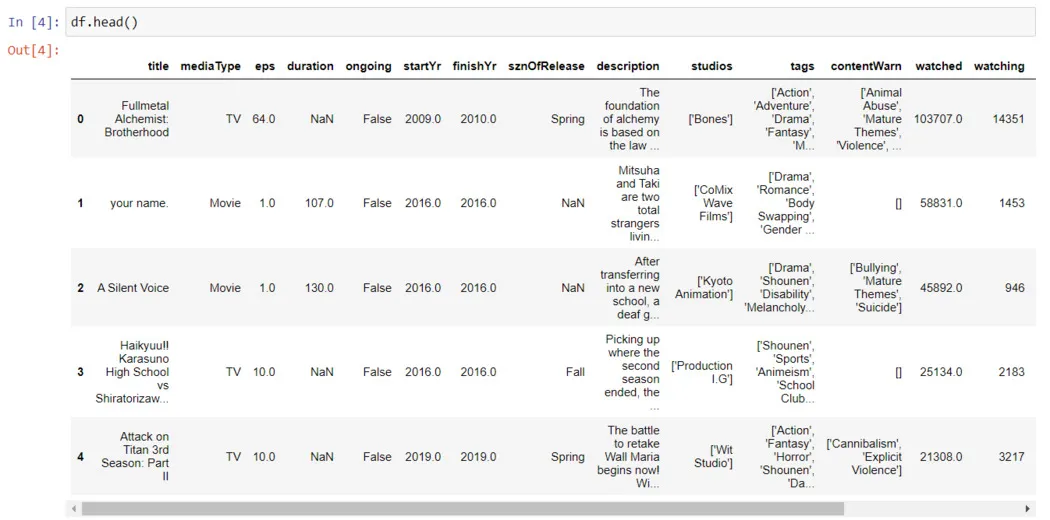
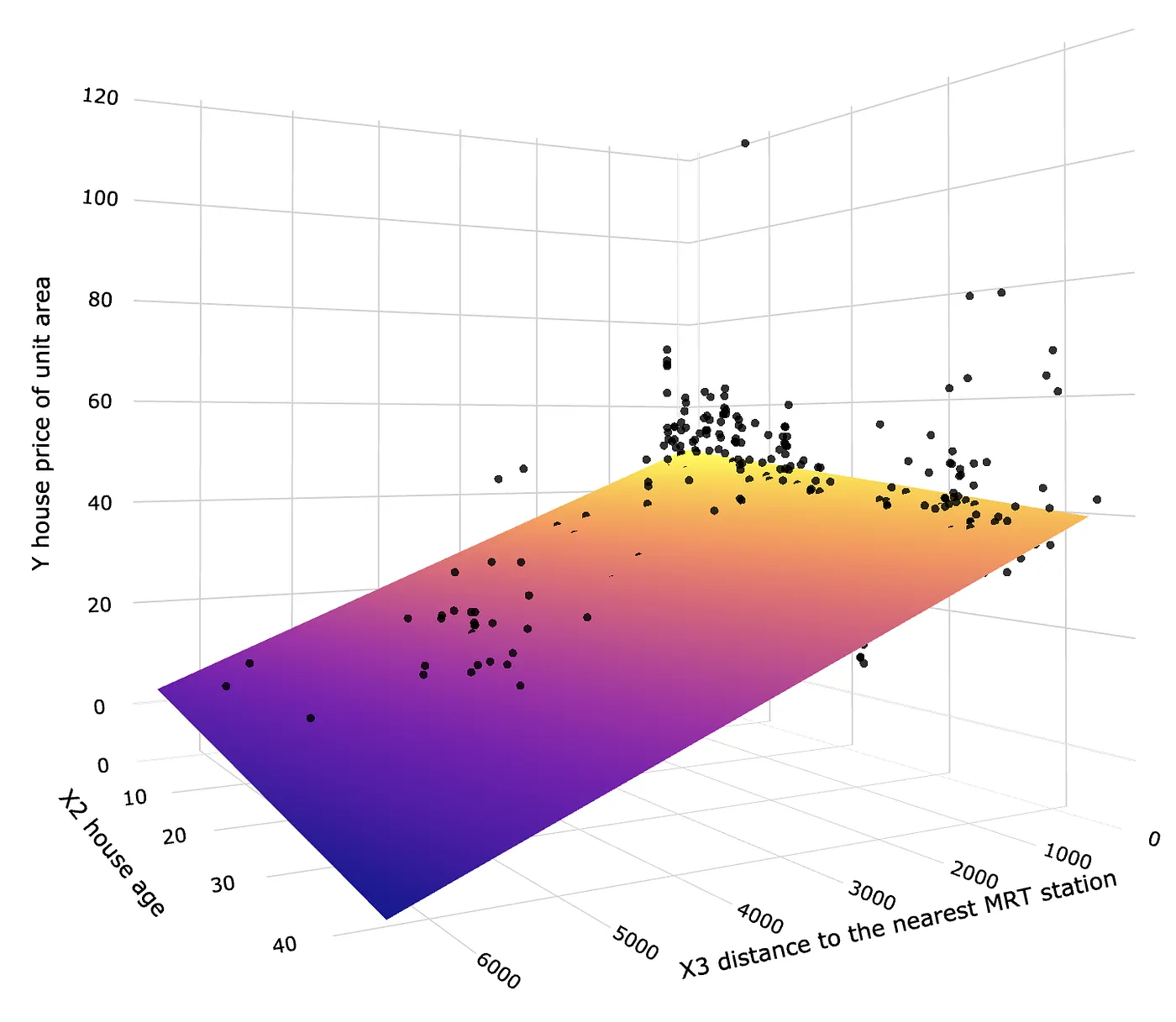
Python domina a IA e o aprendizado de máquina por um motivo simples: seu ecossistema é incrível. A maioria dos projetos é construída em um pequeno conjunto de bibliotecas que lidam com tudo, desde o carregamento de dados até o aprendizado profundo em escala. Conhecer essas bibliotecas torna todo o processo de desenvolvimento rápido e fácil.
Vamos dividi-los em um ordem prática. Começando com os fundamentos, depois com a IA e concluindo com o aprendizado de máquina.
Bibliotecas básicas de ciência de dados
Estes não são negociáveis. Se você tocar nos dados, você os usará. Seus fundamentos em IA/ML dependem da familiaridade com eles.
1. NumPy – Python Numérico

É aqui que tudo realmente começa. Se Pitão é a língua, NumPy é o cérebro matemático por trás disso.
Por que? As listas Python são de tipos de dados heterogêneos, devido aos quais possuem verificação de tipo implícita quando uma operação é realizada neles. Listas numpy são homogêneas! Significa que o tipo dos dados é definido durante a inicialização, ignorando a verificação de tipo e permitindo operações mais rápidas.
Usado para:
- Matemática vetorizada
- Álgebra linear
- Amostragem aleatória
Quase todos os sérios AM ou DL biblioteca depende silenciosamente do NumPy fazendo matemática rápida de array em segundo plano.
Instale usando: pip set up numpy
2. Pandas – Dados do painel
Pandas é o que transforma dados confusos em algo sobre o qual você pode raciocinar. Parece um Excel com esteróides, mas com lógica e reprodutibilidade reais, em vez de erros humanos silenciosos. Pandas brilha especialmente quando é usado para processar grandes conjuntos de dados.
Usado para:
- Limpeza de dados
- Engenharia de recursos
- Agregações e junções
Ele permite manipulação, limpeza e análise eficientes de dados estruturados, tabulares ou de série temporal.
Instale usando: pip set up pandas
3. SciPy – Python Científico
SciPy é para quando NumPy sozinho não é suficiente. Fornece ferramentas científicas pesadas que aparecem em problemas reais, desde otimização até processamento de sinais e modelagem estatística.
Usado para:
- Otimização
- Estatísticas
- Processamento de sinal
Best para quem busca funções científicas e matemáticas em um só lugar.
Instale usando: pip set up scipy
Bibliotecas de Inteligência Synthetic
É aqui que vivem as redes neurais. Os fundamentos da ciência de dados seriam construídos para isso.
4. TensorFlow – Fluxo Tensor
A plataforma de aprendizagem profunda ponta a ponta do Google. TensoFlow foi desenvolvido para quando seu modelo precisar deixar seu laptop computer e sobreviver no mundo actual. É opinativo, estruturado e projetado para implantar modelos em grande escala.
Usado para:
- Redes Neurais
- Treinamento distribuído
- Implantação de modelo
Para quem procura um ecossistema robusto em inteligência synthetic e aprendizado de máquina.
Instale usando: pip set up tensorflow
5. PyTorch – Tocha Python
Estrutura de pesquisa em primeiro lugar da Meta. PyTorch parece mais escrever Python regular que treina redes neurais. É por isso que os pesquisadores adoram: menos abstrações, mais controle e muito menos luta contra o framework.
Usado para:
- Prototipagem de pesquisa
- Arquiteturas personalizadas
- Experimentação
Perfeito para quem quer facilitar a entrada IA.
Instale usando: pip set up torch
6. OpenCV – Visão Computacional de Código Aberto
OpenCV é como as máquinas começam a ver o mundo. Ele lida com todos os detalhes de imagens e vídeos para que você possa se concentrar em problemas de visão de nível superior, em vez de matemática de pixels.
Usado para:
- Detecção de rosto
- Rastreamento de objetos
- Pipelines de processamento de imagem
O balcão único para entusiastas de processamento de imagens que desejam integrá-lo ao aprendizado de máquina.
Instale usando: pip set up cv2
Bibliotecas de aprendizado de máquina
É aqui que os modelos começam a acontecer.
7. Scikit-learn – Equipment Científico para Aprendizagem
Scikit-learn é a biblioteca que ensina o que realmente é o aprendizado de máquina. APIs limpas, toneladas de algoritmos e abstração suficiente para aprender sem esconder como as coisas funcionam.
Usado para:
- Classificação
- Regressão
- Agrupamento
- Avaliação do modelo
Para alunos de ML que desejam integração perfeita com a pilha de ciência de dados Python, Scikit-aprender é a escolha certa.
Instale usando: pip set up scikit-learn
8. XGBoost – Aumento extremo de gradiente
XGBoost é a razão pela qual as redes neurais não vencem automaticamente em dados tabulares. É brutalmente eficaz, otimizado e ainda é uma das bases mais fortes do ML do mundo actual.
Usado para:
- Processamento de dados tabulares
- Previsão estruturada
- Reconhecimento da importância do recurso
Para treinadores de modelos que desejam velocidade excepcional e regularização integrada para evitar overfitting.
Instale usando: pip set up xgboost
9. LightGBM – Máquina de aumento de gradiente de luz
A alternativa mais rápida da Microsoft ao XGBoost. LightGBM existe para quando o XGBoost começa a parecer lento ou pesado. Ele foi projetado para oferecer velocidade e eficiência de memória, especialmente quando seu conjunto de dados é enorme ou de alta dimensão.
Usado para:
- Processamento de dados de alta dimensão
- Treinamento de baixa latência
- ML em grande escala
Para quem quer um impulso no próprio XGBoost.
Instale usando: pip set up lightgbm
10. CatBoost – Impulso Categórico

CatBoost é o que você procura quando dados categóricos se tornam uma dor. Ele lida com categorias de maneira inteligente e pronta para uso, para que você gaste menos tempo codificando e mais tempo modelando.
Usado para:
- Conjuntos de dados categóricos pesados
- Engenharia de recursos mínimos
- Modelos de linha de base fortes
Instale usando: pip set up cat enhance
Tomada Ultimate
Seria difícil criar um projeto de IA/ML desprovido das bibliotecas anteriores. Todo engenheiro sério de IA eventualmente atinge todos os 10. O caminho de aprendizagem traditional das bibliotecas Python mencionadas anteriormente é assim:
Pandas → NumPy → Scikit-aprender → XGBoost → PyTorch → TensorFlow
Este procedimento garante que o aprendizado vá desde o básico até os frameworks avançados que são construídos a partir dele. Mas isso não é de forma alguma descritivo. Você pode escolher o pedido que mais lhe convier ou escolher qualquer uma dessas bibliotecas, com base em suas necessidades.
Perguntas frequentes
R. Comece com Pandas e NumPy, depois vá para Scikit-learn antes de tocar nas bibliotecas de aprendizado profundo.
R. O PyTorch é preferido para pesquisa e experimentação, enquanto o TensorFlow é desenvolvido para produção e implantação em larga escala.
A. Use CatBoost quando seu conjunto de dados tiver muitos recursos categóricos e você desejar um pré-processamento mínimo.
Sou especializado em revisar e refinar pesquisas, documentação técnica e conteúdo orientados por IA relacionados a tecnologias emergentes de IA. Minha experiência abrange treinamento de modelos de IA, análise de dados e recuperação de informações, o que me permite criar conteúdo que seja tecnicamente preciso e acessível.
Faça login para continuar lendo e desfrutar de conteúdo com curadoria de especialistas.