
O modelo de IA incorporado de Vidar de Shengshu usa mundos simulados em vez de dados de treinamento físico. Fonte: Adobe Inventory, VectorHub by Ice
A Shengshu Know-how Co. lançou ontem seu modelo de treinamento físico de IA em várias visualizações, Vidar-que significa “Difusão de vídeo para o raciocínio de ação”. Usando os recursos da Vidu em entendimento semântico e de vídeo, a Vidar usa um conjunto limitado de dados físicos para simular a tomada de decisão de um robô em ambientes do mundo actual, disse a empresa.
“A Vidar oferece uma abordagem radicalmente diferente para o treinamento de modelos incorporados de IA”, afirmou a tecnologia Shengshu. “Assim como a Tesla se concentra no treinamento baseado na visão e a Waymo se inclina para o Lidar, a indústria está explorando caminhos divergentes para a IA física”.
Fundada em março de 2023, a Shengshu Know-how é especializada no desenvolvimento de modelos de grandes idiomas multimodais (LLMS). A empresa com sede em Pequim disse que oferece produtos de mobilidade como serviço (MAAs) e software program como serviço (SaaS) para criação de conteúdo mais inteligente, mais rápida e escalável.
Com sua plataforma de geração de vídeo principal ViduShengshu disse que alcançou usuários em mais de 200 países e regiões em todo o mundo, abrangendo campos, incluindo entretenimento interativo, publicidade, cinema, animação, turismo cultural e muito mais.
Vidar simulou treinamento para acelerar o desenvolvimento de robôs
“Enquanto algumas empresas treinam físicas Ai Ao incorporar modelos em robôs do mundo actual e coletar dados através das interações físicas que seus robôs encontram, é um método caro, dependente de {hardware} e difícil de escalar “, disse a tecnologia Shengshu.
Vidar adota uma abordagem diferente, afirmou a empresa. Ele combina dados de treinamento físico limitados com vídeo generativo para fazer previsões e gerar novos cenários hipotéticos, criando uma visão de várias vistas simulação Apresentando ambientes de treinamento realistas, tudo dentro de um espaço digital. Isso permite um treinamento mais robusto e escalável sem tempo, custo ou limitações da coleta de dados do mundo físico, explicou Shengshu.
Construído sobre o modelo de vídeo generativo do Vidu, o Vidar pode executar tarefas de manipulação de braço duplo com previsão de vídeo com várias visualizações e até responder a comandos de voz em língua pure após o ajuste fino. O modelo Efetivamente, serve como um cérebro digital para ação do mundo actual, disse a empresa.
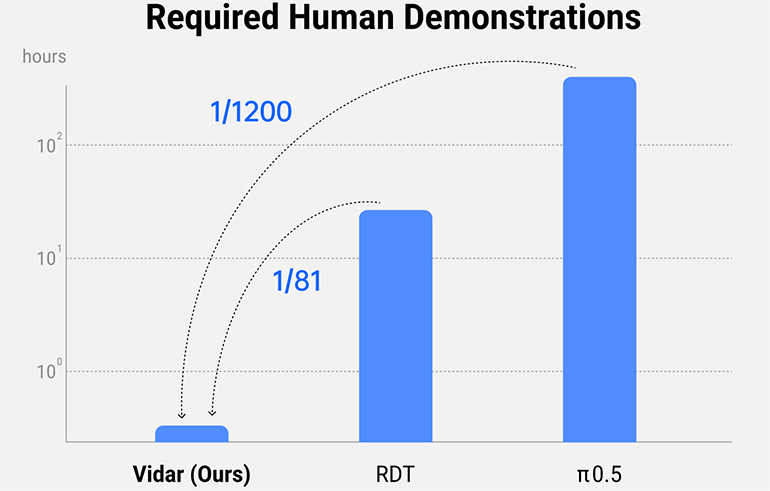
Usando o mecanismo de vídeo generativo da Vidu, o Vidar gera simulações em larga escala para reduzir a dependência de dados físicos, mantendo a complexidade e a riqueza necessárias para treinar agentes de IA com capacidade para o mundo actual. Shengshu disse que o Vidar pode extrapolar uma série generalizada de ações e tarefas robóticas de apenas 20 minutos de dados de treinamento. A empresa afirmou que está entre 1/80 e 1/1.200 dos dados necessários para treinar modelos líderes do setor, incluindo RDT e π0.5.
Shengshu disse que a principal inovação da Vidar está em sua arquitetura modular de aprendizado de dois estágios. Diferentemente dos métodos tradicionais que mesclam percepção e controle, Vidar os separa em dois estágios distintos para maior flexibilidade e escalabilidade.
No estágio a montante, os dados gerais de vídeo em larga escala e os dados de vídeo incorporados em escala moderada são usados para treinar o modelo de Vidu para o entendimento perceptivo.
No segundo estágio a jusante, um modelo agnóstico de tarefa chamado Anypos transforma esse entendimento visible em comandos de motores acionáveis para robôs. Essa separação torna significativamente mais fácil e mais rápido treinar e implantar IA em diferentes tipos de robôs, reduzindo os custos e aumentando a escalabilidade.
O Vidar foi projetado para reduzir a quantidade de dados de treinamento necessários para treinar os modelos de IA. Fonte: Tecnologia Shengshu.
Vidar uma estrutura para inteligência incorporada escalável
O Vidar segue uma estrutura de treinamento escalável, inspirada nos modelos de linguagem e imagem da última década de avanços da IA. Shengshu disse que sua pirâmide de dados de três camadas, abrangendo vídeo genérico em larga escala, dados de vídeo incorporado e exemplos específicos de robôs, contribui para um sistema mais flexível, reduzindo o gargalo tradicional de dados.
Construído sobre a arquitetura U-Vit, que explora a fusão de modelos de difusão e arquiteturas de transformadores para uma ampla variedade de tarefas de geração multimodal, o Vidar aproveita a modelagem temporal de longo prazo e a consistência de vídeo com vários ângulos para a tomada de decisões fisicamente fundamentadas.
Esse design suporta a rápida transferência da simulação para a implantação do mundo actual, que Shengshu disse que é basic para a robótica em ambientes dinâmicos. Ele também minimiza a complexidade da engenharia, de acordo com a empresa,
Shengshu disse que a Vidar pode facilitar a adoção de robótica em vários setores. De assistentes domésticos e cuidados de idosos à fabricação inteligente e robótica médica, o modelo permite uma adaptação rápida a novos ambientes e cenários de várias tarefas, todos com dados mínimos, acrescentou.
Vidar cria um caminho nativo para o desenvolvimento da robótica eficiente, escalável e econômico, afirmou Shengshu. Ao transformar o vídeo geral em inteligência robótica acionável, a empresa disse que seu modelo pode preencher a lacuna entre o entendimento visible e a agência incorporada.

Vidar tem uma arquitetura de aprendizado modular. Fonte: Tecnologia Shengshu
Shengshu marca os marcos em IA multimodal
Vidar se baseia no rápido impulso do modelo de Fundação de Video Vidu, disse Shengshu. A empresa listou estatísticas desde sua estréia:
- Vidu atingiu 1 milhão de usuários dentro de um mês
- Superou 10 milhões de usuários em apenas três meses
- Gerou mais de 100 milhões de vídeos até o mês 4
- A geração de referência para o videão excedeu 100 milhões no mês 8
- Whole de vídeos gerados agora com os 300 milhões de 300 milhões
Shengshu continua a expandir as fronteiras da IA multimodal, o Vidar representa a próxima fronteira – generalização, generatividade e modalidade da criação em um sistema unificado.
Nota do editor: Robobusiness 2025, que será nos dias 15 e 16 de outubro em Santa Clara, Califórnia, incluirá faixas em AI física e humanóide robôs. O registro está agora aberto.
