Uma das primeiras perguntas que as organizações precisam responder ao adotar a malha de dados é: “Quais produtos de dados devemos construir primeiro e como podemos identificá-los?” Perguntas como “Quais são os limites do produto de dados?”, “Qual deve ser grande ou pequeno?” e “A que domínio eles pertencem?” surgem frequentemente. Vimos muitas organizações ficarem presas nesta fase, engajando-se em elaborados exercícios de design que duram meses e envolvem reuniões intermináveis.
Temos praticado uma abordagem metódica para responder rapidamente a essas importantes questões de design, oferecendo detalhes suficientes para que as partes interessadas mais amplas se alinhem com as metas e entendam o resultado de alto nível esperado, ao mesmo tempo em que concedemos às equipes de produtos de dados a autonomia para elaborar os detalhes de implementação e entre em ação.
O que são produtos de dados?
Antes de começarmos a projetar produtos de dados, vamos primeiro estabelecer um entendimento compartilhado do que eles são e do que não são.
Produtos de dados são os blocos de construção de uma malha de dados, servem dados analíticos e devem exibir a
oito características descrito por Zhamak em seu livro
Malha de dados: entregando valor baseado em dados em escala.
Detectável
Os consumidores de dados devem poder explorar facilmente os produtos de dados disponíveis, localizar aqueles de que precisam e determinar se são adequados ao seu caso de uso.
Endereçável
Um produto de dados deve oferecer um endereço único e permanente (por exemplo, URL, URI) que permita seu acesso de forma programática ou handbook.
Compreensível (autodescritível)
Os consumidores de dados devem ser capazes de compreender facilmente a finalidade e os padrões de utilização do produto de dados, analisando a sua documentação, que deve incluir detalhes como a sua finalidade, descrições a nível de campo, métodos de acesso e, se aplicável, um conjunto de dados de amostra.
Confiável
Um produto de dados deve comunicar de forma transparente seus objetivos de nível de serviço (SLOs) e adesão a eles (SLIs), garantindo que os consumidores possam confiar nele o suficiente para construir seus casos de uso com segurança.
Nativamente acessível
Um produto de dados deve atender às diferentes personas de seus usuários por meio de seus modos de acesso preferidos. Por exemplo, pode fornecer um relatório predefinido para gerentes, uma conexão fácil baseada em SQL para ambientes de trabalho de ciência de dados e uma API para acesso programático por outros serviços de back-end.
Interoperável (combinável)
Um produto de dados deve ser perfeitamente combinável com outros produtos de dados, permitindo fácil vinculação, como junção, filtragem e agregação, independentemente da equipe ou do domínio que o criou. Isso requer suporte a chaves comerciais padrão e padrões de acesso padrão.
Valioso por si só
Um produto de dados deve representar um conceito de informação coeso dentro do seu domínio e fornecer valor de forma independente, sem precisar de junções com outros produtos de dados para ser útil.
Seguro
Um produto de dados deve implementar controles de acesso robustos para garantir que apenas usuários ou sistemas autorizados tenham acesso, seja programático ou handbook. A criptografia deve ser empregada quando apropriado, e todos os regulamentos relevantes específicos do domínio devem ser rigorosamente seguidos.
Simplificando, é uma forma independente, implantável e valiosa de trabalhar com dados. O conceito aplica a mentalidade e metodologias comprovadas de desenvolvimento de produtos de software program ao espaço de dados.
Pacote de produtos de dados com dados analíticos estruturados, semiestruturados ou não estruturados para consumo eficaz e tomada de decisões orientada por dados, tendo em mente grupos de usuários específicos e seu padrão de consumo para esses dados analíticos
No desenvolvimento de software program moderno, decompomos os sistemas de software program em unidades facilmente combináveis, garantindo que sejam detectáveis, possam ser mantidos e tenham objetivos de nível de serviço (SLOs) comprometidos. Da mesma forma, um produto de dados é a menor unidade valiosa de dados analíticos, proveniente de fluxos de dados, sistemas operacionais ou outras fontes externas e também de outros produtos de dados, empacotados especificamente de forma a fornecer valor comercial significativo. Inclui todo o maquinário necessário para atingir com eficiência o objetivo declarado por meio da automação.
Os produtos de dados empacotam dados analíticos estruturados, semiestruturados ou não estruturados para consumo eficaz e tomada de decisões orientada por dados, tendo em mente grupos de usuários específicos e seu padrão de consumo para esses dados analíticos.
O que eles não são
Acredito que uma boa definição não apenas especifica o que algo é, mas também esclarece o que não é.
Como os produtos de dados são os blocos de construção fundamentais da sua malha de dados, uma definição mais restrita e específica os torna mais valiosos para a sua organização. Um escopo bem definido simplifica a criação de projetos reutilizáveis e facilita o desenvolvimento de “caminhos pavimentados” para construir e gerenciar produtos de dados com eficiência.
Confundir produtos de dados com muitos conceitos diferentes não apenas cria confusão entre as equipes, mas também torna significativamente mais difícil o desenvolvimento de projetos reutilizáveis.
Com produtos de dados, aplicamos muitas práticas eficazes de engenharia de software program a dados analíticos para resolver problemas comuns de propriedade e qualidade. Essas questões, no entanto, não estão limitadas aos dados analíticos – elas existem em toda a engenharia de software program. Freqüentemente, há uma tendência de resolver todos os problemas de propriedade e qualidade na empresa aproveitando a malha de dados e os produtos de dados. Embora as intenções sejam boas, descobrimos que esta abordagem pode minar esforços mais amplos de transformação da malha de dados, diluindo a linguagem e o foco.
Um dos mal-entendidos mais comuns é confundir produtos de dados com aplicativos baseados em dados. Os produtos de dados são projetados nativamente para acesso programático e capacidade de composição, enquanto os aplicativos orientados a dados são destinados principalmente à interação humana e não são inerentemente combináveis.
Aqui estão algumas deturpações comuns que observei e o raciocínio por trás disso:
| Nome | Razões | Característica ausente |
|---|---|---|
| Armazém de dados | Grande demais para ser uma unidade combinável independente. |
|
| Relatório em PDF | Não destinado ao acesso programático. |
|
| Painel | Não destinado ao acesso programático. Embora um produto de dados possa ter um painel como uma de suas saídas ou painéis possam ser criados consumindo um ou mais produtos de dados, um painel por si só não se qualifica como um produto de dados. |
|
| Mesa em um armazém | Sem metadados ou documentação adequados não é um produto de dados. |
|
| Tópico Kafka | Normalmente, eles não se destinam a análises. Isso se reflete em sua estrutura de armazenamento: o Kafka armazena dados como uma sequência de mensagens em tópicos, diferentemente do armazenamento baseado em colunas comumente usado na análise de dados para filtragem e agregação eficientes. Eles podem servir como fontes ou portas de entrada para produtos de dados. |
Trabalhando de trás para frente a partir de um caso de uso
Trabalhar de trás para frente a partir do objetivo closing é um princípio basic do desenvolvimento de software program e descobrimos que ele também é altamente eficaz na modelagem de produtos de dados. Esta abordagem obriga-nos a concentrar-nos nos utilizadores finais e nos sistemas, considerando como eles preferem consumir produtos de dados (através de portas de saída acessíveis nativamente). Ele fornece à equipe do produto de dados um objetivo claro pelo qual trabalhar, ao mesmo tempo que introduz restrições que evitam o design excessivo e minimizam o desperdício de tempo e esforço.
Pode parecer um detalhe menor, mas não podemos enfatizar o suficiente: há uma tendência comum de começar com as fontes de dados e definir os produtos de dados. Sem as restrições de um caso de uso tangível, você não saberá quando seu design é bom o suficiente para avançar com a implementação, o que muitas vezes leva à paralisia da análise e a muito esforço desperdiçado.
Como fazer isso?
A configuração
Este processo normalmente é conduzido através de uma série de oficinas curtas. Os participantes devem incluir usuários potenciais do produto de dados, especialistas no domínio e a equipe responsável por construí-lo e mantê-lo. Uma ferramenta de quadro branco e um facilitador dedicado são essenciais para garantir um fluxo de trabalho tranquilo.
O processo
Vejamos um caso de uso comum que encontramos no varejo de moda.
Caso de uso:
Como gerente de relacionamento com o cliente, preciso de relatórios oportunos que forneçam insights sobre nossos clientes mais e menos valiosos. Isso me ajudará a tomar medidas para reter clientes de alto valor e melhorar a experiência de clientes de baixo valor.
Para abordar esse caso de uso, vamos definir um produto de dados chamado
“Valor vitalício do cliente” (CLV). Este produto atribuirá a cada cliente registrado uma pontuação que representa seu valor para o negócio, juntamente com recomendações para a próxima melhor ação que um gerente de relacionamento com o cliente pode realizar com base na pontuação prevista.

Figura 1: A equipe de relacionamento com o cliente usa o produto de dados Buyer Lifetime Worth por meio de um relatório semanal para orientar suas estratégias de engajamento com clientes de alto valor.
Trabalhando de trás para frente a partir do CLV, devemos considerar quais produtos de dados adicionais são necessários para calculá-lo. Isso incluiria um perfil básico do cliente (nome, idade, e-mail, and so forth.) e seu histórico de compras.
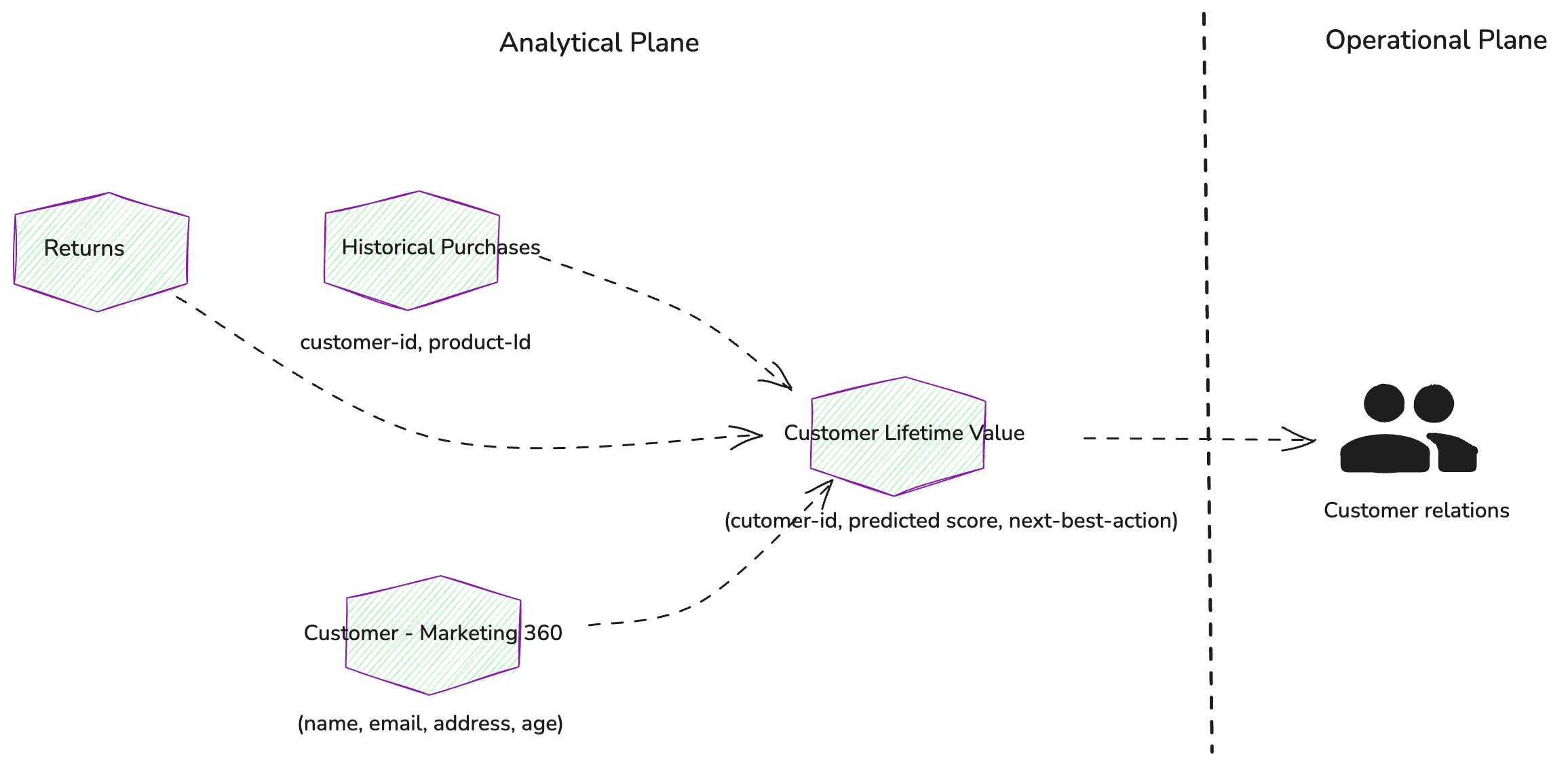
Figura 2: Produtos de dados de origem adicionais são necessários para calcular os valores de vida útil do cliente
Se você achar difícil descrever um produto de dados em uma ou duas frases simples, é provável que ele não esteja bem definido
A questão-chave que precisamos de colocar, onde a especialização no domínio é essential, é se cada produto de dados proposto representa um conceito de informação coeso. Eles são valiosos por si só? Um teste útil é definir uma descrição de trabalho para cada produto de dados. Se você achar difícil fazer isso de forma concisa em uma ou duas frases simples, ou se a descrição for muito longa, provavelmente não é um produto de dados bem definido.
Vamos aplicar este teste aos produtos de dados acima
Valor de vida do cliente (CLV):
Fornece um valor previsto da vida útil do cliente como uma pontuação, juntamente com uma sugestão de próxima melhor ação para os representantes do cliente.
Advertising and marketing de cliente 360:
Oferece uma visão abrangente do cliente do ponto de vista do advertising and marketing.
Compras históricas:
Fornece uma lista de compras históricas (SKUs) para cada cliente.
Retorna:
Lista de devoluções iniciadas pelo cliente.
Trabalhando de trás para frente a partir do “Cliente – Advertising and marketing 360”,
“Compras históricas”e “Retornos” produtos de dados, devemos identificar o sistema de registros para esses dados. Isto nos levará aos sistemas transacionais relevantes com os quais precisamos nos integrar para ingerir os dados necessários.
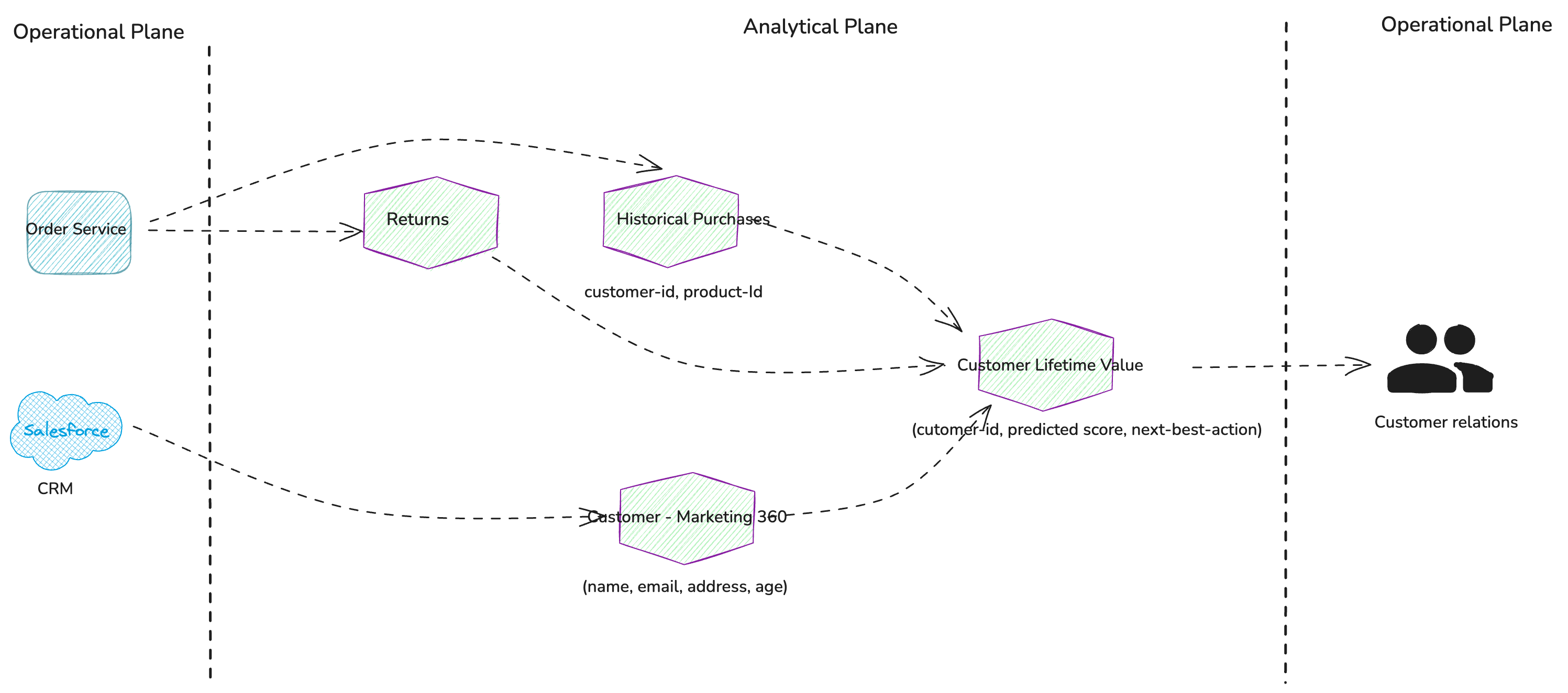
Figura 3: Sistema de registros ou sistemas transacionais que expõem produtos de dados de origem