
Bem-vindo à primeira parte de uma série de postagens discutindo o recentemente anunciado Serviço de inferência Cloudera AI.
Hoje, a Inteligência Synthetic (IA) e o Aprendizado de Máquina (ML) são mais cruciais do que nunca para que as organizações transformem os dados em uma vantagem competitiva. No entanto, para desbloquear todo o potencial da IA, as empresas precisam de implementar modelos e aplicações de IA em escala, em tempo actual e com baixa latência e elevado rendimento. É aqui que entra o serviço Cloudera AI Inference. É um ambiente de implantação poderoso que permite integrar e implantar IA generativa (GenAI) e modelos preditivos em seus ambientes de produção, incorporando segurança, privacidade e governança de dados de nível empresarial da Cloudera.
Nas próximas semanas, exploraremos detalhadamente o serviço Cloudera AI Inference, fornecendo uma introdução abrangente aos seus recursos, benefícios e casos de uso.
Nesta série, nos aprofundaremos em tópicos como:
- Um mergulho profundo na arquitetura do serviço Cloudera AI Inference
- Principais recursos e benefícios do serviço e como ele complementa o Cloudera AI Workbench
- Configuração de serviços e dimensionamento de implantações de modelos com base nas cargas de trabalho projetadas
- Como implementar um sistema Retrieval-Augmented Technology (RAG) usando o serviço
- Explorando diferentes casos de uso para os quais o serviço é uma ótima escolha
Se você estiver interessado em liberar todo o potencial da IA e do ML em sua organização, fique atento às nossas próximas postagens, onde nos aprofundaremos no mundo da Cloudera AI Inference.
O que é o serviço Cloudera AI Inference?
O serviço Cloudera AI Inference é um ambiente de implantação altamente escalável, seguro e de alto desempenho para atender produção Modelos de IA e aplicações relacionadas. O serviço é direcionado ao público serviço de produção ultimate do pipeline MLOPs/LLMOPs, conforme mostrado no diagrama a seguir:
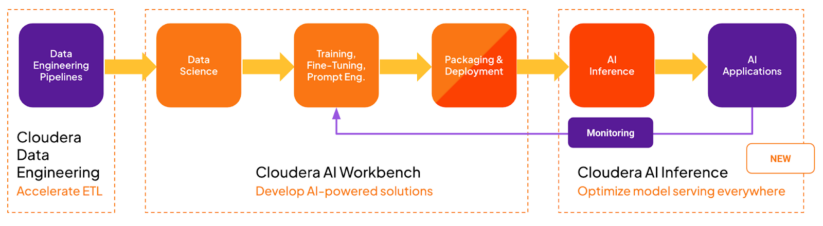
Ele complementa o Cloudera AI Workbench (anteriormente conhecido como Cloudera Machine Studying Workspace), um ambiente de implantação mais focado nas fases de exploração, desenvolvimento e teste do fluxo de trabalho de MLOPs.
Por que o construímos?
O surgimento do GenAI, desencadeado pelo lançamento do ChatGPT, facilitou a ampla disponibilidade de grandes modelos de linguagem (LLMs) de código aberto e de alta qualidade. Serviços como Abraçando o rosto e o Zoológico modelo ONNX facilitou o acesso a uma ampla variedade de modelos pré-treinados. Esta disponibilidade destaca a necessidade de um serviço robusto que permita aos clientes integrar e implementar perfeitamente modelos pré-treinados de diversas fontes em ambientes de produção. Para atender às necessidades de nossos clientes, o serviço deve ser altamente:
- Seguro – autenticação e autorização fortes, privadas e seguras
- Escalável – centenas de modelos e aplicações com capacidade de escalonamento automático
- Confiável – recuperação minimalista e rápida de falhas
- Gerenciável – fácil de operar, atualizações contínuas
- Compatível com padrões – adote padrões de API e estruturas de modelo líderes de mercado
- Eficiente em termos de recursos – controles de recursos refinados e escala para zero
- Observável – monitora o desempenho do sistema e do modelo
- Desempenho – a melhor latência, rendimento e simultaneidade da categoria
- Isolado – evite vizinhos barulhentos para fornecer SLAs de serviço fortes
Essas e outras considerações nos levaram a criar o serviço Cloudera AI Inference como um serviço novo e desenvolvido especificamente para hospedar todos os modelos de produção de IA e aplicativos relacionados. É ideally suited para implantar modelos e aplicativos de IA sempre ativos que atendem a casos de uso críticos para os negócios.
Arquitetura de alto nível
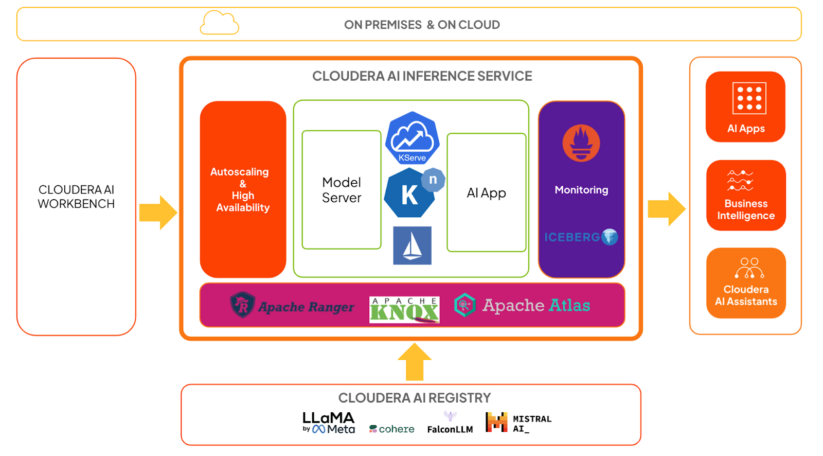
O diagrama acima mostra uma arquitetura de alto nível do serviço Cloudera AI Inference no contexto:
- KServe e Knative lidam com modelo e orquestração de aplicativos, respectivamente. Knative fornece a estrutura para escalonamento automático, incluindo escala para zero.
- Os servidores de modelo são responsáveis por executar modelos usando estruturas altamente otimizadas, que abordaremos em detalhes em uma postagem posterior.
- O Istio fornece a malha de serviço e aproveitamos seus recursos de extensão para adicionar autenticação e autorização fortes com Apache Knox e Apache Ranger.
- As cargas úteis de solicitação e resposta de inferência são enviadas de forma assíncrona para tabelas do Apache Iceberg. As equipes podem analisar os dados usando qualquer ferramenta de BI para fins de monitoramento e governança do modelo.
- As métricas do sistema, como latência de inferência e taxa de transferência, estão disponíveis como métricas do Prometheus. As equipes de dados podem usar qualquer ferramenta de painel de métricas para monitorá-las.
- Os usuários podem treinar e/ou ajustar modelos no AI Workbench e implantá-los no serviço Cloudera AI Inference para casos de uso de produção.
- Os usuários podem implantar modelos treinados, incluindo modelos GenAI ou modelos preditivos de aprendizagem profunda, diretamente no serviço Cloudera AI Inference.
- Os modelos hospedados no serviço Cloudera AI Inference podem ser facilmente integrados a aplicativos de IA, como chatbots, assistentes virtuais, pipelines RAG, previsões em tempo actual e em lote e muito mais, tudo com protocolos padrão como a API OpenAI e o Open Inference Protocol.
- Os usuários podem gerenciar todos os seus modelos e aplicativos no serviço Cloudera AI Inference com sistemas CI/CD comuns usando contas de serviço Cloudera, também conhecidos como usuários de máquina.
- O serviço pode orquestrar com eficiência centenas de modelos e aplicativos e dimensionar cada implantação para centenas de réplicas de forma dinâmica, desde que recursos de computação e rede estejam disponíveis.
Conclusão
Neste primeiro put up, apresentamos o serviço Cloudera AI Inference, explicamos por que o construímos e fizemos um tour de alto nível por sua arquitetura. Também descrevemos muitas de suas capacidades. Iremos nos aprofundar na arquitetura em nosso próximo put up, portanto, fique atento.