Tinta clínica é um conjunto de software program utilizado em mais de mil ensaios clínicos para agilizar o processo de coleta e gerenciamento de dados, com o objetivo de melhorar a eficiência e a precisão dos ensaios. Seu sistema eletrônico de captura de dados baseado em nuvem permite que dados de ensaios clínicos de mais de 2 milhões de pacientes em 110 países sejam coletados eletronicamente em tempo actual a partir de uma variedade de fontes, incluindo registros eletrônicos de saúde e dispositivos vestíveis.
Com a pandemia da COVID-19 forçando muitos ensaios clínicos a se tornarem virtuais, a Scientific ink tem sido uma solução cada vez mais valiosa por sua capacidade de oferecer suporte ao monitoramento remoto e aos ensaios clínicos virtuais. Em vez de exigir que os participantes do estudo compareçam ao native para relatar os resultados dos pacientes, eles podem transferir o monitoramento para casa. Como resultado, os ensaios levam menos tempo para serem concebidos, desenvolvidos e implementados e a inscrição e retenção de pacientes aumenta.
Para analisar eficazmente os dados dos ensaios clínicos no novo ambiente remoto, os patrocinadores dos ensaios clínicos recorreram à Scientific ink com a necessidade de uma visão de 360 graus em tempo actual dos pacientes e dos seus resultados em todo o estudo world. Com um painel de análise centralizado em tempo actual equipado com recursos de filtro, as equipes clínicas podem tomar medidas imediatas em relação às dúvidas e avaliações dos pacientes para garantir o sucesso do estudo. A visão de 360 graus foi projetada para ser o epicentro de dados para equipes clínicas, fornecendo uma visão panorâmica e recursos robustos de detalhamento para que as equipes clínicas pudessem manter os testes sob controle em todas as regiões geográficas.
Quando os requisitos para o novo monitoramento dos participantes do estudo em tempo actual chegaram à equipe de engenharia, eu sabia que a pilha técnica atual não poderia suportar análises complexas com latência de milissegundos em dados em tempo actual. Amazon OpenSearch, um fork do Elasticsearch usado para nossa pesquisa de aplicativos, foi rápido, mas não foi desenvolvido especificamente para análises complexas, incluindo junta-se. Floco de neveo robusto knowledge warehouse em nuvem usado por nossa equipe de analistas para cargas de trabalho de enterprise intelligence de alto desempenho, sofreu atrasos significativos nos dados e não conseguiu atender aos requisitos de desempenho do aplicativo. Isso nos levou à prancheta para criar uma nova arquitetura; aquele que suporta ingestão em tempo actual e análises complexas, ao mesmo tempo que é resiliente.
A Arquitetura Antes

Amazon DynamoDB para cargas de trabalho operacionais
Na plataforma Scientific ink, dados de fornecedores terceirizados, aplicativos da internet, dispositivos móveis e dados de dispositivos vestíveis são armazenados em Amazon DynamoDB. O esquema flexível do Amazon DynamoDB facilita o armazenamento e a recuperação de dados em vários formatos, o que é particularmente útil para aplicações da Scientific ink que exigem o tratamento de dados dinâmicos e semiestruturados. DynamoDB é um banco de dados sem servidor, portanto a equipe não precisou se preocupar com a infraestrutura subjacente ou com o dimensionamento do banco de dados, pois todos são gerenciados pela AWS.
Amazon Opensearch para cargas de trabalho de pesquisa
Embora o DynamoDB seja uma ótima opção para cargas de trabalho transacionais rápidas, escalonáveis e altamente disponíveis, ele não é a melhor opção para casos de uso de pesquisa e análise. Na plataforma Scientific ink de primeira geração, a pesquisa e a análise foram transferidas do DynamoDB para o Amazon OpenSearch. À medida que a quantidade e a variedade de dados aumentavam, percebemos a necessidade de junções para dar suporte a análises mais avançadas e fornecer monitoramento dos pacientes do estudo em tempo actual. As junções não são um cidadão de primeira classe no OpenSearch, exigindo uma série de soluções alternativas operacionalmente complexas e caras, incluindo desnormalização de dados, relacionamentos pai-filho, objetos aninhados e junções no lado do aplicativo que são difíceis de escalar.
Também encontramos desafios operacionais de dados e infraestrutura quando dimensionando o OpenSearch. Um desafio de dados que enfrentamos centrou-se no mapeamento dinâmico no OpenSearch ou no processo de detecção e mapeamento automático dos tipos de dados dos campos em um documento. O mapeamento dinâmico foi útil porque tínhamos um grande número de campos com tipos de dados variados e indexávamos dados de várias fontes com esquemas diferentes. No entanto, o mapeamento dinâmico às vezes levava a resultados inesperados, como tipos de dados incorretos ou conflitos de mapeamento que nos obrigavam a reindexar os dados.
Do lado da infraestrutura, embora utilizássemos o Amazon Opensearch gerenciado, ainda éramos responsáveis por operações de cluster incluindo gerenciamento de nós, fragmentos e índices. Descobrimos que à medida que o tamanho dos documentos aumentava, precisávamos ampliar o cluster, o que é um processo guide e demorado. Além disso, como o OpenSearch tem uma arquitetura fortemente acoplada com escalabilidade de computação e armazenamento em conjunto, tivemos que provisionar recursos de computação em excesso para suportar o número crescente de documentos. Isso levou ao desperdício de computação, a custos mais elevados e à redução da eficiência. Mesmo se pudéssemos ter feito análises complexas funcionarem no OpenSearch, teríamos avaliado bancos de dados adicionais, pois a engenharia de dados e o gerenciamento operacional eram significativos.
Snowflake para cargas de trabalho de armazenamento de dados
Também investigamos o potencial de nosso knowledge warehouse em nuvem, Snowflake, para ser a camada de serviço para análises em nosso aplicativo. O Snowflake foi usado para fornecer relatórios consolidados semanais aos patrocinadores de ensaios clínicos e deu suporte à análise SQL, atendendo aos complexos requisitos analíticos do aplicativo. Dito isso, o descarregamento dos dados do DynamoDB para o Snowflake demorou muito; no mínimo, poderíamos atingir uma latência de dados de 20 minutos, fora da janela de tempo necessária para este caso de uso.
Requisitos
Dadas as lacunas na arquitetura atual, criamos os seguintes requisitos para a substituição do OpenSearch como camada de serviço:
- Ingestão de streaming em tempo actual: as alterações de dados do DynamoDB precisam estar visíveis e consultáveis no banco de dados downstream em segundos
- Análise complexa com latência de milissegundos (incluindo junções): o banco de dados deve ser capaz de consolidar dados de testes globais de pacientes em uma visão de 360 graus. Isto inclui o suporte à classificação e filtragem complexas de dados e agregações de milhares de entidades diferentes.
- Altamente Resiliente: O banco de dados foi projetado para manter a disponibilidade e minimizar a perda de dados diante de vários tipos de falhas e interrupções.
- Escalável: o banco de dados é nativo da nuvem e pode ser dimensionado com o clique de um botão ou uma chamada de API, sem tempo de inatividade. Havíamos investido em uma arquitetura sem servidor com o Amazon DynamoDB e não queríamos que a equipe de engenharia gerenciasse as operações em nível de cluster no futuro.
O Depois da Arquitetura
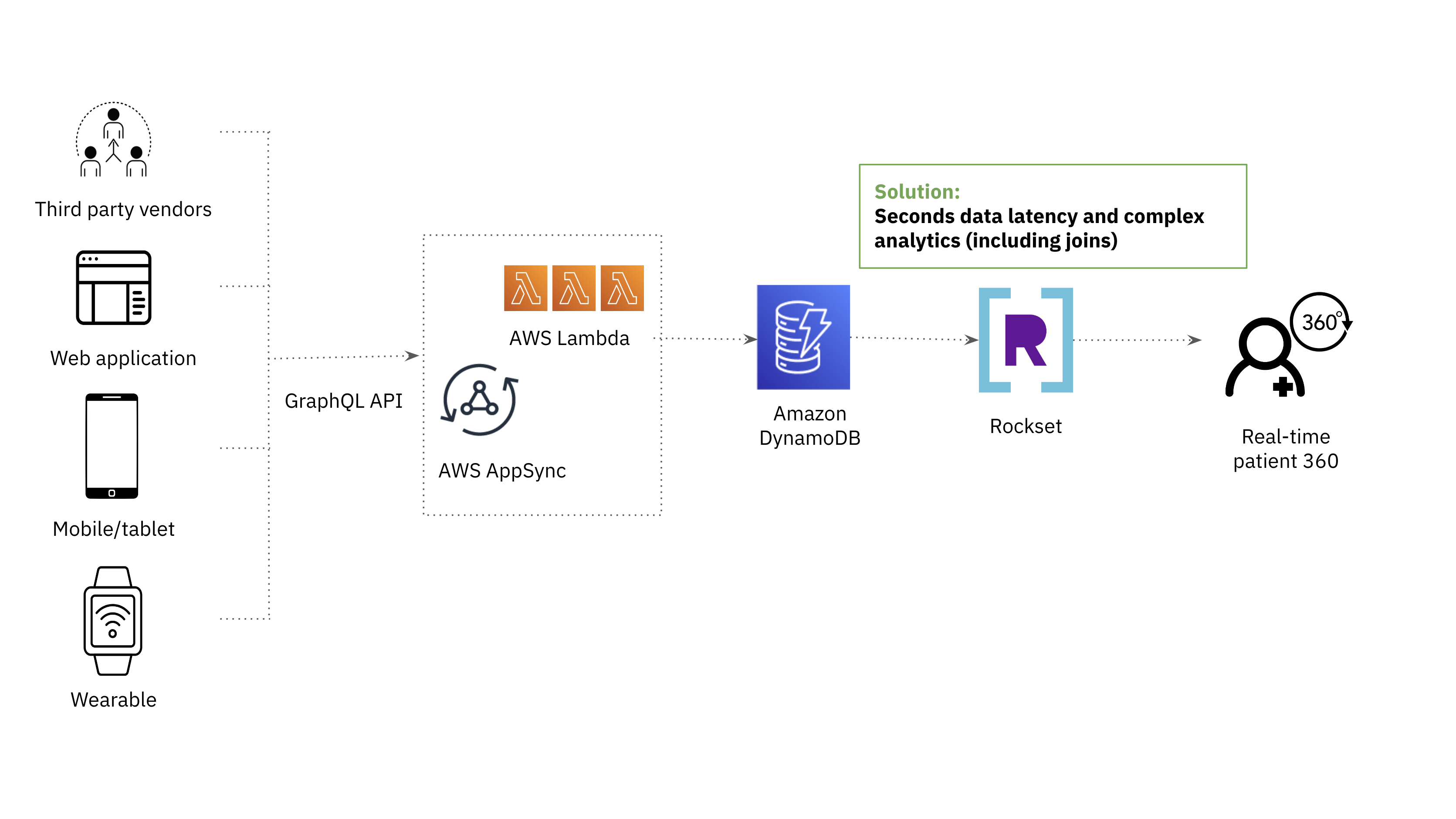
O Rockset apareceu originalmente em nosso radar como um substituto do OpenSearch por seu suporte a análises complexas em dados de baixa latência.
Tanto o OpenSearch quanto o Rockset usam indexação para permitir consultas rápidas em grandes quantidades de dados. A diferença é que a Rockset emprega um Índice Convergente que é uma combinação de um índice de pesquisa, armazenamento colunar e armazenamento de linhas para desempenho best de consulta. O Índice Convergente oferece suporte a uma linguagem de consulta baseada em SQL, o que nos permite atender aos requisitos de análises complexas.
Além da Indexação Convergente, houve outros recursos que despertaram nosso interesse e facilitaram o início dos testes de desempenho do Rockset em nossos próprios dados e consultas.
- Conector integrado para DynamoDB: novos dados de nossas tabelas DynamoDB são refletidos e tornados consultáveis no Rockset com apenas alguns segundos de atraso. Isso facilitou o encaixe do Rockset em nossa pilha de dados existente.
- Capacidade de colocar vários tipos de dados no mesmo campo: isso resolveu os desafios de engenharia de dados que enfrentamos com o mapeamento dinâmico no OpenSearch, garantindo que não houvesse falhas em nosso processo de ETL e que as consultas continuassem a fornecer respostas mesmo quando houvesse alterações de esquema.
- Arquitetura nativa da nuvem: Também investimos em uma pilha de dados sem servidor para eficiência de recursos e redução da sobrecarga operacional. Conseguimos escalar a computação de ingestão, a computação de consulta e o armazenamento de forma independente com o Rockset para que não precisemos mais provisionar recursos em excesso.
Resultados de desempenho
Depois de determinarmos que o Rockset atendia às necessidades de nosso aplicativo, procedemos à avaliação da ingestão do banco de dados e do desempenho da consulta. Executamos os seguintes testes no Rockset construindo uma função Lambda com Node.js:
Desempenho de ingestão
O padrão comum que vemos são muitas gravações pequenas, variando em tamanho de 400 bytes a 2 kilobytes, agrupadas e gravadas no banco de dados com frequência. Avaliamos o desempenho de ingestão gerando gravações X no DynamoDB em rápida sucessão e registrando o tempo médio em milissegundos que o Rockset levou para sincronizar esses dados e torná-los consultáveis, também conhecido como latência de dados.
Para executar este teste de desempenho, usamos uma instância digital média Rockset com 8 vCPU de computação e 64 GiB de memória.
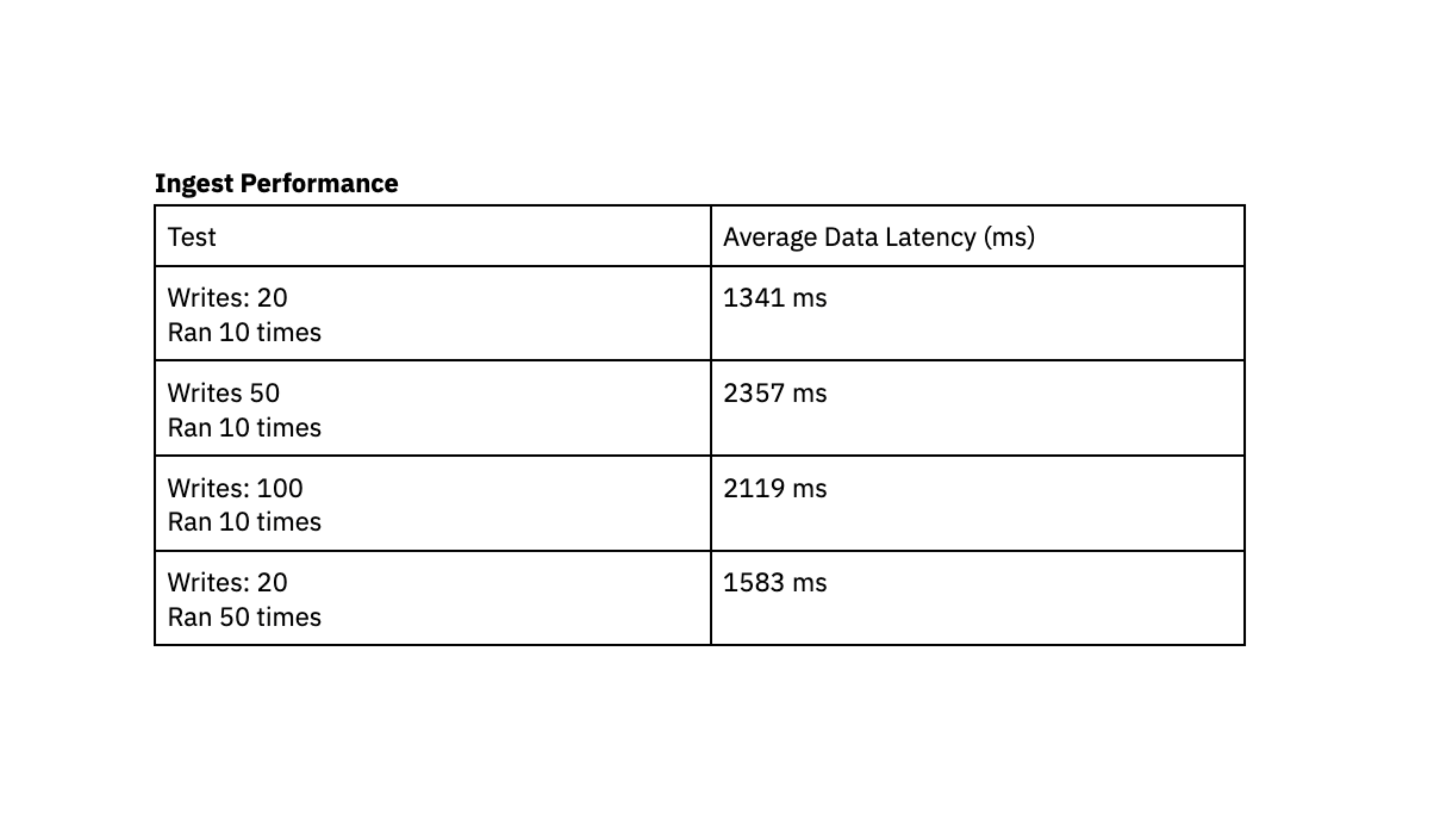
Os testes de desempenho indicam que o Rockset é capaz de atingir um latência de dados inferior a 2,4 segundosque representa o tempo entre a geração dos dados no DynamoDB e sua disponibilidade para consulta no Rockset. Esse teste de carga nos deixou confiantes de que poderíamos acessar os dados de forma consistente aproximadamente 2 segundos após gravar no DynamoDB, fornecendo aos usuários dados atualizados em seus painéis. No passado, lutamos para alcançar uma latência previsível com o Elasticsearch e ficamos entusiasmados com a consistência que vimos com o Rockset durante os testes de carga.
Desempenho de consulta
Para desempenho de consulta, executamos consultas X aleatoriamente a cada 10-60 milissegundos. Executamos dois testes usando consultas com diferentes níveis de complexidade:
- Consulta 1: Consulta simples em alguns campos de dados. Tamanho do conjunto de dados de aproximadamente 700 mil registros e 2,5 GB.
- Consulta 2: consulta complexa que expande arrays em várias linhas usando uma função unnest. Os dados são filtrados nos campos não aninhados. Dois conjuntos de dados foram unidos: um conjunto de dados tinha 700 mil linhas e 2,5 GB, o outro conjunto de dados tinha 650 mil linhas e 3 GB.
Executamos novamente os testes em uma instância digital média Rockset com 8 vCPU de computação e 64 GiB de memória.
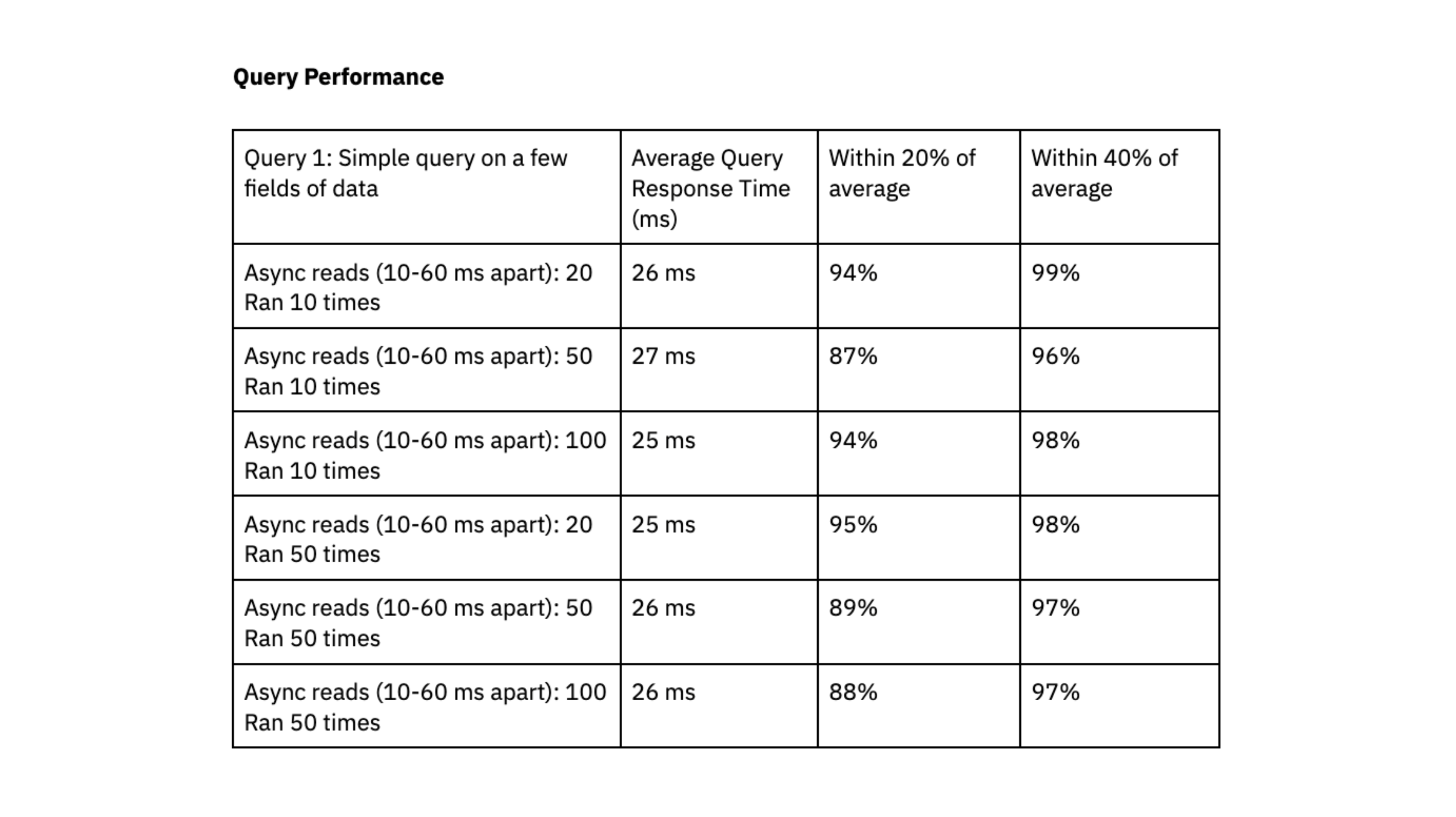
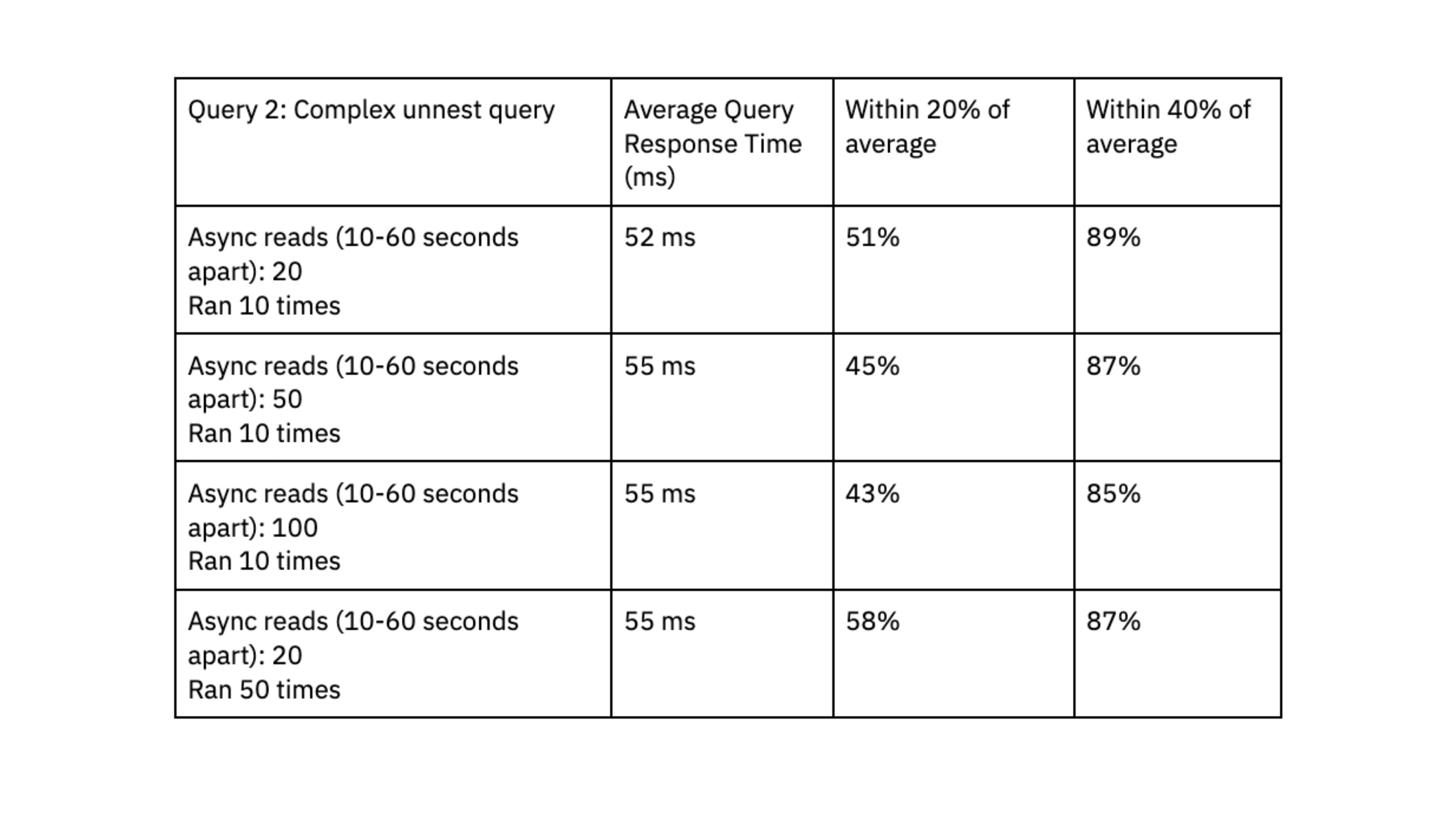
A Rockset foi capaz de fornecer tempos de resposta de consulta na faixa de milissegundos de dois dígitosmesmo ao lidar com cargas de trabalho com altos níveis de simultaneidade.
Para determinar se o Rockset pode escalar linearmente, avaliamos o desempenho da consulta em uma instância digital pequena, que tinha 4vCPU de computação e 32 GiB de memória, em comparação com a instância digital média. Os resultados mostraram que a instância digital média reduziu a latência da consulta em um fator de 1,6x para a primeira consulta e 4,5x para a segunda consulta, sugerindo que o Rockset pode escalar com eficiência para nossa carga de trabalho.
Gostamos que o Rockset tenha alcançado um desempenho de consulta previsível, agrupado entre 40% e 20% da média, e que as consultas sejam entregues consistentemente em milissegundos de dois dígitos; esse tempo rápido de resposta à consulta é essencial para a experiência do usuário.
Conclusão
Atualmente, estamos colocando o monitoramento de ensaios clínicos em tempo actual em produção como o novo centro de dados operacionais para equipes clínicas. Ficamos impressionados com a velocidade do Rockset e sua capacidade de suportar filtros, junções e agregações complexas. O Rockset atinge consultas de latência de dois dígitos em milissegundos e pode dimensionar a ingestão para oferecer suporte a atualizações, inserções e exclusões em tempo actual do DynamoDB.
Ao contrário do OpenSearch, que exigia intervenções manuais para atingir o desempenho best, o Rockset provou exigir um esforço operacional mínimo da nossa parte. A ampliação de nossas operações para acomodar instâncias virtuais maiores e mais patrocinadores clínicos acontece com apenas um simples apertar de botão.
Durante o próximo ano, estamos entusiasmados em implementar o monitoramento em tempo actual dos participantes do estudo para todos os clientes e continuar nossa liderança na transformação digital de ensaios clínicos.