Mais rápido, mais inteligente, mais responsivo Aplicações de IA – é isso que seus usuários esperam. Mas quando os grandes modelos de linguagem (LLMs) demoram a responder, a experiência do usuário é prejudicada. Cada milissegundo conta.
Com os endpoints de inferência de alta velocidade da Cerebras, você pode reduzir a latência, acelerar as respostas do modelo e manter a qualidade em escala com modelos como o Llama 3.1-70B. Seguindo algumas etapas simples, você poderá personalizar e implantar seus próprios LLMs, proporcionando o controle para otimizar a velocidade e a qualidade.
Neste weblog, orientaremos você sobre como:
- Configure o Llama 3.1-70B no Parque DataRobot LLM.
- Gere e aplique uma chave de API para aproveitar o Cerebras para inferência.
- Personalize e implante aplicativos mais inteligentes e rápidos.
Ao closing, você estará pronto para implantar LLMs que oferecem velocidade, precisão e capacidade de resposta em tempo actual.
Prototipar, personalizar e testar LLMs em um só lugar
A prototipagem e o teste de modelos generativos de IA geralmente exigem uma colcha de retalhos de ferramentas desconectadas. Mas com um ambiente unificado e integrado para LLMstécnicas de recuperação e métricas de avaliação, você pode passar da ideia ao protótipo funcional com mais rapidez e menos obstáculos.
Esse processo simplificado significa que você pode se concentrar na criação de aplicativos de IA eficazes e de alto impacto, sem o incômodo de reunir ferramentas de diferentes plataformas.
Vamos examinar um caso de uso para ver como você pode aproveitar esses recursos para desenvolver aplicativos de IA mais inteligentes e rápidos.
Caso de uso: Acelerando a interferência LLM sem sacrificar a qualidade
A baixa latência é essencial para criar aplicativos de IA rápidos e responsivos. Mas as respostas aceleradas não têm de ser feitas à custa da qualidade.
A velocidade de Inferência cerebral supera outras plataformas, permitindo que os desenvolvedores criem aplicativos que pareçam suaves, responsivos e inteligentes.
Quando combinado com uma experiência de desenvolvimento intuitiva, você pode:
- Reduza a latência do LLM para interações mais rápidas do usuário.
- Experimente com mais eficiência com novos modelos e fluxos de trabalho.
- Implantar aplicativos que respondem instantaneamente às ações do usuário.
Os diagramas abaixo mostram o desempenho da Cerebras no Llama 3.1-70B, ilustrando tempos de resposta mais rápidos e menor latência do que outras plataformas. Isso permite iteração rápida durante o desenvolvimento e desempenho em tempo actual na produção.

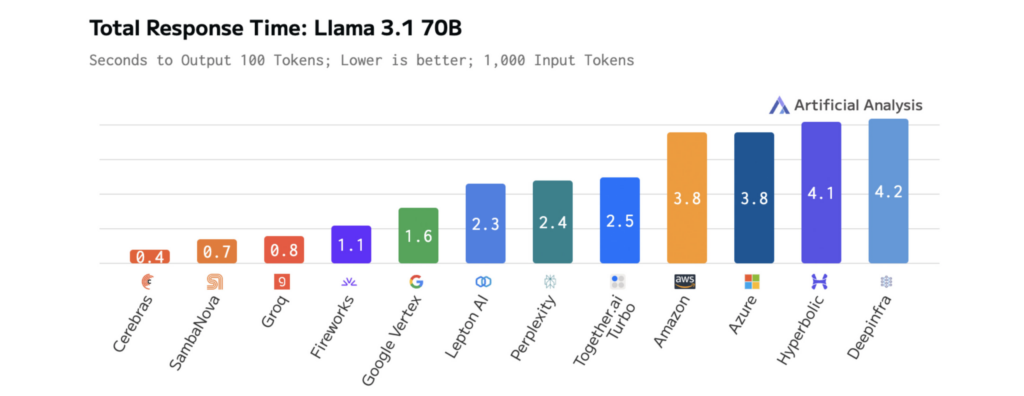
Como o tamanho do modelo afeta a velocidade e o desempenho do LLM
À medida que os LLMs se tornam maiores e mais complexos, os seus resultados tornam-se mais relevantes e abrangentes — mas isto tem um custo: maior latência. A Cerebras enfrenta esse desafio com cálculos otimizados, transferência de dados simplificada e decodificação inteligente projetada para velocidade.
Estas melhorias de velocidade já estão a transformar as aplicações de IA em indústrias como a farmacêutica e a IA de voz. Por exemplo:
- GlaxoSmithKline (GSK) usa o Cerebras Inference para acelerar a descoberta de medicamentos, aumentando a produtividade.
- Equipment ao vivo impulsionou o desempenho do pipeline de modo de voz do ChatGPT, alcançando tempos de resposta mais rápidos do que as soluções de inferência tradicionais.
Os resultados são mensuráveis. No Llama 3.1-70B, o Cerebras oferece inferência 70x mais rápida do que as GPUs vanilla, permitindo interações mais suaves e em tempo actual e ciclos de experimentação mais rápidos.
Esse desempenho é alimentado pelo Wafer-Scale Engine (WSE-3) de terceira geração da Cerebras, um processador personalizado projetado para otimizar as operações de álgebra linear esparsas baseadas em tensores que impulsionam a inferência LLM.
Ao priorizar desempenho, eficiência e flexibilidade, o WSE-3 garante resultados mais rápidos e consistentes durante o desempenho do modelo.
A velocidade do Cerebras Inference reduz a latência de aplicações de IA alimentadas por seus modelos, permitindo um raciocínio mais profundo e experiências de usuário mais responsivas. Acessar esses modelos otimizados é simples: eles estão hospedados no Cerebras e acessíveis por meio de um único endpoint, para que você possa começar a aproveitá-los com configuração mínima.

Passo a passo: como personalizar e implantar o Llama 3.1-70B para IA de baixa latência
Integrando LLMs como Llama 3.1-70B da Cerebras em DataRobot permite personalizar, testar e implantar modelos de IA em apenas algumas etapas. Este processo oferece suporte a desenvolvimento mais rápido, testes interativos e maior controle sobre a personalização do LLM.
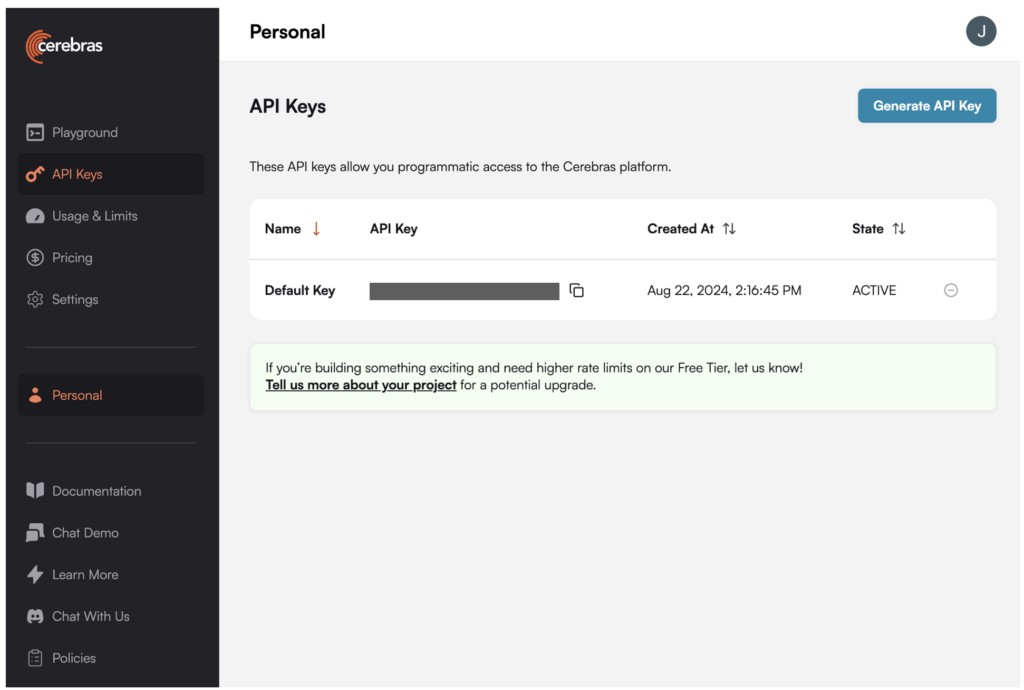
1. Gere uma chave API para Llama 3.1-70B na plataforma Cerebras.
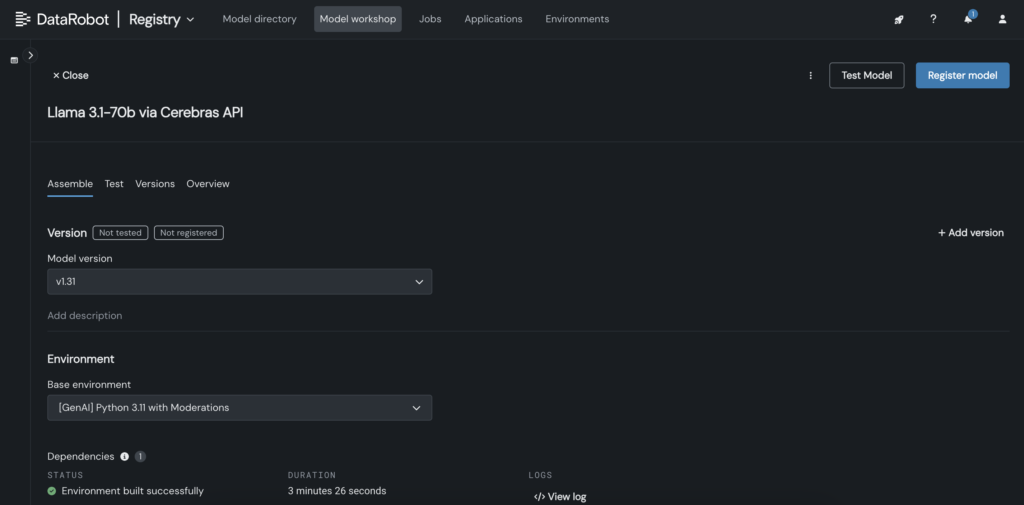
2. No DataRobot, crie um modelo personalizado no Mannequin Workshop que chame o endpoint Cerebras onde o Llama 3.1 70B está hospedado.
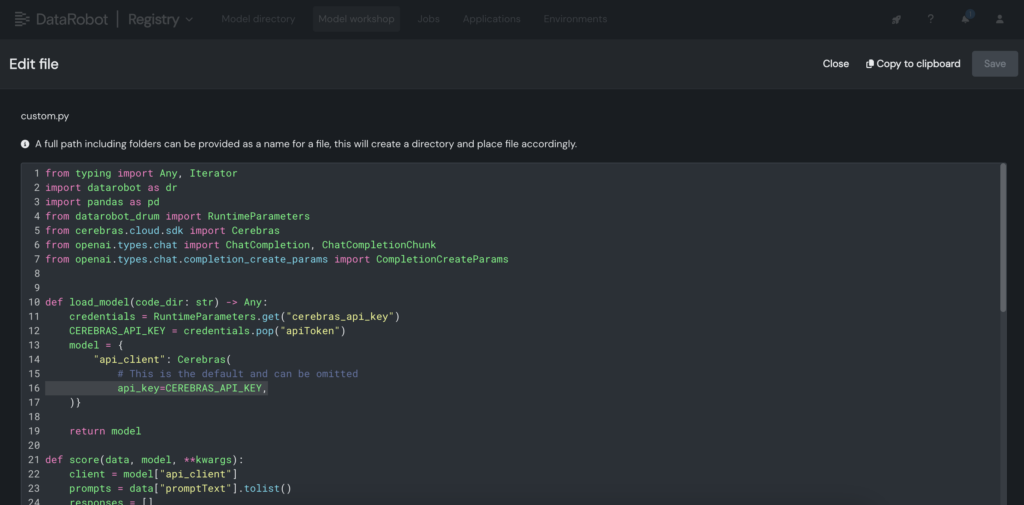
3. Dentro do modelo customizado, coloque a chave API Cerebras dentro do arquivo customized.py.
4. Implante o modelo personalizado em um terminal no console DataRobot, permitindo que os projetos LLM o aproveitem para inferência.
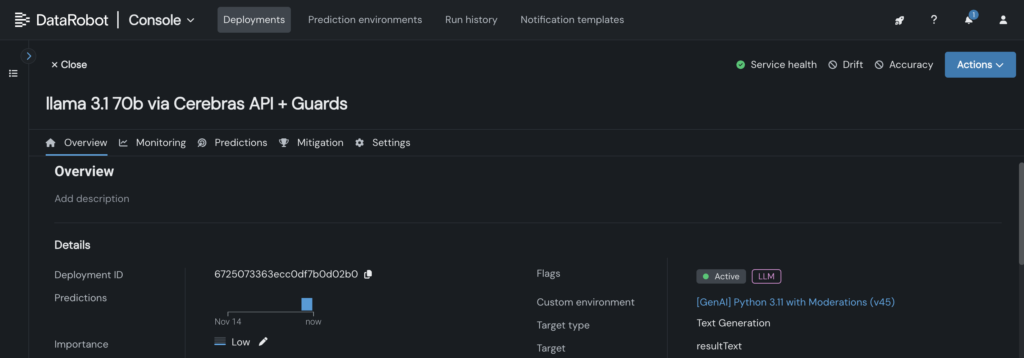
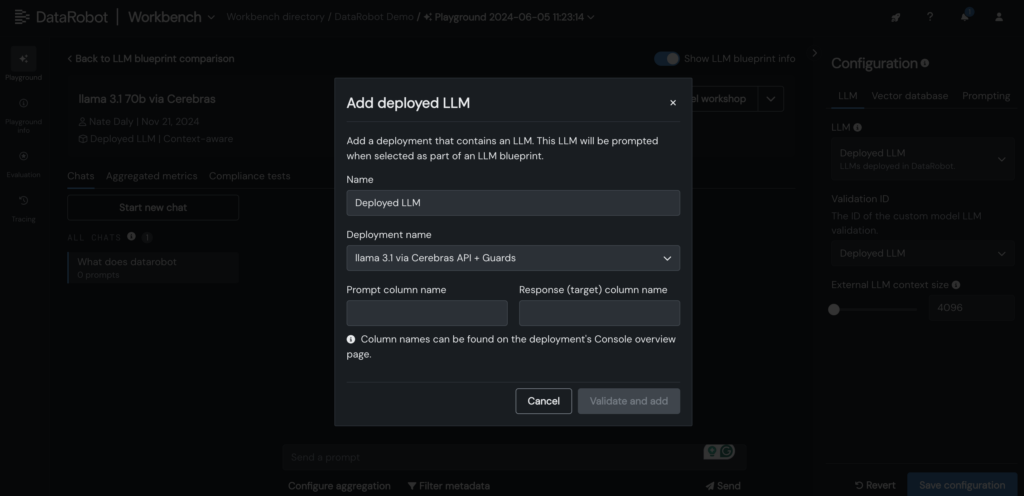
5. Adicione seu Cerebras LLM implantado ao blueprint LLM no DataRobot LLM Playground para começar a conversar com o Llama 3.1 -70B.
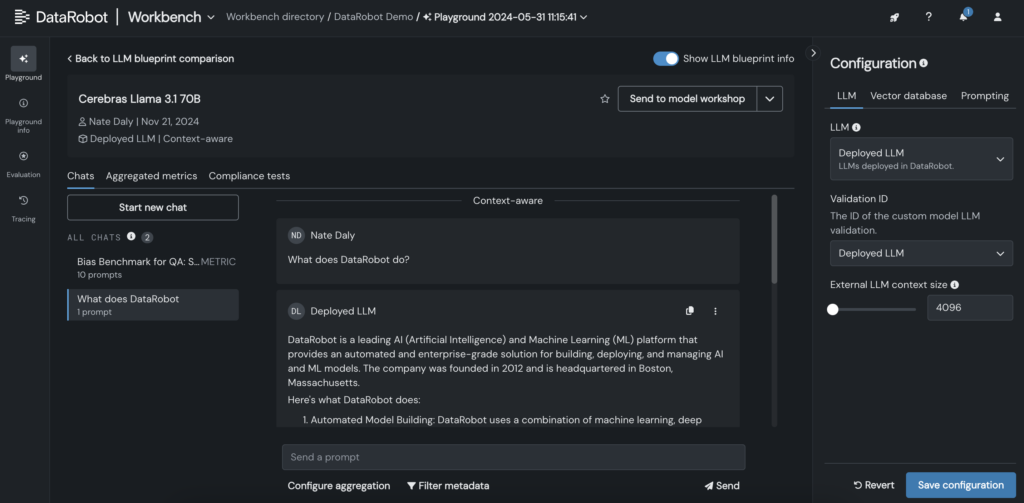
6. Depois que o LLM for adicionado ao blueprint, teste as respostas ajustando os parâmetros de solicitação e recuperação e examine os resultados com outros LLMs diretamente na GUI do DataRobot.
Expanda os limites da inferência LLM para suas aplicações de IA
Implantar LLMs como o Llama 3.1-70B com baixa latência e capacidade de resposta em tempo actual não é uma tarefa fácil. Mas com as ferramentas e fluxos de trabalho certos, você pode conseguir ambos.
Ao integrar LLMs ao LLM Playground da DataRobot e aproveitar a inferência otimizada da Cerebras, você pode simplificar a personalização, acelerar os testes e reduzir a complexidade – tudo isso enquanto mantém o desempenho que seus usuários esperam.
À medida que os LLMs se tornam maiores e mais poderosos, ter um processo simplificado para testes, personalização e integração será essencial para as equipes que desejam permanecer à frente.
Discover você mesmo. Acesso Inferência cerebralgere sua chave de API e comece a criar Aplicações de IA no DataRobot.
Sobre o autor

Kumar Venkateswar é vice-presidente de produto, plataforma e ecossistema da DataRobot. Ele lidera o gerenciamento de produtos para os serviços fundamentais e parcerias de ecossistemas da DataRobot, preenchendo as lacunas entre infraestrutura eficiente e integrações que maximizam os resultados da IA. Antes da DataRobot, Kumar trabalhou na Amazon e na Microsoft, incluindo liderança de equipes de gerenciamento de produtos para Amazon SageMaker e Amazon Q Enterprise.

Nathaniel Daly é gerente de produto sênior da DataRobot com foco em AutoML e produtos de série temporal. Ele está focado em trazer avanços na ciência de dados aos usuários, para que eles possam aproveitar esse valor para resolver problemas de negócios do mundo actual. Ele é formado em Matemática pela Universidade da Califórnia, Berkeley.