Para a maioria das equipes de dados, o desempenho não se trata mais de um ajuste único. Trata-se de análises ficando mais rápidas à medida que os dados, os usuários e a governança aumentam, sem aumentar os custos.
Com Blocos de dados SQL (DBSQL)essa expectativa está incorporada na plataforma. Em 2025, média o desempenho em cargas de trabalho de produção melhorou em até 40%sem ajuste, sem reescrita de consulta e sem necessidade de intervenção handbook.
A história maior vai além de um único benchmark. O desempenho melhorou em toda a plataforma, desde carregamentos mais rápidos de painéis e pipelines mais eficientes até consultas que permanecem responsivas mesmo com governança e dados compartilhados em vigor, enquanto a análise geoespacial e as funções de IA continuam a escalar sem complexidade adicional.
O objetivo permanece simples: agilize as cargas de trabalho e reduza o custo whole por padrão. Com DBSQL Serverless, Unity Catalog Managed Tables e Predictive Optimization, as melhorias são aplicadas automaticamente em todo o seu ambiente, para que as cargas de trabalho existentes sejam beneficiadas à medida que o mecanismo evolui.
Esta postagem detalha os ganhos de desempenho entregues em 2025 em todo o mecanismo de consulta, Catálogo de Unidade, Compartilhamento Deltaarmazenamento, SQL espacial e funções de IA.
Desempenho rápido de consultas em todas as cargas de trabalho
O Databricks SQL mede o desempenho usando milhões de consultas reais de clientes que são executadas repetidamente na produção. Ao acompanhar como essas cargas de trabalho mudam ao longo do tempo, medimos o impacto actual das melhorias e otimizações da plataforma, em vez de benchmarks isolados.
Em 2025, o Databricks SQL proporcionou ganhos de desempenho consistentes em todos os principais tipos de carga de trabalho. Essas melhorias se aplicam por padrão por meio de otimizações no nível do mecanismo, como Predictive Question Execution e Photon Vectorized Shuffle, sem exigir alterações de configuração.
- Cargas de trabalho exploratórias obtiveram os maiores ganhos, rodando em média 40% mais rápido e permitindo que analistas e cientistas de dados iterem mais rapidamente em grandes conjuntos de dados.
- Inteligência de negócios as cargas de trabalho melhoraram cerca de 20%, resultando em painéis mais responsivos e análises interativas mais suaves sob simultaneidade.
- Cargas de trabalho de ETL também se beneficiou, rodando aproximadamente 10% mais rápido e encurtando os tempos de execução do pipeline sem retrabalho.

Se avaliou o Databricks SQL pela última vez há um ano, as suas cargas de trabalho existentes já estão a funcionar mais rapidamente hoje.
Análises que permanecem rápidas à medida que a governança aumenta com o Unity Catalog
À medida que os conjuntos de dados crescem, a governança muitas vezes se torna uma fonte oculta de latência. Verificações de permissão, acesso a metadados e pesquisas de linhagem podem retardar as consultas, especialmente em ambientes interativos e de alta simultaneidade.
Em 2025, o Unity Catalog reduziu significativamente essa sobrecarga. Latência de catálogo ponta a ponta melhorada em até 10ximpulsionado por otimizações no serviço de catálogo, na pilha de rede, no cliente Databricks Runtime e nos serviços dependentes.
O resultado é visível onde é mais importante:
- Painéis permaneça responsivo mesmo com controles de acesso refinados.
- Cargas de trabalho de alta simultaneidade escalar sem gargalos de acesso aos metadados.
- Análise interativa sinta-se mais rápido à medida que os usuários exploram dados governados em grande escala.
As equipes não precisam mais escolher entre governança forte e desempenho. Com o Unity Catalog, a análise permanece rápida à medida que a governança se expande para mais dados e mais usuários.
Delta Sharing, dados compartilhados que funcionam como dados nativos
O compartilhamento de dados entre equipes ou organizações tradicionalmente tem um custo. As consultas em tabelas compartilhadas geralmente eram executadas de forma mais lenta e as otimizações eram aplicadas de maneira desigual em comparação aos dados nativos.
Em 2025, o Databricks SQL preencheu essa lacuna. Através de melhorias na execução de consultas e propagação de estatísticas, as consultas em tabelas compartilhadas por meio do Delta Sharing foram executadas até 30% mais rápidoalinhando o desempenho dos dados compartilhados com as tabelas nativas.

Essa mudança é mais importante em cenários em que os dados externos precisam se comportar como dados internos. Mercados de dados, análises entre organizações e relatórios orientados por parceiros agora podem ser executados em conjuntos de dados compartilhados sem sacrificar a interatividade ou a previsibilidade.
Com o Delta Sharing, as equipes podem compartilhar dados governados de forma ampla, preservando as expectativas de desempenho para análises modernas.
Menor custo de armazenamento, otimizações automáticas integradas
À medida que os volumes de dados aumentam, a eficiência do armazenamento torna-se uma parte maior do custo whole. A compactação desempenha um papel crítico, mas a escolha de formatos e o gerenciamento de migrações tradicionalmente acrescentam sobrecarga operacional.
Em 2025, o Databricks tornou a compactação Zstandard o padrão para todas as novas tabelas gerenciadas do catálogo do Unity. Zstandard é um formato de compressão de código aberto que oferece até 40% de economia de custos de armazenamento em comparação com formatos mais antigos, sem degradar o desempenho da consulta.

Esses benefícios se aplicam automaticamente a novas tabelas, e as tabelas existentes também podem ser migradas para o Zstandard, com ferramentas de migração simples disponíveis em breve. Grandes tabelas de fatos, conjuntos de dados de longa retenção e domínios em rápido crescimento apresentam reduções imediatas de custos sem alterações na forma como as consultas são escritas ou executadas.
O resultado é um custo de armazenamento mais baixo por padrão, fornecido sem sacrificar o desempenho ou adicionar novas etapas de ajuste.
Análise geoespacial sem sistemas especializados
A análise geoespacial impõe grandes demandas à execução de consultas. Junções espaciais, consultas de intervalo e cálculos geométricos exigem muita computação e, em escala, geralmente exigem sistemas especializados ou ajustes cuidadosos.
Em 2025, o Databricks SQL melhorou significativamente o desempenho destas cargas de trabalho. Consultas SQL espaciais foram executadas até 17 vezes mais rápidoimpulsionado por otimizações no nível do mecanismo, como indexação de árvore R, junções espaciais otimizadas no Photon e otimização de junção de intervalo inteligente.
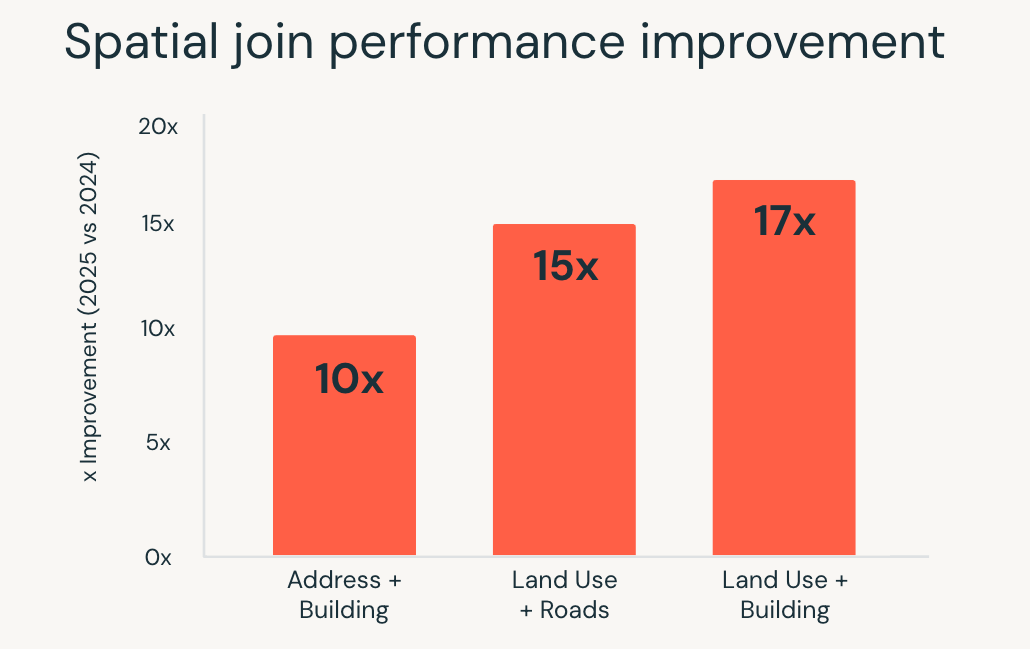
Essas melhorias permitem que as equipes trabalhem com dados de localização usando SQL padrão, enquanto o mecanismo lida com a complexidade da execução automaticamente. Casos de uso como análise de localização em tempo actual, delimitação geográfica em grande escala e enriquecimento geográfico são executados de forma mais rápida e consistente à medida que os volumes de dados aumentam.
A análise espacial não requer mais ferramentas separadas ou otimização handbook. Cargas de trabalho geoespaciais complexas são dimensionadas diretamente no Databricks SQL.
Funções de IA, IA escalonável diretamente em SQL
A aplicação de IA aos dados tradicionalmente exige trabalho fora do warehouse. A classificação de texto, a análise de documentos e a tradução muitas vezes significavam a construção de pipelines separados, o gerenciamento da infraestrutura do modelo e a integração dos resultados em fluxos de trabalho analíticos.
As funções de IA simplificam esse modelo trazendo a IA diretamente para o SQL. Em 2025, o Databricks SQL expandiu significativamente a escala e o desempenho destas capacidades. Nova infraestrutura otimizada em lote entregue desempenho até 85x mais rápido para funções como ai_classify, ai_summarizee ai_translatepermitindo grandes trabalhos em lote que antes demoravam horas para serem concluídos em minutos.
Databricks também introduziu ai_parse_document e otimizou-o rapidamente para escala. Modelos específicos para compreensão de documentos, hospedados no Databricks Mannequin Serving, entregues desempenho até 30x mais rápido em comparação com alternativas de uso geral, tornando prático processar grandes volumes de conteúdo não estruturado diretamente em fluxos de trabalho analíticos.
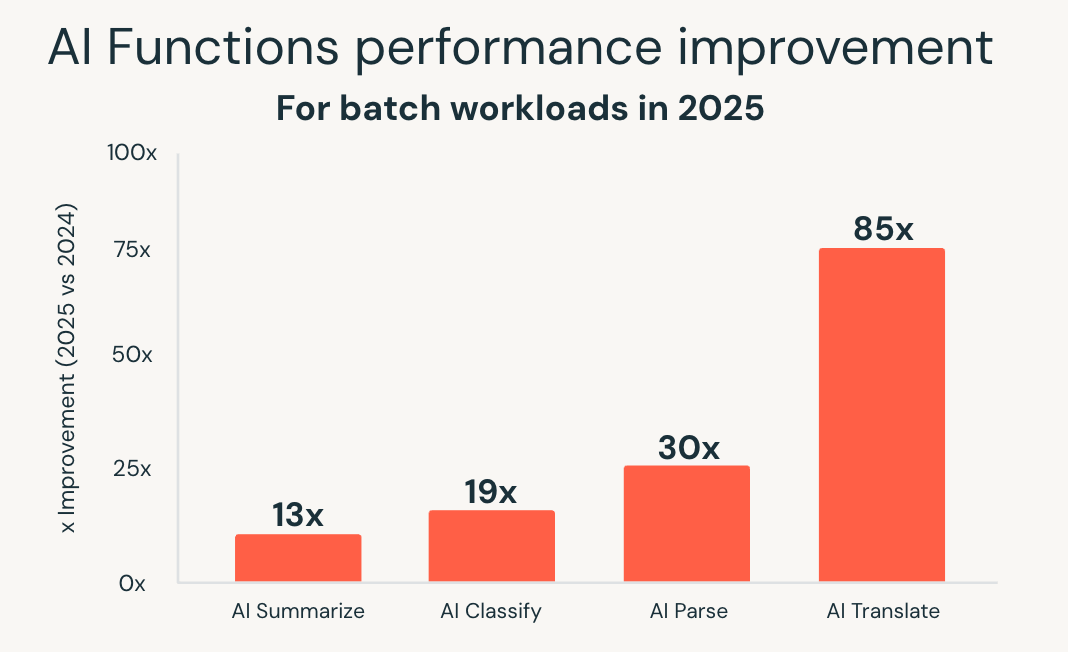
Essas melhorias permitem o processamento inteligente de documentos, a extração de insights de dados não estruturados e a análise preditiva usando interfaces SQL familiares. As cargas de trabalho de IA são escalonadas junto com as cargas de trabalho de análise, sem exigir sistemas separados ou pipelines personalizados.
Com o AI Capabilities, o Databricks SQL vai além da análise para cargas de trabalho alimentadas por IA, preservando ao mesmo tempo a simplicidade e as expectativas de desempenho do warehouse.
Começando
Todas essas melhorias já estão ativas no Databricks SQL Serverless, sem nada para habilitar e nenhuma configuração necessária.
Se você ainda não experimentou o DBSQL Serverless, crie um warehouse sem servidor e comece a consultar. As cargas de trabalho existentes são beneficiadas imediatamente, com melhorias de desempenho e custos aplicadas automaticamente à medida que a plataforma continua a evoluir.