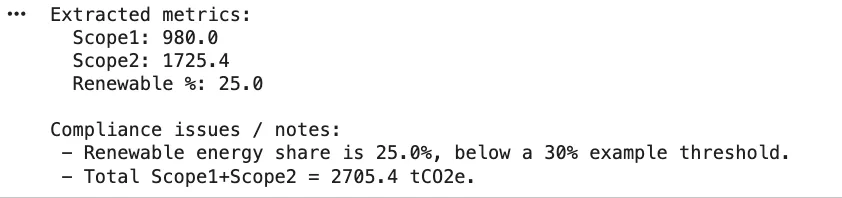
Alternativamente, você pode construir um RetrievalQA ou agente encadeado que extrai documentos e dados indexados e, em seguida, chama o LLM para escrever cada seção. Por exemplo, usando o RetrievalQA da LangChain como acima, você poderia pedir ao agente para “Resumir as emissões dos Escopos 1 e 2 e destacar quaisquer lacunas de conformidade”. A chave é que cada resposta possa citar fontes ou métodos, permitindo uma trilha de evidências.
Etapa 4: Compilando o Relatório Ultimate
Após a elaboração, seria possível combinar e formatar as seções, pois isso é feito de uma forma muito simples usando fpdf. PDF será usado para escrever o resumo.
from fpdf import FPDF
pdf = FPDF()
pdf.add_page()
pdf.set_font("Arial", dimension=14)
pdf.multi_cell(0, 10, summary_text)
pdf.output("esg_report_summary.pdf")
print("PDF report generated.")Saída:

Num pipeline completo, pode-se fazer muitas seções (como culturas, emissões, energia, água, and so forth.) e juntá-las. Os agentes podem até ajudar na edição humana: os rascunhos das respostas são mostrados em uma interface de bate-papo para que os especialistas do domínio avaliem e melhorem. Uma vez aprovado, um agente de síntese pode criar o PDF remaining ou o texto remaining, juntamente com tabelas e figuras, conforme necessário.
No remaining, esse fluxo de trabalho dos agentes reduz o tempo gasto em relatórios manuais de semanas para horas: os agentes preenchem os itens do questionário a partir dos dados em lotes, marcam quaisquer problemas, permitem a revisão humana e, em seguida, produzem um relatório completo. Cada resposta vem com referências embutidas e etapas de cálculo para maior clareza. O resultado é um relatório ESG pronto para auditoria, gerado por código e IA, e não por mão humana.
Conclusão
Um fluxo de trabalho ESG de ponta a ponta pode funcionar de maneira muito mais tranquila quando vários Agentes de IA compartilhar a carga. Eles extraem informações de fontes de pesquisa, feeds de notícias e arquivos internos ao mesmo tempo, verificam os dados em relação às regras relevantes e ajudam a moldar o relatório remaining usando a geração consciente do contexto. Os exemplos de código mostram como cada parte permanece limpa e modular, facilitando a conexão de APIs reais, a expansão do conjunto de regras ou o ajuste da lógica quando as regulamentações mudam. A verdadeira vantagem é o tempo: as equipes gastam menos energia buscando dados e mais para entender o que eles significam. Com esse pipeline, você tem um plano claro para construir seu próprio sistema de relatórios ESG orientado por agentes.
Perguntas frequentes
R. Ele divide a carga de trabalho entre agentes autônomos que extraem dados, verificam a conformidade e elaboram seções em paralelo. A maior parte do trabalho pesado desaparece, deixando os humanos revisarem e refinarem em vez de montar tudo manualmente.
R. Na verdade não. Uma configuração típica usa Python, LangChain, ferramentas de pesquisa vetorial como FAISS e uma API LLM. Você pode ampliar posteriormente com orquestradores de fluxo de trabalho ou funções de nuvem, se necessário.
R. Sim. As regras de conformidade residem no código ou na configuração, para que você possa atualizar ou adicionar novos módulos de regras sem tocar no restante do pipeline. Os agentes aplicam automaticamente a lógica mais recente durante as verificações.
Estagiário de Ciência de Dados na Analytics Vidhya
Atualmente estou trabalhando como Trainee de Ciência de Dados na Analytics Vidhya, onde me concentro na construção de soluções baseadas em dados e na aplicação de técnicas de IA/ML para resolver problemas de negócios do mundo actual. Meu trabalho me permite explorar análises avançadas, aprendizado de máquina e aplicações de IA que capacitam as organizações a tomar decisões mais inteligentes e baseadas em evidências.
Com uma base sólida em ciência da computação, desenvolvimento de software program e análise de dados, sou apaixonado por aproveitar a IA para criar soluções impactantes e escaláveis que preencham a lacuna entre tecnologia e negócios.
📩 Você também pode entrar em contato comigo em (e-mail protegido)
Faça login para continuar lendo e desfrutar de conteúdo com curadoria de especialistas.