 |
Hoje tenho o prazer de anunciar que Vetores Amazon S3 agora está disponível em geral com escala significativamente maior e capacidades de desempenho de nível de produção. S3 Vectors é o primeiro armazenamento de objetos em nuvem com suporte nativo para armazenar e consultar dados vetoriais. Você pode usá-lo para ajudar a reduzir o custo complete de armazenamento e consulta de vetores em até 90% quando comparado a soluções especializadas de banco de dados de vetores.
Desde anunciamos a prévia do S3 Vectors em julhofiquei impressionado com a rapidez com que você adotou esse novo recurso para armazenar e consultar dados vetoriais. Em pouco mais de quatro meses, você criou mais de 250 mil índices vetoriais e ingeriu mais de 40 bilhões de vetores, realizando mais de 1 bilhão de consultas (em 28 de novembro).
Agora você pode armazenar e pesquisar até 2 bilhões de vetores em um único índice, o que representa até 20 trilhões de vetores em um intervalo de vetores e um aumento de 40 vezes em relação aos 50 milhões por índice durante a visualização. Isso significa que você pode consolidar todo o seu conjunto de dados vetoriais em um índice, eliminando a necessidade de fragmentar vários índices menores ou implementar lógica de federação de consulta complexa.
O desempenho da consulta foi otimizado. Consultas pouco frequentes continuam a retornar resultados em menos de um segundo, com consultas mais frequentes agora resultando em latências em torno de 100 ms ou menos, tornando-o adequado para aplicações interativas, como IA conversacional e fluxos de trabalho multiagentes. Você também pode recuperar até 100 resultados de pesquisa por consulta, em vez dos 30 anteriores, fornecendo um contexto mais abrangente para aplicativos de geração aumentada de recuperação (RAG).
O desempenho de gravação também melhorou substancialmente, com suporte para até 1.000 transações PUT por segundo ao transmitir atualizações de vetor único para seus índices, proporcionando uma taxa de transferência de gravação significativamente maior para lotes pequenos. Esse rendimento mais alto oferece suporte a cargas de trabalho em que novos dados devem ser pesquisados imediatamente, ajudando você a ingerir pequenos corpora de dados rapidamente ou a lidar com muitas fontes simultâneas gravando simultaneamente no mesmo índice.
A arquitetura totalmente sem servidor elimina a sobrecarga de infraestrutura: não há infraestrutura para configurar nem recursos para provisionar. Você paga pelo que usa ao armazenar e consultar vetores. Esse armazenamento pronto para IA fornece acesso rápido a qualquer quantidade de dados vetoriais para dar suporte a todo o ciclo de vida de desenvolvimento de IA, desde a experimentação inicial e prototipagem até implantações de produção em grande escala. O S3 Vectors agora oferece a escala e o desempenho necessários para cargas de trabalho de produção em agentes de IA, inferência, pesquisa semântica e aplicativos RAG.
Duas integrações principais que foram lançadas na versão prévia agora estão disponíveis para o público geral. Você pode usar o S3 Vectors como um mecanismo de armazenamento de vetores para a base de conhecimento do Amazon Bedrock. Em explicit, você pode usá-lo para criar aplicativos RAG com escala e desempenho de nível de produção. Além disso, A integração do S3 Vectors com o Amazon OpenSearch já está disponível para todospara que você possa usar o S3 Vectors como sua camada de armazenamento de vetores enquanto usa o OpenSearch para recursos de pesquisa e análise.
Agora você pode usar vetores S3 em 14 regiões da AWS, expandindo de cinco regiões da AWS durante a visualização.
Vamos ver como funciona
Neste submit, demonstro como usar vetores S3 por meio do Console AWS e CLI.
Primeiro, crio um bucket S3 Vector e um índice.
echo "Creating S3 Vector bucket..."
aws s3vectors create-vector-bucket
--vector-bucket-name "$BUCKET_NAME"
echo "Creating vector index..."
aws s3vectors create-index
--vector-bucket-name "$BUCKET_NAME"
--index-name "$INDEX_NAME"
--data-type "float32"
--dimension "$DIMENSIONS"
--distance-metric "$DISTANCE_METRIC"
--metadata-configuration "nonFilterableMetadataKeys=AMAZON_BEDROCK_TEXT,AMAZON_BEDROCK_METADATA"A métrica de dimensão deve corresponder à dimensão do modelo usado para calcular os vetores. A métrica de distância indica ao algoritmo para calcular a distância entre os vetores. Suporte para vetores S3 cosseno e euclidiano distâncias.
Também posso usar o console para criar o bucket. Adicionamos a capacidade de configurar parâmetros de criptografia no momento da criação. Por padrão, os índices usam a criptografia em nível de bucket, mas posso substituir a criptografia em nível de bucket no nível do índice por uma criptografia personalizada Serviço de gerenciamento de chaves da AWS (AWS KMS) chave.
Também posso adicionar tags para o intervalo de vetores e o índice de vetores. Tags no índice vetorial auxiliam no controle de acesso e alocação de custos.
E agora posso gerenciar Propriedades e Permissões diretamente no console.
Da mesma forma, eu defino Metadados não filtráveis e eu configuro Criptografia parâmetros para o índice vetorial.
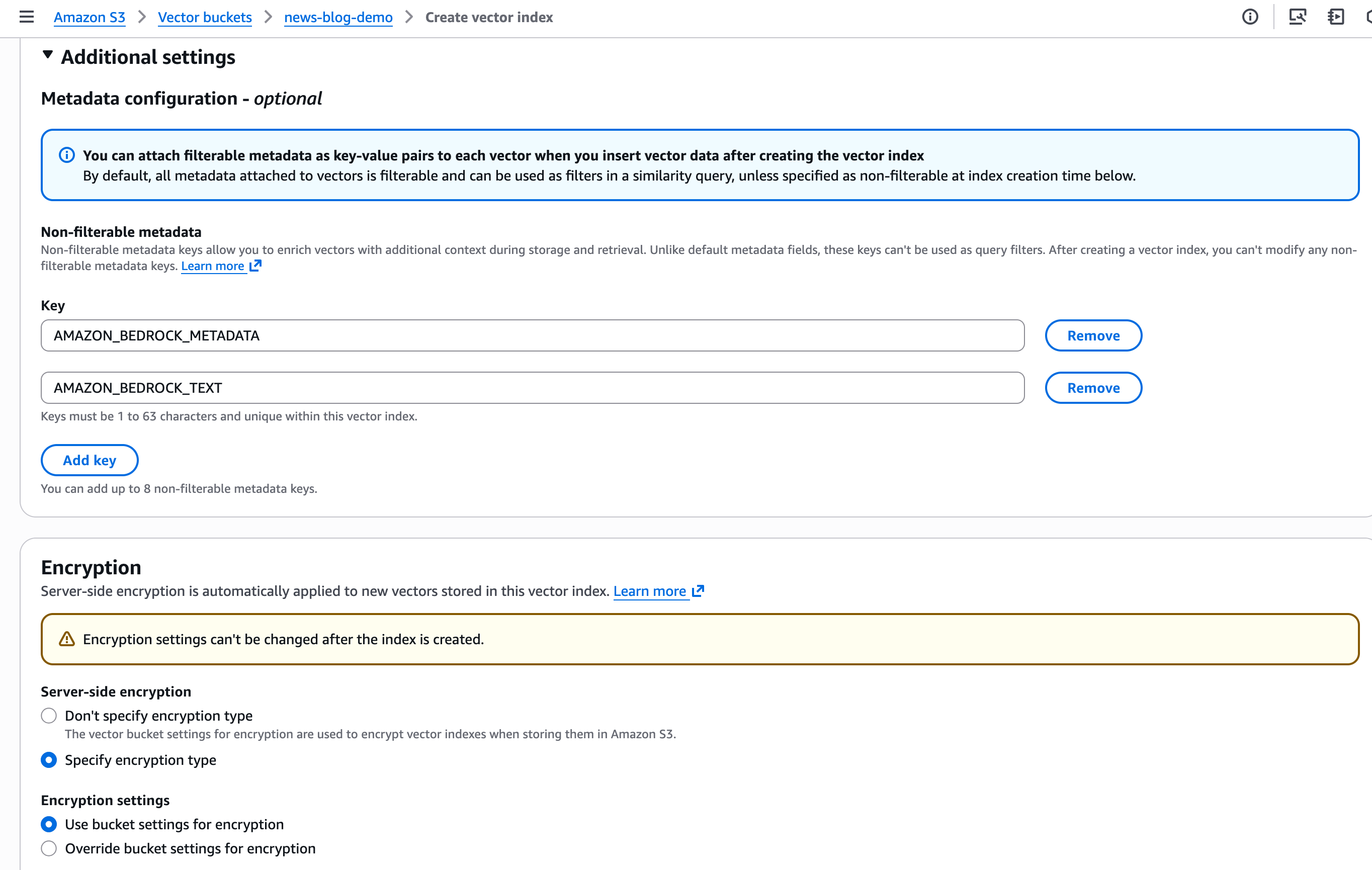
A seguir, crio e armazeno os embeddings (vetores). Para esta demonstração, ingiro meu companheiro constante: o AWS Type Information. Este é um documento de 800 páginas que descreve como escrever postagens, documentação técnica e artigos na AWS.
eu uso Bases de conhecimento da Amazon Bedrock para ingerir o documento PDF armazenado em um bucket S3 de uso geral. O Amazon Bedrock Data Bases lê o documento e o divide em partes chamadas pedaços. Em seguida, ele calcula os embeddings para cada pedaço com o Incorporações de texto do Amazon Titan mannequin e armazena os vetores e seus metadados em meu bucket de vetores recém-criado. As etapas detalhadas desse processo estão fora do escopo desta postagem, mas você pode ler as instruções na documentação.
Ao consultar vetores, você pode armazenar até 50 chaves de metadados por vetor, com até 10 marcadas como não filtráveis. Você pode usar as chaves de metadados filtráveis para filtrar resultados de consulta com base em atributos específicos. Portanto, você pode combinar a pesquisa por similaridade vetorial com condições de metadados para restringir os resultados. Você também pode armazenar mais metadados não filtráveis para obter informações contextuais maiores. A Amazon Bedrock Data Bases calcula e armazena os vetores. Ele também adiciona metadados grandes (a parte do texto authentic). Excluo esses metadados do índice pesquisável.
Existem outros métodos para ingerir seus vetores. Você pode tentar o CLI incorporado de vetores S3uma ferramenta de linha de comando que ajuda a gerar embeddings usando o Amazon Bedrock e armazená-los no S3 Vectors por meio de comandos diretos. Você também pode usar vetores S3 como um mecanismo de armazenamento vetorial para OpenSearch.
Agora estou pronto para consultar meu índice vetorial. Vamos imaginar que eu me pergunto como escrever “código aberto”. É “código aberto”, com hífen, ou “código aberto” sem hífen? Devo usar letras maiúsculas ou não? Quero pesquisar as seções relevantes do Guia de estilo da AWS relativas a “código aberto”.
# 1. Create embedding request
echo '{"inputText":"Ought to I write open supply or open-source"}' | base64 | tr -d 'n' > body_encoded.txt
# 2. Compute the embeddings with Amazon Titan Embed mannequin
aws bedrock-runtime invoke-model
--model-id amazon.titan-embed-text-v2:0
--body "$(cat body_encoded.txt)"
embedding.json
# Search the S3 Vectors index for related chunks
vector_array=$(cat embedding.json | jq '.embedding') &&
aws s3vectors query-vectors
--index-arn "$S3_VECTOR_INDEX_ARN"
--query-vector "{"float32": $vector_array}"
--top-k 3
--return-metadata
--return-distance | jq -r '.vectors() | "Distance: (.distance) | Supply: (.metadata."x-amz-bedrock-kb-source-uri" | cut up("/")(-1)) | Textual content: (.metadata.AMAZON_BEDROCK_TEXT(0:100))..."'O primeiro resultado mostra este JSON:
{
"key": "348e0113-4521-4982-aecd-0ee786fa4d1d",
"metadata": {
"x-amz-bedrock-kb-data-source-id": "0SZY6GYPVS",
"x-amz-bedrock-kb-source-uri": "s3://sst-aws-docs/awsstyleguide.pdf",
"AMAZON_BEDROCK_METADATA": "{"createDate":"2025-10-21T07:49:38Z","modifiedDate":"2025-10-23T17:41:58Z","supply":{"sourceLocation":"s3://sst-aws-docs/awsstyleguide.pdf"",
"AMAZON_BEDROCK_TEXT": "(redacted) open supply (adj., n.) Two phrases. Use open supply as an adjective (for instance, open supply software program), or as a noun (for instance, the code all through this tutorial is open supply). Do not use open-source, opensource, or OpenSource. (redacted)",
"x-amz-bedrock-kb-document-page-number": 98.0
},
"distance": 0.63120436668396
}Ele encontra a seção relevante no AWS Type Information. Devo escrever “código aberto” sem hífen. Ele até recuperou o número da página do documento authentic para me ajudar a cruzar a sugestão com o parágrafo relevante no documento de origem.
Mais uma coisa
A S3 Vectors também expandiu suas capacidades de integração. Agora você pode usar AWS CloudFormation para implantar e gerenciar seus recursos vetoriais, AWS PrivateLink para conectividade de rede privada e marcação de recursos para alocação de custos e controle de acesso.
Preço e disponibilidade
O S3 Vectors agora está disponível em 14 regiões da AWS, adicionando Ásia-Pacífico (Mumbai, Seul, Cingapura, Tóquio), Canadá (Central) e Europa (Irlanda, Londres, Paris, Estocolmo) às cinco regiões existentes desde a visualização (Leste dos EUA (Ohio, Norte da Virgínia), Oeste dos EUA (Oregon), Ásia-Pacífico (Sydney) e Europa (Frankfurt))
A definição de preço do Amazon S3 Vectors é baseada em três dimensões. Preços PUT é calculado com base no GB lógico de vetores que você carrega, onde cada vetor inclui seus dados vetoriais lógicos, metadados e chave. Custos de armazenamento são determinados pelo armazenamento lógico complete em seus índices. Consultar cobranças inclua uma cobrança por API mais uma cobrança de US$/TB com base no tamanho do seu índice (excluindo metadados não filtráveis). À medida que seu índice ultrapassa 100.000 vetores, você se beneficia de preços mais baixos em US$/TB. Como de costume, a página de preços do Amazon S3 contém os detalhes.
Para começar a usar o S3 Vectors, visite o Console Amazon S3. Você pode criar índices vetoriais, começar a armazenar seus embeddings e começar a construir aplicativos de IA escalonáveis. Para mais informações, confira o Guia do usuário do Amazon S3 ou o Referência de comando da AWS CLI.
Estou ansioso para ver o que você construirá com esses novos recursos. Por favor, compartilhe seus comentários através AWS re:Postagem ou o seu recurring Contatos do AWS Help.