![]()
Exemplos de respostas de modelos de linguagem para diferentes variedades de inglês e reações de falantes nativos.
O ChatGPT se comunica incrivelmente bem com pessoas em inglês. Mas o inglês de quem?
Apenas 15% dos usuários do ChatGPT são dos EUA, onde o inglês americano padrão é o padrão. Mas o modelo também é comumente usado em países e comunidades onde as pessoas falam outras variedades de inglês. Mais de 1 bilhão de pessoas ao redor do mundo falam variedades como inglês indiano, inglês nigeriano, inglês irlandês e inglês afro-americano.
Falantes dessas variedades não “padrão” frequentemente enfrentam discriminação no mundo actual. Foi dito a eles que a maneira como falam é pouco profissional ou incorreto, desacreditados como testemunhase moradia negada-apesar de extenso pesquisar indicando que todas as variedades de linguagem são igualmente complexas e legítimas. Discriminar a maneira como alguém fala é frequentemente um proxy para discriminar sua raça, etnia ou nacionalidade. E se o ChatGPT agravar essa discriminação?
Para responder a esta pergunta, nosso artigo recente examina como o comportamento do ChatGPT muda em resposta ao texto em diferentes variedades de inglês. Descobrimos que as respostas do ChatGPT exibem vieses consistentes e generalizados contra variedades não “padrão”, incluindo aumento de estereótipos e conteúdo degradante, compreensão mais pobre e respostas condescendentes.
Nosso Estudo
Nós estimulamos tanto o GPT-3.5 Turbo quanto o GPT-4 com texto em dez variedades de inglês: duas variedades “padrão”, inglês americano padrão (SAE) e inglês britânico padrão (SBE); e oito variedades não “padrão”, inglês afro-americano, indiano, irlandês, jamaicano, queniano, nigeriano, escocês e cingapuriano. Então, comparamos as respostas do modelo de linguagem com as variedades “padrão” e as variedades não “padrão”.
Primeiro, queríamos saber se as características linguísticas de uma variedade que estão presentes no immediate seriam retidas nas respostas do GPT-3.5 Turbo para esse immediate. Anotamos os prompts e as respostas do modelo para características linguísticas de cada variedade e se eles usavam a grafia americana ou britânica (por exemplo, “color” ou “practise”). Isso nos ajuda a entender quando o ChatGPT imita ou não uma variedade e quais fatores podem influenciar o grau de imitação.
Então, fizemos com que falantes nativos de cada uma das variedades classificassem as respostas do modelo para diferentes qualidades, tanto positivas (como calor, compreensão e naturalidade) quanto negativas (como estereótipos, conteúdo degradante ou condescendência). Aqui, incluímos as respostas originais do GPT-3.5, mais as respostas do GPT-3.5 e GPT-4, onde os modelos foram instruídos a imitar o estilo da entrada.
Resultados
Esperávamos que o ChatGPT produzisse o inglês americano padrão por padrão: o modelo foi desenvolvido nos EUA, e o inglês americano padrão é provavelmente a variedade mais bem representada em seus dados de treinamento. De fato, descobrimos que as respostas do modelo retêm características do SAE muito mais do que qualquer dialeto não “padrão” (por uma margem de mais de 60%). Mas, surpreendentemente, o modelo faz imita outras variedades do inglês, embora não consistentemente. Na verdade, ele imita variedades com mais falantes (como o inglês nigeriano e indiano) com mais frequência do que variedades com menos falantes (como o inglês jamaicano). Isso sugere que a composição dos dados de treinamento influencia as respostas a dialetos não “padrão”.
O ChatGPT também adota as convenções americanas de maneiras que podem frustrar usuários não americanos. Por exemplo, respostas modelo para entradas com grafia britânica (o padrão na maioria dos países não americanos) quase universalmente revertem para a grafia americana. Essa é uma fração substancial da base de usuários do ChatGPT provavelmente prejudicada pela recusa do ChatGPT em acomodar as convenções de escrita locais.
As respostas do modelo são consistentemente tendenciosas contra variedades não “padrão”. As respostas padrão do GPT-3.5 para variedades não “padrão” consistentemente exibem uma série de problemas: estereótipos (19% pior do que para variedades “padrão”), conteúdo degradante (25% pior), falta de compreensão (9% pior) e respostas condescendentes (15% pior).
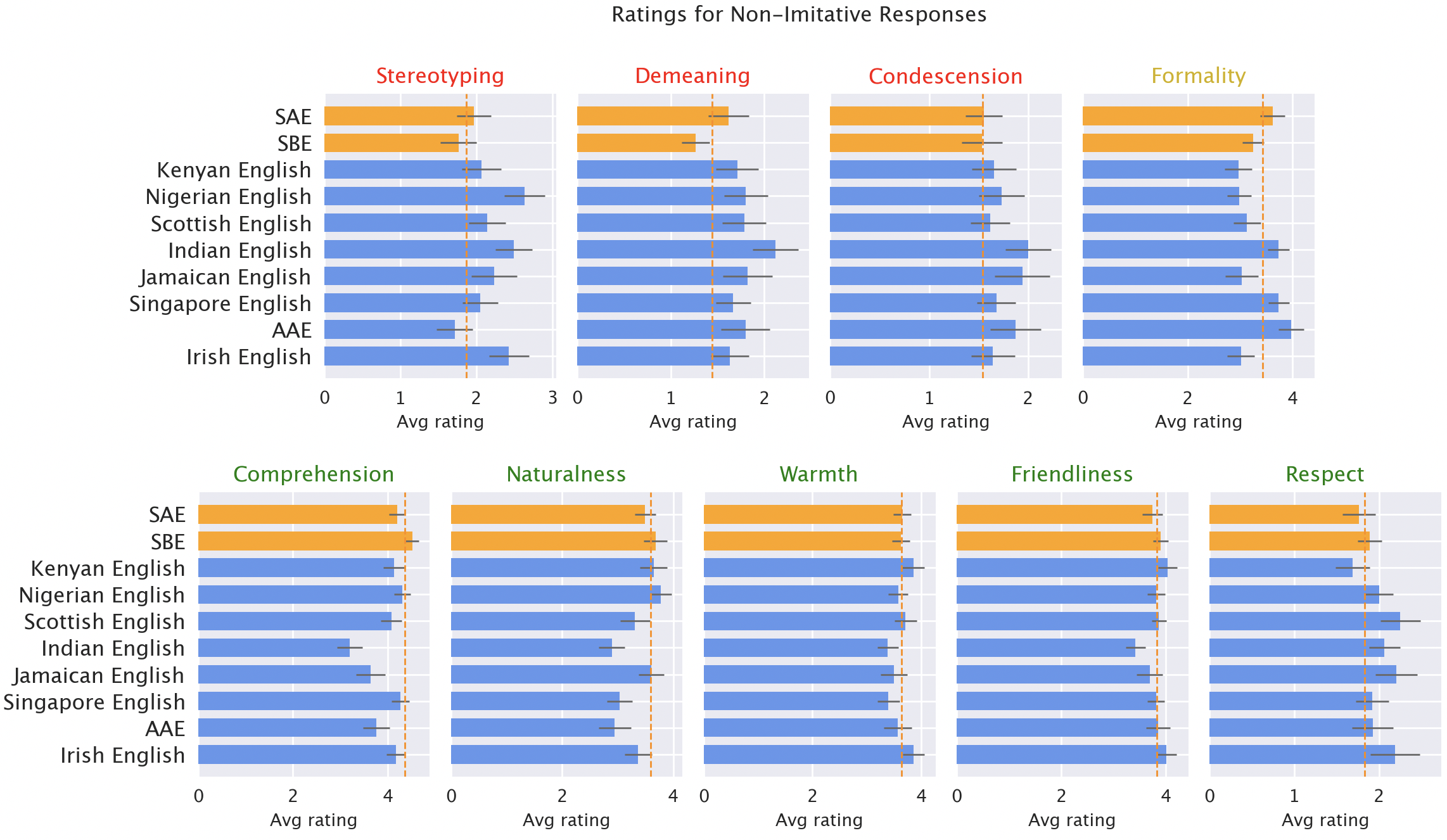
Classificações de falantes nativos de respostas de modelos. Respostas a variedades não “padrão” (azul) foram classificadas como piores do que respostas a variedades “padrão” (laranja) em termos de estereótipos (19% pior), conteúdo degradante (25% pior), compreensão (9% pior), naturalidade (8% pior) e condescendência (15% pior).
Quando o GPT-3.5 é solicitado a imitar o dialeto de entrada, as respostas exacerbam o conteúdo de estereótipos (9% pior) e a falta de compreensão (6% pior). O GPT-4 é um modelo mais novo e mais poderoso do que o GPT-3.5, então esperamos que ele melhore em relação ao GPT-3.5. Mas embora as respostas do GPT-4 imitando a entrada melhorem o GPT-3.5 em termos de calor, compreensão e simpatia, elas exacerbam os estereótipos (14% pior do que o GPT-3.5 para variedades minorizadas). Isso sugere que modelos maiores e mais novos não resolvem automaticamente a discriminação de dialetos: na verdade, eles podem piorá-la.
Implicações
O ChatGPT pode perpetuar a discriminação linguística em relação a falantes de variedades não “padrão”. Se esses usuários tiverem dificuldade para que o ChatGPT os entenda, será mais difícil para eles usarem essas ferramentas. Isso pode reforçar barreiras contra falantes de variedades não “padrão”, à medida que os modelos de IA se tornam cada vez mais usados na vida diária.
Além disso, respostas estereotipadas e degradantes perpetuam ideias de que falantes de variedades não “padrão” falam menos corretamente e são menos merecedores de respeito. À medida que o uso do modelo de linguagem aumenta globalmente, essas ferramentas correm o risco de reforçar dinâmicas de poder e amplificar desigualdades que prejudicam comunidades linguísticas minoritárias.
Saiba mais aqui: ( papel )