Google, eBay e outros têm a capacidade de encontrar imagens “semelhantes”. Você já se perguntou como isso funciona? Esse recurso transcende o que é possível com a pesquisa comum por palavra-chave e, em vez disso, usa a pesquisa semântica para retornar imagens semelhantes ou relacionadas. Este weblog abordará um breve histórico da pesquisa semântica, seu uso de vetores e como ela difere da pesquisa por palavras-chave.
Desenvolvendo compreensão com pesquisa semântica
A pesquisa de texto tradicional incorpora uma limitação basic: a correspondência exata. Tudo o que pode fazer é verificar, em escala, se uma consulta corresponde a algum texto. Mecanismos mais avançados contornam esse problema com truques adicionais, como lematização e lematização, por exemplo, correspondência equivalente de “enviar”, “enviado” ou “enviando”, mas quando uma consulta específica expressa um conceito com uma palavra diferente da do corpus (o conjunto de documentos a serem pesquisados), as consultas falham e os usuários ficam frustrados. Dito de outra forma, o motor de busca não tem entendimento do corpus.
Nossos cérebros simplesmente não funcionam como motores de busca. Pensamos em conceitos e ideias. Ao longo da vida, gradualmente montamos um modelo psychological do mundo, construindo ao mesmo tempo uma paisagem interna de pensamentos, fatos, noções, abstrações e uma teia de conexões entre eles. Como conceitos relacionados vivem “próximos” nesta paisagem, é fácil lembrar algo com uma palavra diferente, mas relacionada, que ainda mapeia o mesmo conceito.
Embora a investigação em inteligência synthetic proceed longe de replicar a inteligência humana, produziu conhecimentos úteis que tornam possível realizar pesquisas a um nível superior, ou semântico, combinando conceitos em vez de palavras-chave. Vetores e pesquisa vetorialestão no centro desta revolução.
De palavras-chave a vetores
Uma estrutura de dados típica para pesquisa de texto é um índice reverso, que funciona de forma muito semelhante ao índice no ultimate de um livro impresso. Para cada palavra-chave relevante, o índice mantém uma lista de ocorrências em determinados documentos do corpus; então, a resolução de uma consulta envolve a manipulação dessas listas para calcular uma lista classificada de documentos correspondentes.
Em contraste, a pesquisa vetorial usa uma forma radicalmente diferente de representar itens: vetores. Observe que a frase anterior mudou de falar sobre texto para um termo mais genérico, itens. Voltaremos a isso em breve.
O que é um vetor? Simplesmente uma lista ou array de números – pense em java.util.Vector, por exemplo – mas com ênfase em suas propriedades matemáticas. Entre as propriedades úteis dos vetores, também conhecidos como embeddings, está o fato de eles formarem um espaço onde itens semanticamente semelhantes estão próximos uns dos outros.

No espaço vetorial da Figura 1 acima, vemos que uma CPU e uma GPU são conceitualmente próximas. Uma batata frita é um parente distante. Um CPA, ou contador, embora lexicamente semelhante a uma CPU, é bem diferente.
A história completa dos vetores requer uma breve viagem por uma terra de redes neurais, incorporações e milhares de dimensões.
Redes Neurais e Incorporações
Abundam os artigos que descrevem a teoria e o funcionamento das redes neurais, que são vagamente modelado em como os neurônios biológicos se interconectam. Esta seção fornecerá uma rápida atualização. Esquematicamente, uma rede neural se parece com a Figura 2:
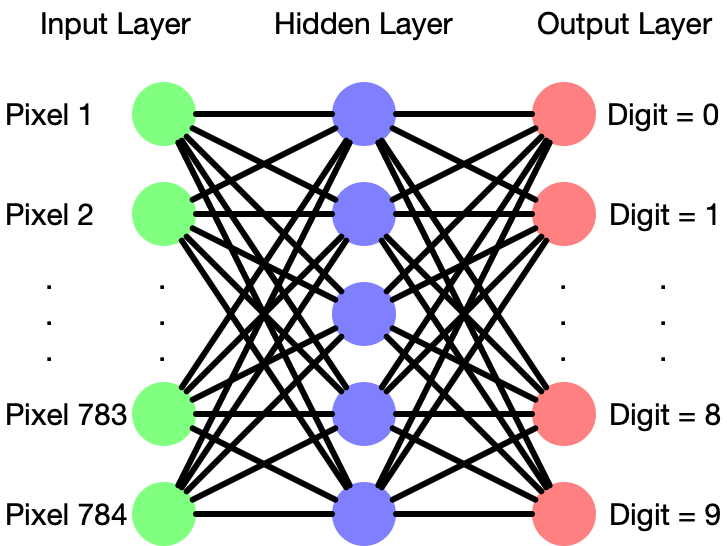
Uma rede neural consiste em camadas de ‘neurônios’, cada uma das quais aceita múltiplas entradas com pesos, aditivos ou multiplicativos, que combinam em um sinal de saída. A configuração das camadas em uma rede neural varia bastante entre as diferentes aplicações, e criar os “hiperparâmetros” certos para uma rede neural requer mão habilidosa.
Um rito de passagem para estudantes de aprendizado de máquina é construir uma rede neural para reconhecer dígitos manuscritos de um conjunto de dados chamado MNISTque rotulou imagens de dígitos manuscritos, cada um com 28×28 pixels. Neste caso, a camada mais à esquerda precisaria de 28×28=784 neurônios, um recebendo um sinal de brilho de cada pixel. Uma “camada oculta” intermediária possui uma densa rede de conexões com a primeira camada. Normalmente as redes neurais têm muitas camadas ocultas, mas aqui há apenas uma. No exemplo MNIST, a camada de saída teria 10 neurônios, representando o que a rede “vê”, ou seja, probabilidades de dígitos de 0 a 9.
Inicialmente, a rede é essencialmente aleatória. Treinar a rede envolve ajustar repetidamente os pesos para serem um pouco mais precisos. Por exemplo, uma imagem nítida de um “8” deve iluminar a saída #8 em 1,0, deixando as outras nove todas em 0. Se este não for o caso, isto é considerado um erro, que pode ser quantificado matematicamente. Com alguma matemática inteligente, é possível trabalhar de trás para frente a partir da saída, ajustando os pesos para reduzir o erro geral em um processo chamado retropropagação. Treinar uma rede neural é um problema de otimização, encontrar uma agulha adequada em um vasto palheiro.
Todas as entradas de pixels e saídas de dígitos têm um significado óbvio. Mas depois do treino, o que representam as camadas ocultas? Esta é uma boa pergunta!
No caso MNIST, para algumas redes treinadas, um determinado neurônio ou grupo de neurônios em uma camada oculta pode representar um conceito como talvez “a entrada contém um traço vertical” ou “a entrada contém um circuito fechado”. Sem qualquer orientação explícita, o processo de treinamento constrói um modelo otimizado do seu espaço de entrada. Extrair isso da rede produz uma incorporação.
Vetores de texto e muito mais
O que acontece se treinarmos uma rede neural em texto?
Um dos primeiros projetos a popularizar vetores de palavras é chamado word2vec. Ele treina uma rede neural com uma camada oculta de 100 a 1.000 neurônios, produzindo um incorporação de palavras.
Neste espaço de incorporação, as palavras relacionadas estão próximas umas das outras. Mas relações semânticas ainda mais ricas podem ser expressas como ainda mais vetores. Por exemplo, o vetor entre as palavras REI e PRÍNCIPE é quase igual ao vetor entre RAINHA e PRINCESA. A adição vetorial básica expressa aspectos semânticos da linguagem que não precisavam ser ensinados explicitamente.
Surpreendentemente, essas técnicas funcionam não apenas em palavras isoladas, mas também em frases ou até mesmo em parágrafos inteiros. Diferentes idiomas codificarão de forma que palavras comparáveis fiquem próximas umas das outras no espaço de incorporação.
Técnicas análogas funcionam em imagens, áudio, vídeo, dados analíticos e qualquer outra coisa em que uma rede neural possa ser treinada. Alguns embeddings “multimodais” permitem, por exemplo, que imagens e texto compartilhem o mesmo espaço de incorporação. A foto de um cachorro acabaria perto do texto “cachorro”. Isso parece mágico. As consultas podem ser mapeadas para o espaço de incorporação, e vetores próximos – sejam eles representativos de texto, dados ou qualquer outra coisa – serão mapeados para conteúdo relevante.
Alguns usos para pesquisa vetorial
Devido à sua ancestralidade compartilhada com LLMs e redes neurais, a pesquisa vetorial é um ajuste pure em aplicações generativas de IA, muitas vezes fornecendo recuperação externa para a IA. Alguns dos principais usos para esses tipos de casos de uso são:
- Adicionando ‘memória’ a um LLM além do tamanho limitado da janela de contexto
- Um chatbot que encontra rapidamente as seções mais relevantes de documentos em sua rede corporativa e as transfere para um LLM para resumo ou como resposta a perguntas e respostas. (Isso é chamado de geração aumentada de recuperação)
Além disso, a pesquisa vetorial funciona muito bem em áreas onde a experiência de pesquisa precisa estar mais próxima de como pensamos, especialmente para agrupar itens semelhantes, como:
- Pesquise documentos em vários idiomas
- Encontrar imagens visualmente semelhantes ou imagens semelhantes a vídeos.
- Detecção de fraude ou anomalia, por exemplo, se uma determinada transação/documento/e-mail produz uma incorporação que está mais distante de um cluster de exemplos mais típicos.
- Aplicativos de pesquisa híbrida, usando tecnologia de mecanismo de pesquisa tradicional e pesquisa vetorial para combinar os pontos fortes de cada um.
Enquanto isso, a pesquisa tradicional baseada em palavras-chave ainda tem seus pontos fortes e continua útil para muitos aplicativos, especialmente quando o usuário sabe exatamente o que está procurando, incluindo dados estruturados, análise linguística, descoberta jurídica e pesquisa facetada ou paramétrica.
Mas esta é apenas uma pequena amostra do que é possível. A popularidade da pesquisa vetorial está crescendo e potencializando cada vez mais aplicações. Como seu próximo projeto usará a pesquisa vetorial?
Proceed seu aprendizado com a parte 2 de nossa Introdução à Pesquisa Semântica: –Incorporações, métricas de similaridade e bancos de dados vetoriais.
Saiba como o Rockset oferece suporte à pesquisa vetorial aqui.