
Aprendizagem supervisionada: a base da modelagem preditiva
Imagem do Autor
Nota do editor: Este artigo faz parte de nossa série sobre como visualizar os fundamentos do aprendizado de máquina.
Bem-vindo ao último capítulo de nossa série sobre como visualizar os fundamentos do aprendizado de máquina. Nesta série, nosso objetivo será dividir conceitos técnicos importantes e muitas vezes complexos em guias visuais intuitivos para ajudá-lo a dominar os princípios básicos da área. Esta entrada se concentra no aprendizado supervisionado, a base da modelagem preditiva.
A Fundação da Modelagem Preditiva
O aprendizado supervisionado é amplamente considerado a base da modelagem preditiva no aprendizado de máquina. Mas por que?
Em sua essência, é um paradigma de aprendizagem no qual um modelo é treinado em dados rotulados – exemplos onde tanto os recursos de entrada quanto os resultados corretos (verdade básica) são conhecidos. Ao aprender com esses exemplos rotulados, o modelo pode fazer previsões precisas sobre dados novos e inéditos.
Uma maneira útil de compreender a aprendizagem supervisionada é através da analogia de aprendendo com um professor. Durante o treinamento, o modelo vê exemplos junto com as respostas corretas, da mesma forma que um aluno recebe orientação e correção de um instrutor. Cada previsão que o modelo faz é comparada com o rótulo da verdade, suggestions é fornecido e ajustes são feitos para reduzir erros futuros. Com o tempo, esse processo orientado ajuda o modelo a internalizar a relação entre entradas e saídas.
O objetivo da aprendizagem supervisionada é aprender um mapeamento confiável de recursos para rótulos. Este processo gira em torno de três componentes essenciais:
- Primeiro é o dados de treinamentoque consiste em exemplos rotulados e serve como base para o aprendizado
- Segundo é o algoritmo de aprendizagemque ajusta iterativamente os parâmetros do modelo para minimizar o erro de previsão nos dados de treinamento
- Finalmente, o modelo treinado emerge desse processo, capaz de generalizar o que aprendeu para fazer previsões sobre novos dados
Os problemas de aprendizagem supervisionada geralmente se enquadram em duas categorias principais: Regressão as tarefas concentram-se na previsão de valores contínuos, como preços de casas ou leituras de temperatura; Classificação as tarefas, por outro lado, envolvem a previsão de categorias discretas, como identificar e-mails spam versus não-spam ou reconhecer objetos em imagens. Apesar de suas diferenças, ambos dependem do mesmo princípio básico de aprender com exemplos rotulados.
O aprendizado supervisionado desempenha um papel central em muitas aplicações de aprendizado de máquina do mundo actual. Normalmente requer conjuntos de dados grandes e de alta qualidade com rótulos confiáveis, e seu sucesso depende de quão bem o modelo treinado pode generalizar além dos dados nos quais foi treinado. Quando aplicado de forma eficaz, o aprendizado supervisionado permite que as máquinas façam previsões precisas e acionáveis em uma ampla variedade de domínios.
A visualização abaixo fornece um resumo conciso dessas informações para referência rápida. Você pode baixe aqui o PDF do infográfico em alta resolução.
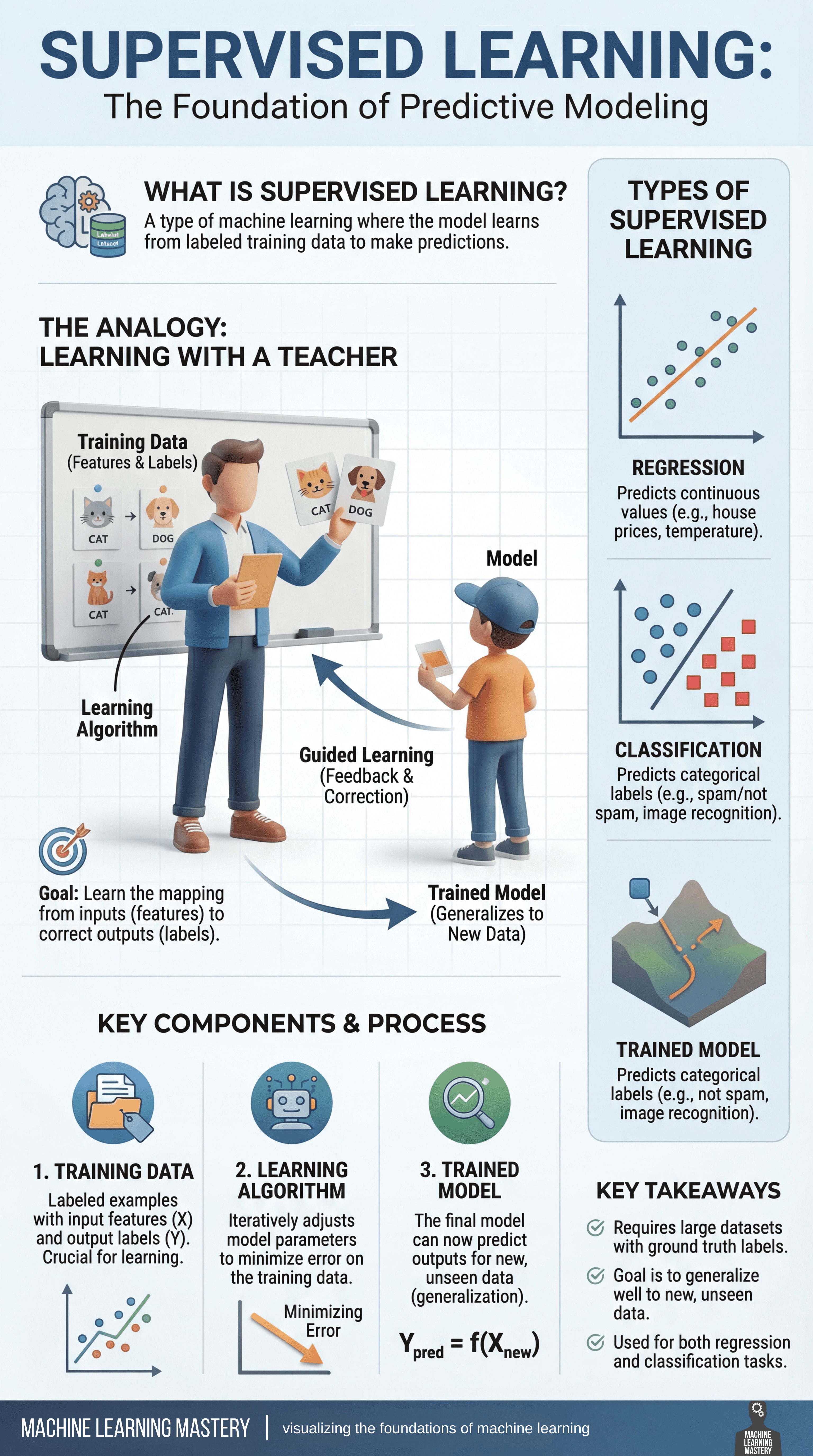
Aprendizado supervisionado: visualizando os fundamentos do aprendizado de máquina (clique para ampliar)
Imagem do Autor
Recursos de domínio de aprendizado de máquina
Estes são alguns recursos selecionados para aprender mais sobre aprendizagem supervisionada:
- Algoritmos de aprendizado de máquina supervisionados e não supervisionados – Este artigo para iniciantes explica as diferenças entre aprendizagem supervisionada, não supervisionada e semissupervisionada, descrevendo como os dados rotulados e não rotulados são usados e destacando algoritmos comuns para cada abordagem.
Conclusão principal: Saber quando usar dados rotulados e não rotulados é elementary para escolher o paradigma de aprendizagem correto. - Tutorial de regressão linear simples para aprendizado de máquina – Este tutorial prático e para iniciantes apresenta regressão linear simples, explicando como um modelo de linha reta é usado para descrever e prever a relação entre uma única variável de entrada e uma saída numérica.
Conclusão principal: A regressão linear simples modela relacionamentos usando uma linha definida por coeficientes aprendidos. - Regressão Linear para Aprendizado de Máquina – Este artigo introdutório fornece uma visão geral mais ampla da regressão linear, cobrindo como o algoritmo funciona, principais suposições e como ele é aplicado em fluxos de trabalho de aprendizado de máquina do mundo actual.
Conclusão principal: A regressão linear serve como um algoritmo de linha de base central para tarefas de previsão numérica. - 4 tipos de tarefas de classificação em aprendizado de máquina – Este artigo explica os quatro tipos principais de problemas de classificação – classificação binária, multiclasse, multirótulo e classificação desequilibrada – usando explicações claras e exemplos práticos.
Conclusão principal: A identificação correta do tipo de problema de classificação orienta a seleção do modelo e a estratégia de avaliação. - Um contra descanso e um contra um para classificação multiclasse – Este tutorial prático explica como classificadores binários podem ser estendidos para problemas multiclasse usando estratégias One-vs-Relaxation e One-vs-One, com orientação sobre quando usar cada uma.
Conclusão principal: Problemas multiclasses podem ser resolvidos decompondo-os em múltiplas tarefas de classificação binária.
Fique atento a entradas adicionais em nossa série sobre como visualizar os fundamentos do aprendizado de máquina.
Sobre Matheus Mayo
Matheus Mayo (@mattmayo13) possui mestrado em ciência da computação e pós-graduação em mineração de dados. Como editor-chefe da KDnuggets & Estatologiae editor colaborador em Domínio do aprendizado de máquinaMatthew pretende tornar acessíveis conceitos complexos de ciência de dados. Seus interesses profissionais incluem processamento de linguagem pure, modelos de linguagem, algoritmos de aprendizado de máquina e exploração de IA emergente. Ele é movido pela missão de democratizar o conhecimento na comunidade de ciência de dados. Matthew codifica desde os 6 anos de idade.