Nos últimos anos, testemunhamos uma mudança significativa na forma como as empresas gerenciam e analisam seus crescentes knowledge lakes. Na vanguarda desta transformação está Iceberg Apacheum formato de tabela aberta que está ganhando força rapidamente entre consumidores de dados em grande escala.
No entanto, à medida que as empresas dimensionam as suas implementações de knowledge lake, a gestão destas tabelas Iceberg em escala torna-se um desafio. As equipes de dados geralmente precisam gerenciar a evolução do esquema da tabela, seu particionamento e versões de snapshots. A automação agiliza essas operações, fornece consistência, reduz erros humanos e ajuda as equipes de dados a se concentrarem em tarefas de maior valor.
O Cola AWS Catálogo de Dados agora oferece suporte ao gerenciamento de tabelas Iceberg usando o API AWS Glue, SDKs da AWSe AWS CloudFormation. Anteriormente, os usuários tinham que criar tabelas Iceberg no Knowledge Catalog sem partições usando CloudFormation ou SDKs e depois adicionar partições de Amazon Atenas ou outros mecanismos de análise. Isso evita que a linhagem da tabela seja rastreada em um só lugar e adiciona etapas fora da automação no pipeline de integração e entrega contínua (CI/CD) para operações de manutenção de tabelas. Com o lançamento, os clientes do AWS Glue agora podem usar suas ferramentas preferidas de automação ou infraestrutura como código (IaC) para automatizar a criação de tabelas Iceberg com partições e usar as mesmas ferramentas para gerenciar atualizações de esquema e ordem de classificação.
Nesta postagem, mostramos como criar e atualizar tabelas Iceberg com partições no Knowledge Catalog usando AWS SDK e CloudFormation.
Visão geral da solução
Nas seções seguintes, ilustramos o SDK da AWS para Python (Boto3) e Interface de linha de comando da AWS (AWS CLI) uso de APIs do Knowledge Catalog —CriarTabela() e AtualizarTabela()-para Serviço de armazenamento simples da Amazon (Amazon S3) com base em tabelas Iceberg com partições. Também fornecemos os modelos CloudFormation para criar e atualizar uma tabela Iceberg com partições.
Pré-requisitos
As alterações da API do Knowledge Catalog estão disponíveis nas seguintes versões da AWS CLI e do SDK para Python:
- Versão AWS CLI 2.27.58 ou superior
- SDK para Python versão 1.39.12 ou superior
Uso da AWS CLI
Vamos criar uma tabela Iceberg com uma partição, usando CriarTabela() na AWS CLI:
O createicebergtable.json é o seguinte:
O comando anterior da AWS CLI cria a pasta de metadados para a tabela Iceberg no Amazon S3, conforme mostrado na captura de tela a seguir.

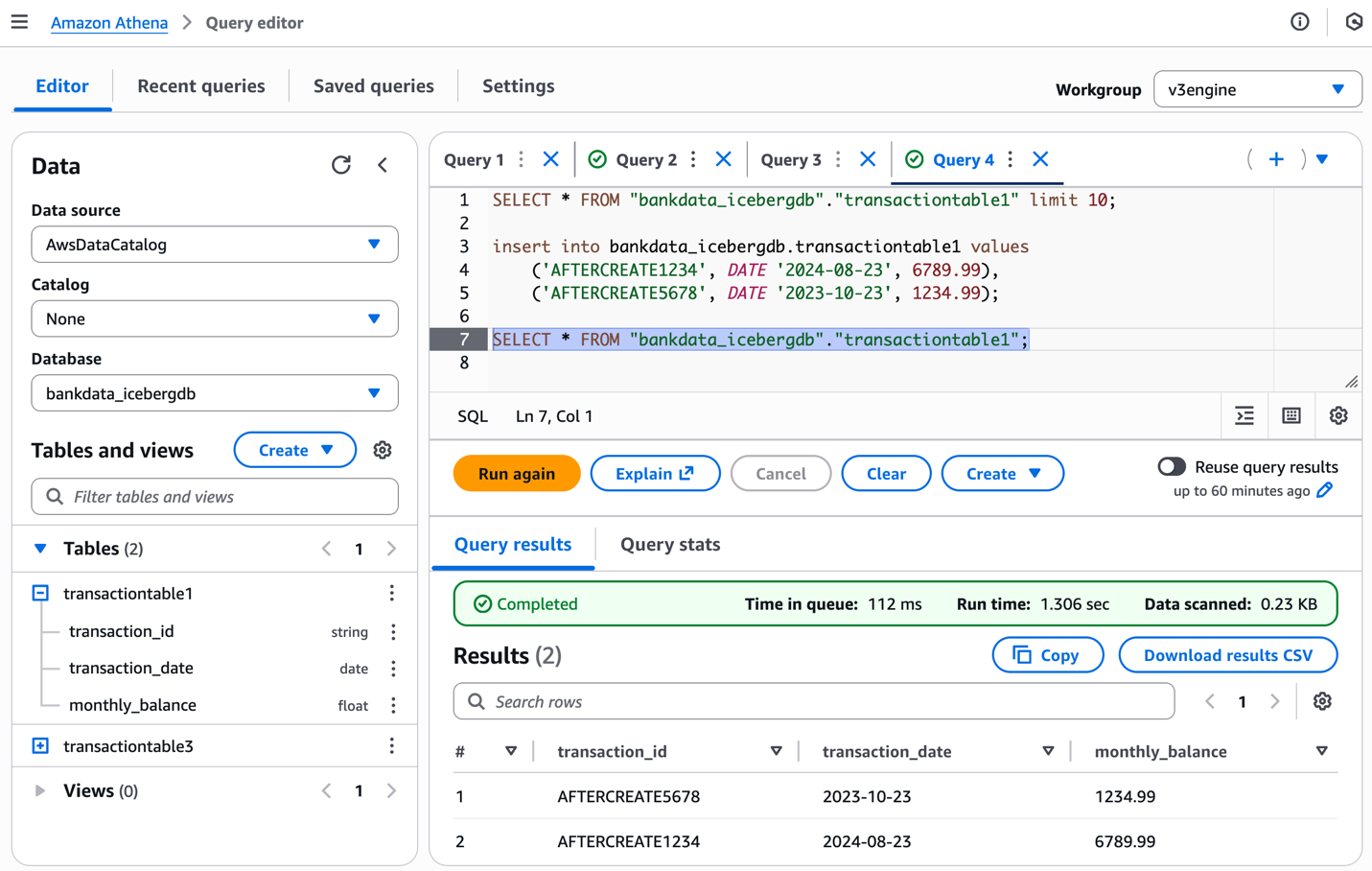
Você pode preencher a tabela com valores da seguinte maneira e verificar o esquema da tabela usando o console do Athena:
A captura de tela a seguir mostra os resultados.
Após preencher a tabela com dados, você pode inspecionar o prefixo S3 da tabela, que agora terá o knowledge pasta.
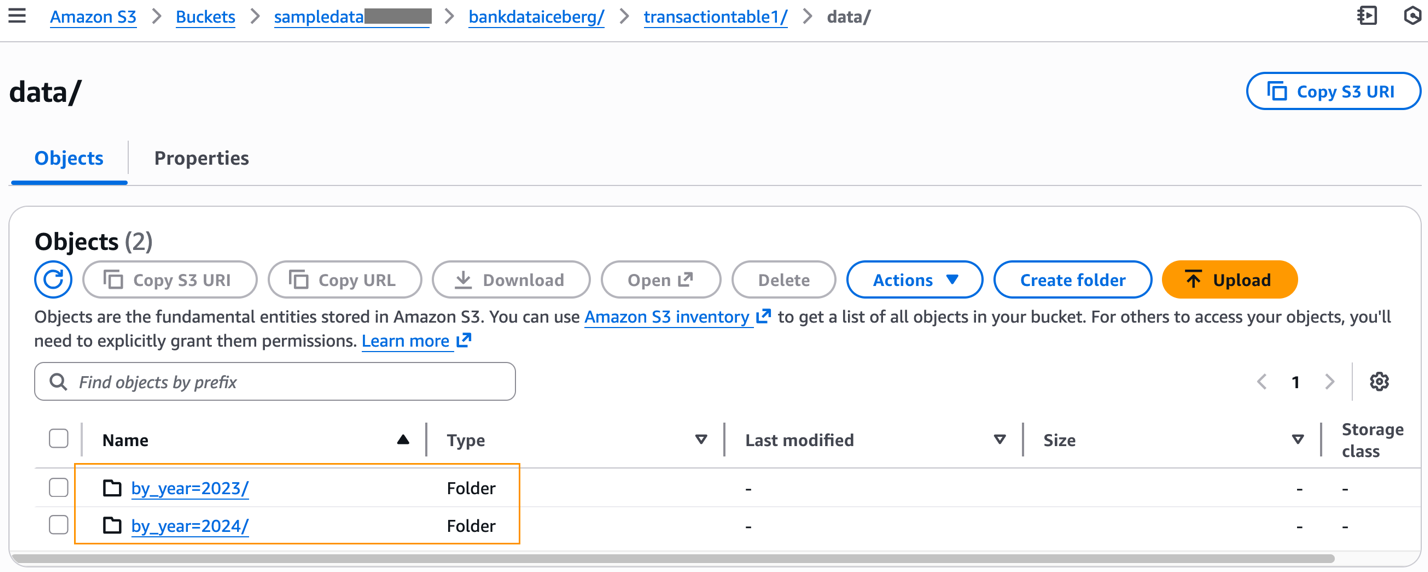
O knowledge pastas particionadas de acordo com nossa definição de tabela e arquivos de dados Parquet criados a partir de nosso comando INSERT estão disponíveis em cada prefixo particionado.

A seguir, atualizamos a tabela Iceberg adicionando uma nova partição, usando AtualizarTabela():
O updateicebergtable.json é o seguinte.
UpdateTable() modifica o esquema da tabela adicionando um arquivo JSON de metadados ao subjacente metadata pasta da tabela no Amazon S3.

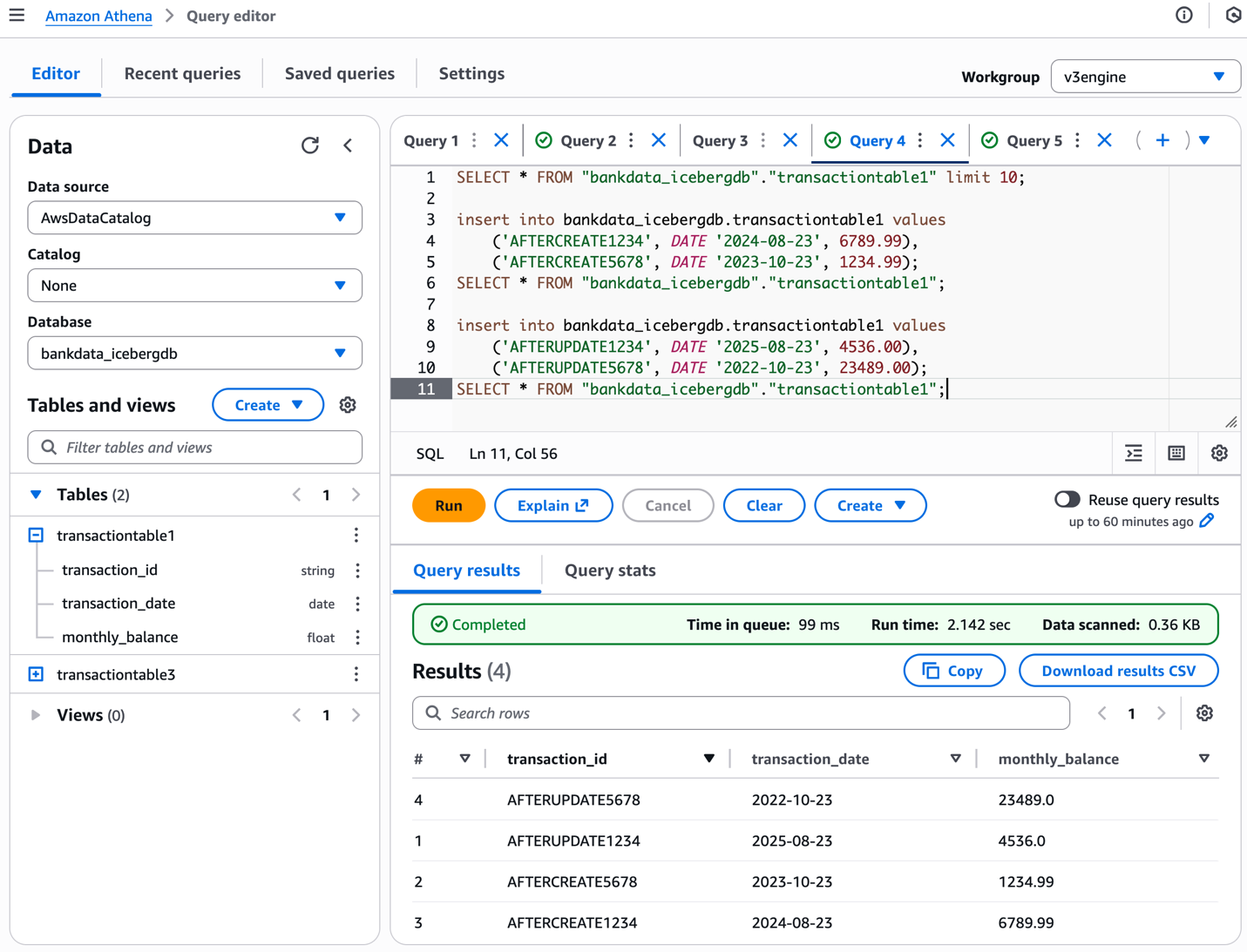
Inserimos valores na tabela usando Athena da seguinte forma:
A captura de tela a seguir mostra os resultados.
Inspecione as alterações correspondentes no knowledge pasta no native do Amazon S3 da tabela.
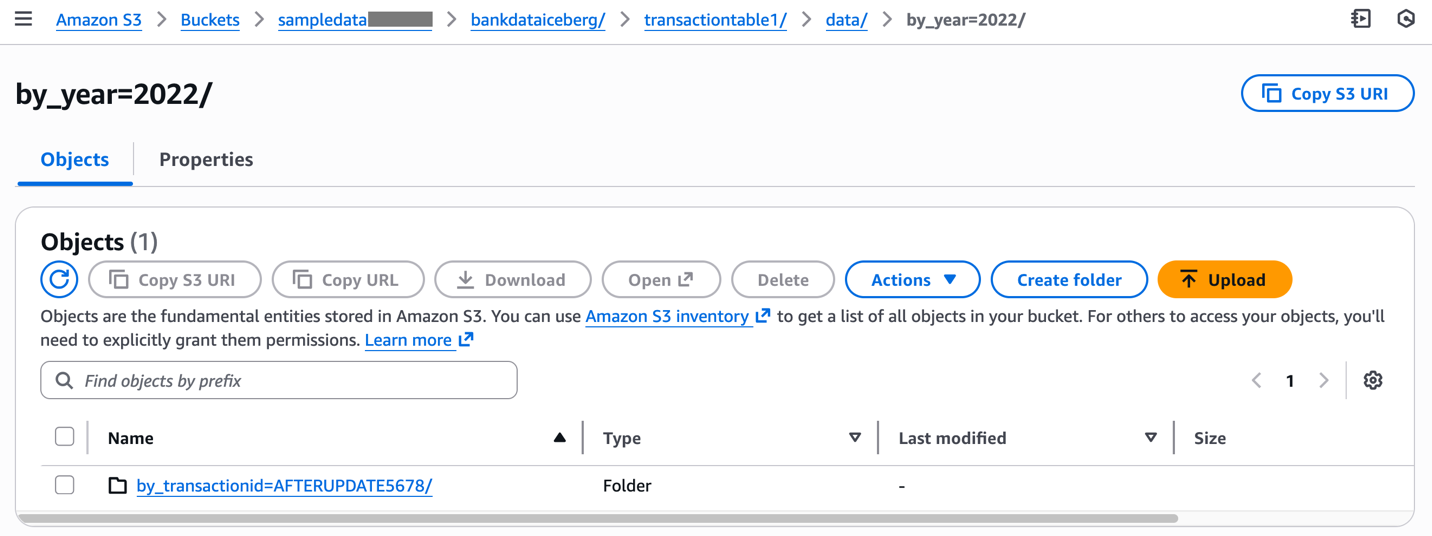
Este exemplo ilustrou como criar e atualizar tabelas Iceberg com partições usando comandos AWS CLI.
SDK para uso de Python
Os seguintes scripts Python ilustram o uso CriarTabela() e AtualizarTabela() para uma mesa Iceberg com divisórias:
Uso do CloudFormation
Use os seguintes modelos do CloudFormation para CreateTable() e UpdateTable(). Depois do CreateTable o modelo estiver completo, atualize a mesma pilha com o UpdateTable modelo criando um novo conjunto de alterações para sua pilha e executando-o.
Limpar
Para evitar incorrer em custos nas tabelas Iceberg criadas usando a AWS CLI, exclua as tabelas do Knowledge Catalog.
Conclusão
Nesta postagem, ilustramos como usar a AWS CLI para criar e atualizar tabelas Iceberg com partições no Knowledge Catalog. Também fornecemos o código e os modelos de amostra do SDK para Python e CloudFormation. Esperamos que isso ajude você a automatizar a criação e o gerenciamento de suas tabelas Iceberg com partições em seus pipelines de CI/CD e ambientes de produção. Experimente para seu próprio caso de uso e compartilhe seus comentários na seção de comentários.
Sobre os autores
Agradecimentos: Um agradecimento especial a todos que contribuíram para o desenvolvimento e lançamento deste recurso – Purvaja Narayanaswamy, Sachet Saurabh, Akhil Yendluri e Mohit Chandak.