Os desenvolvedores de IA e ML geralmente trabalham com conjuntos de dados locais durante o pré-processamento dos dados. Recursos de engenharia e construção de protótipos facilitam isso sem a sobrecarga de um servidor completo. A comparação mais comum é entre SQLite, um banco de dados sem servidor lançado em 2000 e amplamente utilizado para transações leves, e DuckDB, introduzido em 2019 como o SQLite de análise, focado em consultas analíticas rápidas em processo. Embora ambos estejam incorporados, seus objetivos são diferentes. Neste artigo, compararemos DuckDB e SQLite para ajudá-lo a escolher a ferramenta certa para cada estágio do seu fluxo de trabalho de IA.
O que é SQLite?
SQLite é um mecanismo de banco de dados independente sem servidor. Ele cria um botão diretamente de um arquivo em disco. Ele tem configuração zero e ocupa pouco espaço. O banco de dados é todo armazenado em um arquivo que é.sqlite e as tabelas e índices estão todos contidos nesse arquivo. O mecanismo em si é uma biblioteca C incorporada ao seu aplicativo.
SQLite é um ÁCIDO-banco de dados compatível, embora seja simples. Isso o torna confiável nas transações e na integridade dos dados.
Os principais recursos incluem:
- Armazenamento orientado a linhas: Os dados são armazenados linha por linha. Isso torna a atualização ou recuperação de uma linha particular person bastante eficiente.
- Banco de dados de arquivo único: Todo o banco de dados está em um único arquivo. Isso permite que ele seja copiado ou transferido facilmente.
- Nenhum processo de servidor: A leitura e gravação direta no arquivo de banco de dados são feitas em sua aplicação. Nenhum servidor separado é necessário.
- Amplo suporte SQL: Ele é baseado na maior parte do SQL-2 e oferece suporte a junções, funções de janela e índices.
SQLite é frequentemente selecionado em aplicativos móveis e Web das Coisasbem como pequenos aplicativos da internet. É claro onde você precisa de uma solução simples para armazenar dados estruturados localmente e quando você precisa de inúmeras operações curtas de leitura e gravação.
O que é DuckDB?
DuckDB é um banco de dados em processo de análise de dados. É preciso a força do banco de dados SQL para aplicativos incorporados. Ele executará consultas analíticas complicadas de forma eficaz, sem um servidor. Este foco analítico é frequentemente a base de comparação entre DuckDB e SQLite.
As características importantes PatoDB são:
- Formato de armazenamento colunar: DuckDB armazena colunas de dados. Neste formato, é capaz de digitalizar e mesclar grandes conjuntos de dados a uma taxa muito maior. Ele lê apenas as colunas necessárias.
- Execução de consulta vetorizada: DuckDB foi projetado para realizar cálculos em blocos ou vetores, em vez de em uma única linha. Este método envolve a aplicação dos recursos atuais da CPU para computar em uma taxa maior.
- Consulta direta de arquivos: DuckDB pode consultar arquivos Parquet, CSV e Arrow diretamente. Não há necessidade de colocá-los no banco de dados.
- Integração profunda da ciência de dados: É compatível com Pandas, NumPy e R. Podem ser feitas perguntas ao DataFrame, como tabelas de banco de dados.
DuckDB pode ser usado para processar rapidamente análises interativas de dados em notebooks Jupyter e acelerar os fluxos de trabalho do Pandas. São necessários recursos de knowledge warehouse em um pacote pequeno e native.
Principais diferenças
Primeiro, aqui está uma tabela resumida comparando SQLite e DuckDB em aspectos importantes.
| Aspecto | SQLite (desde 2000) | DuckDB (desde 2019) |
| Finalidade Primária | Banco de dados OLTP incorporado (transações) | Banco de dados OLAP incorporado (análise) |
| Modelo de armazenamento | Baseado em linha (armazena linhas inteiras juntas) | Colunar (armazena colunas juntas) |
| Execução de consulta | Processamento iterativo linha por vez | Processamento em lote vetorizado |
| Desempenho | Excelente para transações pequenas e frequentes | Excelente para consultas analíticas em grandes volumes de dados |
| Tamanho dos dados | Otimizado para conjuntos de dados pequenos e médios | Lida com conjuntos de dados grandes e sem memória |
| Simultaneidade | Multileitor, gravador único (through bloqueios) | Multileitor, gravador único; execução de consulta paralela |
| Uso de memória | Pegada mínima de memória por padrão | Aproveita a memória para velocidade; pode usar mais RAM |
| Recursos SQL | SQL básico robusto com alguns limites | Amplo suporte SQL para análises avançadas |
| Índices | Índices de árvore B são frequentemente necessários | Depende de varreduras de colunas; indexação é menos comum |
| Integração | Suportado em quase todos os idiomas | Integração nativa com Pandas, Arrow, NumPy |
| Formatos de arquivo | Arquivo proprietário; pode importar/exportar CSVs | Pode consultar diretamente Parquet, CSV, JSON, Arrow |
| Transações | Totalmente compatível com ACID | ACID em um único processo |
| Paralelismo | Execução de consulta de thread único | Execução multithread para uma única consulta |
| Casos de uso típicos | Aplicativos móveis, dispositivos IoT, armazenamento native de aplicativos | Cadernos de ciência de dados, experimentos locais de ML |
| Licença | Domínio público | Licença MIT (código aberto) |
Esta tabela revela que o SQLite se concentra na confiabilidade e nas operações de transações. DuckDB é otimizado para suportar consultas analíticas rápidas em massive knowledge. Agora vamos discutir cada um deles.
Prática em Python: da teoria à prática
Veremos como utilizar ambos os bancos de dados em Pitão. É um ambiente de desenvolvimento de IA de código aberto.
Usando SQLite
Esta é uma representação fácil do SQLite Python. Desenvolveremos uma tabela, inseriremos dados e executaremos uma consulta.
import sqlite3
# Hook up with a SQLite database file
conn = sqlite3.join("instance.db")
cur = conn.cursor()
# Create a desk
cur.execute(
"""
CREATE TABLE customers (
id INTEGER PRIMARY KEY,
identify TEXT,
age INTEGER
);
"""
)
# Insert data into the desk
cur.execute(
"INSERT INTO customers (identify, age) VALUES (?, ?);",
("Alice", 30)
)
cur.execute(
"INSERT INTO customers (identify, age) VALUES (?, ?);",
("Bob", 35)
)
conn.commit()
# Question the desk
for row in cur.execute(
"SELECT identify, age FROM customers WHERE age > 30;"
):
print(row)
# Anticipated output: ('Bob', 35)
conn.shut()Saída:

O banco de dados neste caso é mantido no exemplo.db arquivo. Criamos uma tabela, adicionamos duas linhas a ela e executamos uma consulta simples. SQLite faz você carregar dados nas tabelas e depois consultar. Caso você possua um arquivo CSV, deverá primeiro importar as informações.
Usando DuckDB
Ainda assim, é hora de repetir esta opção com DuckDB. Também chamaremos sua atenção para as conveniências da ciência de dados.
import duckdb
import pandas as pd
# Hook up with an in-memory DuckDB database
conn = duckdb.join()
# Create a desk and insert knowledge
conn.execute(
"""
CREATE TABLE customers (
id INTEGER,
identify VARCHAR,
age INTEGER
);
"""
)
conn.execute(
"INSERT INTO customers VALUES (1, 'Alice', 30), (2, 'Bob', 35);"
)
# Run a question on the desk
outcome = conn.execute(
"SELECT identify, age FROM customers WHERE age > 30;"
).fetchall()
print(outcome) # Anticipated output: (('Bob', 35))Saída:
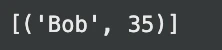
O uso simples se assemelha ao uso básico. No entanto, dados externos também podem ser consultados pelo DuckDB.
Vamos gerar um conjunto de dados aleatório para consulta:
import pandas as pd
import numpy as np
# Generate random gross sales knowledge
np.random.seed(42)
num_entries = 1000
knowledge = {
"class": np.random.selection(
("Electronics", "Clothes", "Dwelling Items", "Books"),
num_entries
),
"worth": np.spherical(
np.random.uniform(10, 500, num_entries),
2
),
"area": np.random.selection(
("EUROPE", "AMERICA", "ASIA"),
num_entries
),
"sales_date": (
pd.to_datetime("2023-01-01")
+ pd.to_timedelta(
np.random.randint(0, 365, num_entries),
unit="D"
)
)
}
sales_df = pd.DataFrame(knowledge)
# Save to sales_data.csv
sales_df.to_csv("sales_data.csv", index=False)
print("Generated 'sales_data.csv' with 1000 entries.")
print(sales_df.head())Saída:
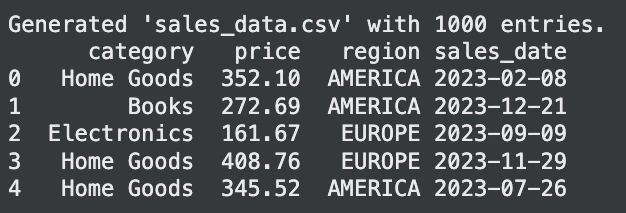
Agora, vamos consultar esta tabela:
# Assume 'sales_data.csv' exists
# Instance 1: Querying a CSV file straight
avg_prices = conn.execute(
"""
SELECT
class,
AVG(worth) AS avg_price
FROM 'sales_data.csv'
WHERE area = 'EUROPE'
GROUP BY class;
"""
).fetchdf() # Returns a Pandas DataFrame
print(avg_prices.head())
# Instance 2: Querying a Pandas DataFrame straight
df = pd.DataFrame({
"id": vary(1000),
"worth": vary(1000)
})
outcome = conn.execute(
"SELECT COUNT(*) FROM df WHERE worth % 2 = 0;"
).fetchone()
print(outcome) # Anticipated output: (500,)Saída:
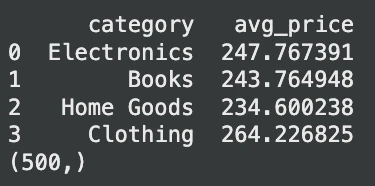
Nesse caso, o DuckDB lê o arquivo CSV instantaneamente. Nenhuma etapa importante é necessária. Também é capaz de consultar um Pandas Quadro de dados. Essa flexibilidade take away grande parte do código de carregamento de dados e simplifica os pipelines de IA.
Arquitetura: por que seu desempenho é tão diferente
As diferenças no desempenho do SQLite e do DuckDB têm a ver com seus mecanismos de armazenamento e consulta.
- Modelo de armazenamento: SQLite é baseado em linha. Ele agrupa todos os dados de uma linha nele. Isso é muito bom para atualizar um único registro. No entanto, não é rápido com análises. Supondo que você exact apenas de uma única coluna, o SQLite ainda terá que ler todos os dados de cada linha. DuckDB é orientado a colunas. Ele coloca todos os valores de uma coluna em uma única coluna. Isso é splendid para análises. Uma consulta como
SELECT AVG(age)só lê o idade coluna que é muito mais rápida. - Execução de consulta: SQLite uma consulta por linha. Isso economiza memória quando se trata de pequenas consultas. DuckDB é baseado em uma execução vetorizada. Funciona com dados em grandes lotes. Essa técnica usa CPUs atuais para acelerar significativamente em grandes varreduras e junções. Também é capaz de executar vários threads para executar uma única consulta por vez.
- Memória e comportamento no disco: SQLite foi projetado para usar memória mínima. Ele lê do disco conforme necessário. DuckDB usa memória para aumentar a velocidade. Ele pode executar dados maiores que a RAM disponível em execução fora do núcleo. Isso implica que o DuckDB pode consumir RAM adicional, mas é muito mais rápido em uma tarefa analítica. Foi demonstrado que no DuckDB as consultas de agregação são 10 a 100 vezes mais rápidas do que no SQLite.
O veredicto: quando usar DuckDB vs. SQLite
Esta é uma boa diretriz a ser seguida em seus projetos de IA e aprendizado de máquina.
| Aspecto | Use SQLite quando | Use DuckDB quando |
|---|---|---|
| Objetivo principal | Você precisa de um banco de dados transacional leve | Você precisa de análises locais rápidas |
| Tamanho dos dados | Baixo quantity de dados, até algumas centenas de MBs | Conjuntos de dados médios a grandes |
| Tipo de carga de trabalho | Inserções, atualizações e pesquisas simples | Agregações, junções e varreduras de tabelas grandes |
| Necessidades de transação | Pequenas atualizações frequentes com integridade transacional | Consultas analíticas com muita leitura |
| Manipulação de arquivos | Dados armazenados dentro do banco de dados | Consulte arquivos CSV ou Parquet diretamente |
| Foco no desempenho | Ocupação mínima e simplicidade | Desempenho analítico de alta velocidade |
| Integração | Aplicativos móveis, sistemas embarcados, IoT | Acelerando a análise baseada em Pandas |
| Execução paralela | Não é uma prioridade | Usa vários núcleos de CPU |
| Caso de uso típico | Estado do aplicativo e armazenamento leve | Exploração e análise de dados locais |
Conclusão
Tanto o SQLite quanto o DuckDB são bancos de dados integrados fortes. SQLite é um armazenamento de dados leve muito bom e uma ferramenta de transação fácil. No entanto, o DuckDB pode acelerar significativamente o processamento de dados e a prototipagem de desenvolvedores de IA que operam com massive knowledge. Isso porque ao conhecer suas diferenças, você saberá a ferramenta certa para utilizar nas diferentes tarefas. No caso de processos contemporâneos de análise de dados e aprendizado de máquina, o DuckDB pode economizar muito tempo com um benefício considerável de desempenho.
Perguntas frequentes
R. Não, eles têm outros usos. DuckDB é usado para acessar análises rápidas (OLAP), enquanto SQLite é usado para entrar em transações confiáveis. Selecione de acordo com sua carga de trabalho.
R. O SQLite normalmente é mais adequado para aplicativos da Internet que possuem um grande número de leituras e gravações pequenas e comunicantes porque possui um modelo transacional sólido e modo WAL.
R. Sim, com a maioria dos trabalhos de grande escala, como agrupamentos e junções, o DuckDB pode ser muito mais rápido que o Pandas devido ao seu mecanismo vetorizado paralelo.
Harsh Mishra é um engenheiro de IA/ML que passa mais tempo conversando com grandes modelos de linguagem do que com humanos reais. Apaixonado por GenAI, PNL e por tornar as máquinas mais inteligentes (para que ainda não o substituam). Quando não está otimizando modelos, ele provavelmente está otimizando a ingestão de café. 🚀☕
Faça login para continuar lendo e desfrutar de conteúdo com curadoria de especialistas.