
Os agentes de IA estão remodelando o desenvolvimento de software program, desde a escrita de código até a execução de instruções complexas. No entanto, os agentes baseados em LLM são propensos a erros e muitas vezes têm um desempenho insatisfatório em tarefas complicadas e de várias etapas. A aprendizagem por reforço (RL) é uma abordagem em que os sistemas de IA aprendem a tomar decisões ideais, recebendo recompensas ou penalidades pelas suas ações, melhorando através de tentativa e erro. A RL pode ajudar os agentes a melhorar, mas normalmente exige que os desenvolvedores reescrevam extensivamente seu código. Isto desencoraja a adoção, embora os dados gerados por estes agentes possam aumentar significativamente o desempenho através do treino de RL.
Para resolver isso, uma equipe de pesquisa da Microsoft Analysis Ásia – Xangai introduziu Agente Relâmpago. Esse código aberto (abre em nova aba) A estrutura torna os agentes de IA treináveis por meio de RL, separando a forma como os agentes executam tarefas do treinamento do modelo, permitindo que os desenvolvedores adicionem recursos de RL praticamente sem modificação de código.
Capturando o comportamento do agente para treinamento
O Agent Lightning converte a experiência de um agente em um formato que RL pode usar, tratando a execução do agente como uma sequência de estados e ações, onde cada estado captura o standing do agente e cada chamada LLM é uma ação que transfer o agente para um novo estado.
Essa abordagem funciona para qualquer fluxo de trabalho, não importa quão complexo seja. Quer envolva vários agentes colaboradores ou uso de ferramentas dinâmicas, o Agent Lightning divide tudo em uma sequência de transições. Cada transição captura a entrada, a saída e a recompensa do LLM (Figura 1). Este formato padronizado significa que os dados podem ser usados para treinamento sem quaisquer etapas adicionais.

Aprendizagem por reforço hierárquico
O treinamento tradicional de RL para agentes que fazem múltiplas solicitações de LLM envolve juntar todo o conteúdo em uma longa sequência e, em seguida, identificar quais partes devem ser aprendidas e quais devem ser ignoradas durante o treinamento. Esta abordagem é difícil de implementar e pode criar sequências excessivamente longas que degradam o desempenho do modelo.
Em vez disso, o algoritmo LightningRL do Agent Lightning adota uma abordagem hierárquica. Após a conclusão de uma tarefa, um módulo de atribuição de crédito determina quanto cada solicitação de LLM contribuiu para o resultado e atribui a ela uma recompensa correspondente. Essas etapas independentes, agora combinadas com suas próprias pontuações de recompensa, podem ser usadas com qualquer algoritmo RL de etapa única existente, como Otimização de Política Proximal (PPO) ou Otimização de Política Relativa de Grupo (GRPO) (Figura 2).
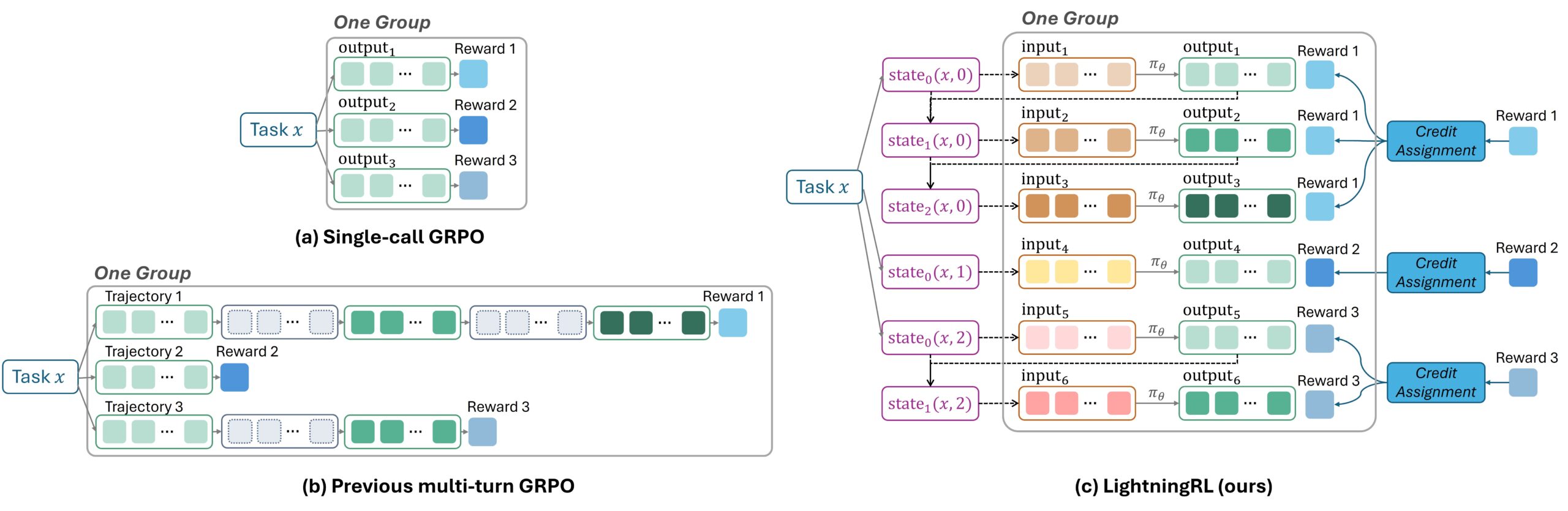
Este design oferece vários benefícios. Ele permanece totalmente compatível com algoritmos RL de etapa única amplamente utilizados, permitindo que métodos de treinamento existentes sejam aplicados sem modificação. A organização dos dados como uma sequência de transições independentes permite que os desenvolvedores construam com flexibilidade a entrada do LLM conforme necessário, dando suporte a comportamentos complexos, como agentes que usam diversas ferramentas ou trabalham com outros agentes. Além disso, ao manter as sequências curtas, a abordagem é dimensionada de forma limpa e mantém o treinamento eficiente.
Agente Lightning como middleware
O Agent Lightning serve como middleware entre algoritmos de RL e ambientes de agente, fornecendo componentes modulares que permitem RL escalonável por meio de protocolos padronizados e interfaces bem definidas.
Um agente corredor gerencia os agentes à medida que eles concluem as tarefas. Distribui o trabalho e coleta e armazena os resultados e dados de progresso. Ele opera separadamente dos LLMs, permitindo que sejam executados em diferentes recursos e dimensionados para suportar vários agentes em execução simultaneamente.
Um algoritmo treina os modelos e hospeda os LLMs usados para inferência e treinamento. Ele orquestra o ciclo geral de RL, gerenciando quais tarefas são atribuídas, como os agentes as concluem e como os modelos são atualizados com base no que os agentes aprendem. Normalmente é executado em recursos de GPU e se comunica com o executor do agente por meio de protocolos compartilhados.
O Loja relâmpago (abre em nova aba) serve como repositório central para todas as trocas de dados dentro do sistema. Ele fornece interfaces padronizadas e um formato compartilhado, garantindo que os diferentes componentes possam trabalhar juntos e permitindo que o algoritmo e o executor do agente se comuniquem de forma eficaz.

Todos os ciclos de RL seguem duas etapas: (1) O Agente Lightning coleta dados de execução do agente (chamados de “spans”) e os armazena no armazenamento de dados; (2) ele então recupera os dados necessários e os envia ao algoritmo para treinamento. Por meio desse design, o algoritmo pode delegar tarefas de forma assíncrona ao executor do agente, que as conclui e reporta os resultados (Figura 4).

Uma das principais vantagens desta abordagem é a sua flexibilidade algorítmica. O sistema facilita aos desenvolvedores personalizar a forma como os agentes aprendem, seja definindo diferentes recompensas, capturando dados intermediários ou experimentando diferentes abordagens de treinamento.
Outra vantagem é a eficiência de recursos. Os sistemas Agentic RL são complexos, integrando sistemas agentic, mecanismos de inferência LLM e estruturas de treinamento. Ao separar esses componentes, o Agent Lightning torna essa complexidade gerenciável e permite que cada parte seja otimizada de forma independente
Um design desacoplado permite que cada componente use o {hardware} que melhor lhe convier. O executor do agente pode usar CPUs enquanto o treinamento do modelo usa GPUs. Cada componente também pode ser dimensionado de forma independente, melhorando a eficiência e facilitando a manutenção do sistema. Na prática, os desenvolvedores podem manter suas estruturas de agente existentes e alternar chamadas de modelo para a API do Agent Lightning sem alterar o código do agente (Figura 5).

Avaliação em três cenários do mundo actual
O Agent Lightning foi testado em três tarefas distintas, alcançando melhorias consistentes de desempenho em todos os cenários (Figura 6):
Texto para SQL (LangChain): Em um sistema com três agentes que cuidam da geração, verificação e reescrita de SQL, o Agent Lightning otimizou simultaneamente dois deles, melhorando significativamente a precisão da geração de SQL executável a partir de consultas em linguagem pure.
Geração aumentada de recuperação (implementação do OpenAI Brokers SDK): No conjunto de dados de resposta a perguntas multi-hop MuSiQue, que requer consulta a um grande banco de dados da Wikipédia, o Agent Lightning ajudou o agente a gerar consultas de pesquisa mais eficazes e a raciocinar melhor a partir do conteúdo recuperado.
Controle de qualidade matemático e uso de ferramentas (implementação do AutoGen): Para problemas matemáticos complexos, o Agent Lightning treinou LLMs para determinar com mais precisão quando e como chamar a ferramenta e integrar os resultados ao seu raciocínio, aumentando a precisão.

Permitindo a melhoria contínua do agente
Ao simplificar a integração de RL, o Agent Lightning pode facilitar aos desenvolvedores a criação, a iteração e a implantação de agentes de alto desempenho. Planejamos expandir os recursos do Agent Lightning para incluir otimização automática de prompts e algoritmos RL adicionais.
A estrutura foi projetada para servir como uma plataforma aberta onde qualquer agente de IA pode melhorar por meio da prática do mundo actual. Ao unir os sistemas de agentes existentes com o aprendizado por reforço, o Agent Lightning visa ajudar a criar sistemas de IA que aprendem com a experiência e melhoram com o tempo.