Esta postagem foi de coautoria de Mike Araujo Engenheiro Principal da Medidata Options.
A indústria das ciências da vida está a transitar de ferramentas fragmentadas e autónomas para soluções integradas e baseadas em plataformas. Medidatauma empresa Dassault Systèmes, está construindo uma plataforma de dados de próxima geração que aborda os desafios complexos da pesquisa clínica moderna. Nesta postagem, mostramos como a Medidata criou uma plataforma de dados unificada, escalável e em tempo actual que atende milhares de ensaios clínicos em todo o mundo com serviços AWS, Iceberg Apachee uma arquitetura moderna de lago.
Desafios com arquitetura legada
À medida que o repositório de dados clínicos da Medidata se expandia, a equipe reconheceu as deficiências da solução de dados herdada para fornecer produtos de dados de qualidade aos seus clientes em todo o seu crescente portfólio de ofertas de dados. Vários inquilinos de dados começaram a sofrer erosão. O diagrama a seguir mostra a arquitetura legada de extração, transformação e carregamento (ETL) da Medidata.

Construído com base em uma série de trabalhos em lote programados, o sistema legado mostrou-se mal equipado para fornecer uma visão unificada dos dados em todo o ecossistema. Os trabalhos em lote eram executados em intervalos diferentes, muitas vezes exigindo um grau suficiente de buffer de agendamento para garantir que os trabalhos upstream fossem concluídos dentro da janela esperada. À medida que o quantity de dados se expandiu, os trabalhos e os seus horários continuaram a aumentar, introduzindo uma janela de latência entre a ingestão e o processamento para consumidores dependentes. Diferentes consumidores operando a partir de vários serviços de dados subjacentes ampliaram ainda mais o problema, pois os pipelines tiveram que ser construídos continuamente em uma variedade de pilhas de entrega de dados.
O portfólio crescente de oleodutos começou a sobrecarregar as operações de manutenção existentes. Com mais operações, a oportunidade de falha aumentou e os esforços de recuperação complicaram-se ainda mais. Os sistemas de observabilidade existentes foram inundados com dados operacionais, e identificar a causa raiz dos problemas de qualidade dos dados tornou-se um esforço de vários dias. Os aumentos no quantity de dados exigiram considerações de dimensionamento em todo o conjunto de dados.
Além disso, a proliferação de pipelines de dados e cópias dos dados em diferentes tecnologias e sistemas de armazenamento exigiu a expansão dos controles de acesso com recursos de segurança aprimorados para garantir que apenas os usuários corretos tivessem acesso ao subconjunto de dados aos quais tinham permissão. Garantir que as alterações no controle de acesso fossem propagadas corretamente em todos os sistemas adicionou uma camada adicional de complexidade para consumidores e produtores.
Visão geral da solução
Com o advento do Scientific Knowledge Studio (solução unificada de gerenciamento e análise de dados da Medidata para ensaios clínicos) e do Knowledge Join (solução de dados da Medidata para aquisição, transformação e troca de dados de registros eletrônicos de saúde (EHR) entre organizações de saúde), a Medidata introduziu um novo mundo de descoberta, análise e integração de dados para o setor de ciências biológicas, alimentado por tecnologias de código aberto e hospedado na AWS. O diagrama a seguir ilustra a arquitetura da solução.
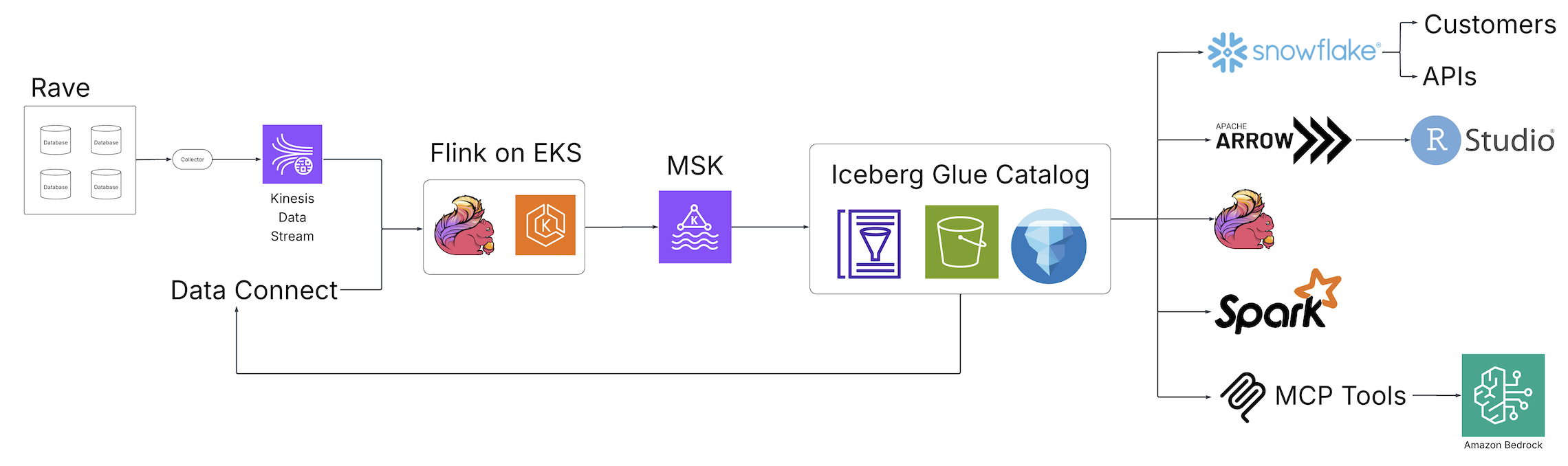
Os trabalhos de ETL em lote fragmentado foram substituídos por trabalhos em tempo actual Apache Flink pipelines de streaming, um mecanismo distribuído de código aberto para processamento com estado e alimentado por Serviço Amazon Elastic Kubernetes (Amazon EKS), um serviço Kubernetes totalmente gerenciado. Os trabalhos do Flink gravam no Apache Kafka em execução Apache Kafka gerenciado pela Amazon (Amazon MSK), um serviço de streaming de dados que gerencia a infraestrutura e as operações do Kafka, antes de chegar às tabelas Iceberg apoiadas pelo Catálogo de dados do AWS Glueum repositório centralizado de metadados para ativos de dados. A partir desta coleção de tabelas Iceberg, uma fonte central e única de dados está agora acessível a partir de uma variedade de consumidores sem processamento downstream adicional, aliviando a necessidade de pipelines personalizados para satisfazer os requisitos dos consumidores downstream. Por meio dessas mudanças arquitetônicas fundamentais, a equipe da Medidata resolveu os problemas apresentados pela solução legada.
Disponibilidade e consistência de dados
Com a introdução dos trabalhos Flink e das tabelas Iceberg, a equipe conseguiu fornecer uma visão consistente de seus dados em toda a experiência de dados da Medidata. A latência do pipeline foi reduzida de dias para minutos, ajudando os clientes da Medidata a obter um ganho de desempenho de 99% desde a ingestão de dados até as camadas de análise de dados. Devido à interoperabilidade do Iceberg, os usuários do Medidata tiveram a mesma visão dos dados, independentemente de onde os visualizaram, minimizando a necessidade de pipelines personalizados voltados para o consumidor, porque o Iceberg poderia se conectar aos consumidores existentes.
Manutenção e durabilidade
A interoperabilidade do Iceberg proporcionou uma única cópia dos dados para satisfazer seus casos de uso, de modo que a equipe da Medidata pudesse concentrar seus esforços de observação e manutenção em um subconjunto de operações cinco vezes menor do que o necessário anteriormente. A observabilidade foi aprimorada ao explorar os vários componentes e métricas de metadados expostos pelo Iceberg e pelo Catálogo de Dados. O gerenciamento de qualidade foi transformado de rastreamentos e consultas entre sistemas para uma análise única de pipelines unificados, com o benefício adicional de consultas de dados pontuais, graças ao Recurso de instantâneo do iceberg. Os aumentos no quantity de dados são tratados com escalabilidade pronta para uso, compatível com toda a pilha de infraestrutura e recursos de otimização do AWS Glue Iceberg, que incluem compactação, retenção de instantâneoe exclusão de arquivo órfãoque fornecem uma experiência do tipo “configure e esqueça” para resolver uma série de frustrações comuns do Iceberg, como o problema de arquivos pequenos, retenção de arquivos órfãos e desempenho de consulta.
Segurança
Com o Iceberg no centro de sua arquitetura de solução, a equipe da Medidata não precisou mais perder tempo construindo camadas de controle de acesso personalizadas com recursos de segurança aprimorados em cada ponto de integração de dados. Iceberg na AWS centraliza a camada de autorização usando sistemas familiares, como Gerenciamento de identidade e acesso da AWS (IAM), fornecendo um controle único e durável para acesso a dados. Os dados também permanecem inteiramente na nuvem privada digital (VPC) Medidata, reduzindo ainda mais a oportunidade de divulgações não intencionais.
Conclusão
Nesta postagem, demonstramos como o universo legado de pipelines ETL personalizados voltados para o consumidor pode ser substituído por lakehouses de streaming escalonáveis e de alto desempenho. Ao colocar o Iceberg na AWS no centro das operações de dados, você pode ter uma única fonte de dados para seus consumidores.
Para saber mais sobre o Iceberg na AWS, consulte Otimizando tabelas Iceberg e Usando Apache Iceberg na AWS.