Velocidade, escala e colaboração são essenciais para equipes de IA, mas dados estruturados limitados, recursos computacionais e fluxos de trabalho centralizados muitas vezes atrapalham.
Quer você seja um cliente da DataRobot ou um profissional de IA em busca de maneiras mais inteligentes de preparar e modelar grandes conjuntos de dados, novas ferramentas como aprendizado incremental, reconhecimento óptico de caracteres (OCR) e preparação aprimorada de dados eliminarão obstáculos, ajudando você a construir modelos mais precisos em menos tempo.
Aqui está o que há de novo no Experiência no DataRobot Workbench:
- Aprendizagem incremental: modele grandes volumes de dados de maneira eficiente com maior transparência e controle.
- Reconhecimento óptico de caracteres (OCR): Converta instantaneamente PDFs digitalizados não estruturados em dados utilizáveis para preditivo e generativo AEu uso casos.
- Colaboração mais fácil: Trabalhe com sua equipe em um espaço unificado com acesso compartilhado à preparação de dados, desenvolvimento generativo de IA e ferramentas de modelagem preditiva.
Modele com eficiência grandes volumes de dados com aprendizado incremental
A construção de modelos com grandes conjuntos de dados geralmente leva a custos de computação surpreendentes, ineficiências e despesas descontroladas. O aprendizado incremental take away essas barreiras, permitindo modelar grandes volumes de dados com precisão e controle.
Em vez de processar um conjunto de dados inteiro de uma só vez, o aprendizado incremental executa iterações sucessivas nos dados de treinamento, usando apenas a quantidade de dados necessária para atingir a precisão splendid.
Cada iteração é visualizada em um gráfico (veja a Figura 1), onde você pode acompanhar o número de linhas processadas e a precisão obtida – tudo com base na métrica escolhida.

Principais vantagens de aprendizagem incremental:
- Processe apenas os dados que geram resultados.
O aprendizado incremental interrompe os trabalhos automaticamente quando são detectados retornos decrescentes, garantindo que você use dados suficientes para obter a precisão splendid. No DataRobot, cada iteração é rastreada, então você verá claramente quantos dados produzem os resultados mais fortes. Você está sempre no controle e pode personalizar e executar iterações adicionais para acertar.
- Treine com a quantidade certa de dados
O aprendizado incremental evita o overfitting ao iterar em amostras menores, para que seu modelo aprenda padrões – não apenas os dados de treinamento.
- Automatize fluxos de trabalho complexos:
Garanta que esse provisionamento de dados seja rápido e livre de erros. Os usuários avançados de código podem dar um passo além e agilizar o novo treinamento usando pesos salvos para processar apenas novos dados. Isso evita a necessidade de reexecutar todo o conjunto de dados do zero, reduzindo erros de configuração handbook.
Quando aproveitar melhor o aprendizado incremental
Existem dois cenários principais em que a aprendizagem incremental impulsiona a eficiência e o controle:
- Trabalhos de modelagem únicos
Você pode personalizar a parada antecipada em grandes conjuntos de dados para evitar processamento desnecessário, evitar overfitting e garantir a transparência dos dados.
- Modelos dinâmicos e atualizados regularmente
Para modelos que reagem a novas informações, os usuários avançados de código inicial podem criar pipelines que adicionam novos dados aos conjuntos de treinamento sem uma nova execução completa.
Ao contrário de outras plataformas de IA, o aprendizado incremental oferece controle sobre grandes trabalhos de dados, tornando-os mais rápidos, mais eficientes e menos dispendiosos.
Como o reconhecimento óptico de caracteres (OCR) prepara dados não estruturados para IA
Ter acesso a grandes quantidades de dados utilizáveis pode ser uma barreira para a construção de modelos preditivos precisos e para alimentar chatbots de geração aumentada de recuperação (RAG). Isto é especialmente verdade porque 80-90% dos dados da empresa são dados não estruturados, que podem ser difíceis de processar. O OCR take away essa barreira ao transformar PDFs digitalizados em um formato utilizável e pesquisável para IA preditiva e generativa.
Como funciona
OCR é um recurso de codificação inicial do DataRobot. Ao chamar a API, você pode transformar um arquivo ZIP de PDFs digitalizados em um conjunto de dados de PDFs com texto incorporado. O texto extraído é incorporado diretamente no documento PDF, pronto para ser acessado por documentar recursos de IA.

Como o OCR pode potencializar a IA multimodal
Nossa nova funcionalidade de OCR não se destina apenas a IA generativa ou bancos de dados vetoriais. Também simplifica a preparação de dados prontos para IA para modelos preditivos multimodais, permitindo insights mais ricos de diversas fontes de dados.
Preparação de dados de IA preditiva multimodal
Transforme rapidamente documentos digitalizados em um conjunto de dados de PDFs com texto incorporado. Isso permite extrair informações importantes e criar recursos de seus modelos preditivos usando documentar capacidades de IA.
Por exemplo, digamos que você queira prever despesas operacionais, mas só tenha acesso às faturas digitalizadas. Ao combinar OCR, extração de texto de documentos e integração com Apache Airflow, você pode transformar essas faturas em uma fonte de dados poderosa para seu modelo.
Alimentando RAG LLMs com bancos de dados vetoriais
Grandes bancos de dados vetoriais suportam geração aumentada de recuperação (RAG) mais precisa para LLMs, especialmente quando suportados por conjuntos de dados maiores e mais ricos. OCR desempenha um papel elementary ao transformar PDFs digitalizados em PDFs com texto incorporado, tornando esse texto utilizável como vetores para fornecer respostas LLM mais precisas.
Caso de uso prático
Think about construir um chatbot RAG que responda a perguntas complexas dos funcionários. Os documentos de benefícios dos funcionários costumam ser densos e difíceis de pesquisar. Ao usar o OCR para preparar esses documentos para IA generativa, você pode enriquecer um LLM, permitindo que os funcionários obtenham respostas rápidas e precisas em formato de autoatendimento.
Migrações do WorkBench que impulsionam a colaboração
A colaboração pode ser um dos maiores bloqueadores da entrega rápida de IA, especialmente quando as equipes são forçadas a trabalhar com diversas ferramentas e fontes de dados. O NextGen WorkBench da DataRobot resolve isso unificando os principais fluxos de trabalho de modelagem preditiva e generativa em um ambiente compartilhado.
Essa migração significa que você pode criar modelos preditivos e generativos usando a interface gráfica do usuário (GUI) e notebooks e codespaces baseados em código — tudo em um único espaço de trabalho. Ele também traz recursos avançados de preparação de dados para o mesmo ambiente, para que as equipes possam colaborar em fluxos de trabalho de IA de ponta a ponta sem trocar de ferramentas.
Acelere a preparação de dados onde você desenvolve modelos
A preparação de dados geralmente leva até 80% do tempo de um cientista de dados. O NextGen WorkBench agiliza esse processo com:
- Detecção de qualidade de dados e recuperação automatizada de dados: identifique e resolva problemas como valores ausentes, valores discrepantes e erros de formatação automaticamente.
- Detecção e redução automatizada de recursos: Identifique automaticamente os principais recursos e remova os de baixo impacto, reduzindo a necessidade de engenharia handbook de recursos.
- Visualizações prontas para uso de análise de dados: gere visualizações interativas instantaneamente para explorar conjuntos de dados e detectar tendências.
Melhore a qualidade dos dados e visualize problemas instantaneamente
Problemas de qualidade de dados, como valores ausentes, valores discrepantes e erros de formato, podem retardar o desenvolvimento da IA. O NextGen WorkBench resolve isso com verificações automatizadas e insights visuais que economizam tempo e reduzem o esforço handbook.
Agora, quando você carrega um conjunto de dados, as verificações automáticas verificam os principais problemas de qualidade dos dados, incluindo:
- Valores discrepantes
- Erros de formato multicategórico
- Inliers
- Excesso de zeros
- Valores ausentes disfarçados
- Vazamento alvo
- Imagens ausentes (somente em conjuntos de dados de imagens)
- Informações de identificação pessoal
Essas verificações de qualidade de dados são combinadas com visualizações EDA (análise exploratória de dados) prontas para uso. Novos conjuntos de dados são visualizados automaticamente em gráficos interativos, proporcionando visibilidade instantânea das tendências dos dados e possíveis problemas, sem a necessidade de criar gráficos por conta própria. A Figura 3 abaixo demonstra como os problemas de qualidade são destacados diretamente no gráfico.
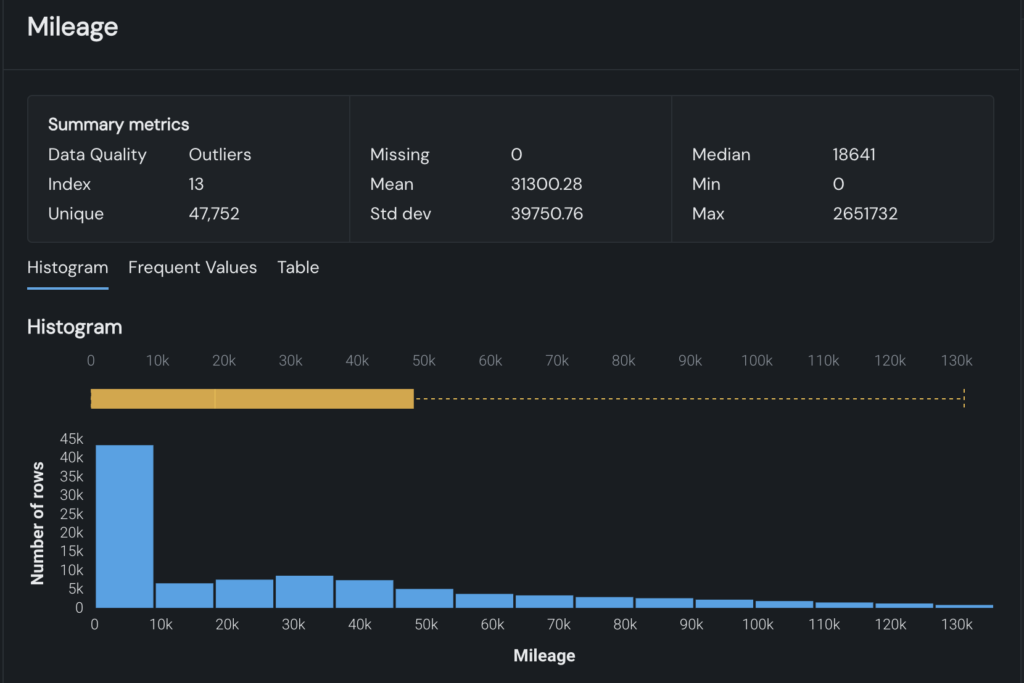
Automatize a detecção de recursos e reduza a complexidade
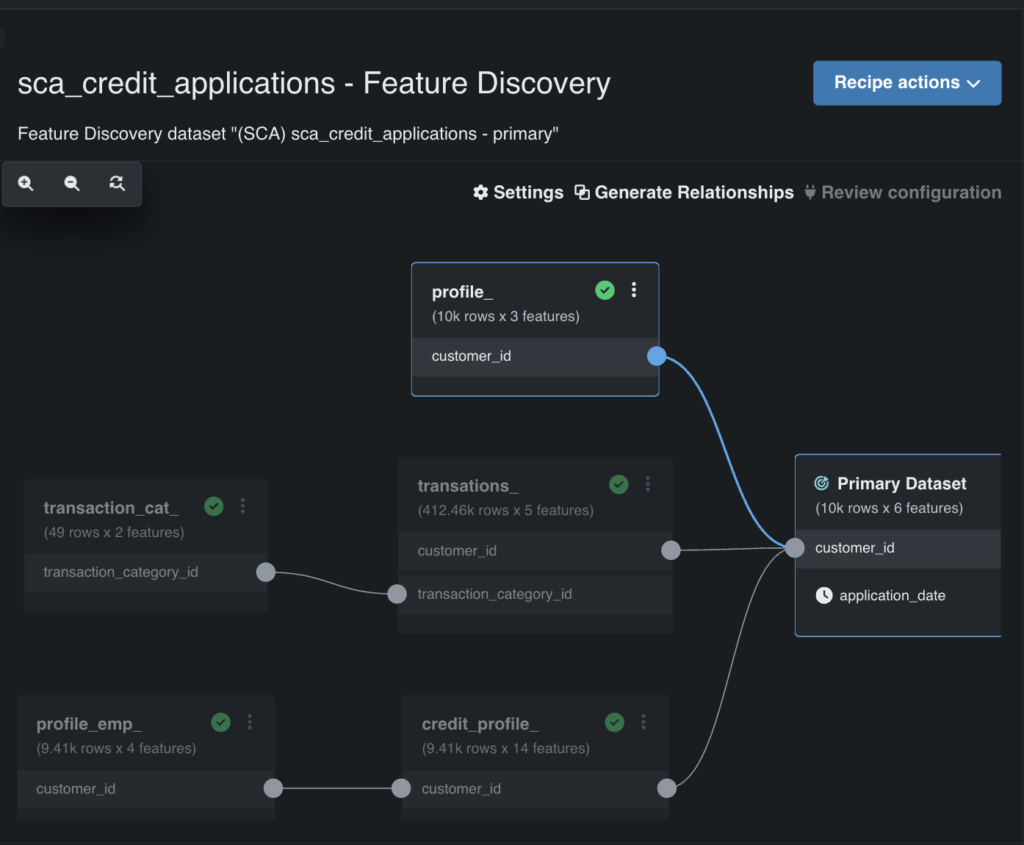
A detecção automatizada de recursos ajuda a simplificar a engenharia de recursos, facilitando a junção de conjuntos de dados secundários, a detecção de recursos principais e a remoção de recursos de baixo impacto.
Esse recurso verifica todos os seus conjuntos de dados secundários para encontrar semelhanças — como IDs de clientes (veja a Figura 4) — e permite juntá-los automaticamente em um conjunto de dados de treinamento. Também identifica e take away recursos de baixo impacto, reduzindo a complexidade desnecessária.
Você mantém controle complete, com a capacidade de revisar e personalizar quais recursos são incluídos ou excluídos.
Não deixe que fluxos de trabalho lentos atrasem você
A preparação de dados não precisa ocupar 80% do seu tempo. Ferramentas desconectadas não precisam retardar seu progresso. E os dados não estruturados não precisam estar fora de alcance.
Com a próxima geração Bancada de trabalhovocê terá as ferramentas para avançar com mais rapidez, simplificar fluxos de trabalho e criar com menos esforço handbook. Esses recursos já estão disponíveis para você – é só uma questão de colocá-los para funcionar.
Se você estiver pronto para ver o que é possível, discover a experiência NextGen em um teste gratuito.
Sobre o autor
