 |
As organizações enfrentam um compromisso desafiador ao adaptar modelos de IA às suas necessidades comerciais específicas: contentar-se com modelos genéricos que produzam resultados médios ou enfrentar a complexidade e os custos da personalização avançada de modelos. As abordagens tradicionais forçam uma escolha entre o fraco desempenho com modelos mais pequenos ou os elevados custos de implementação de variantes de modelos maiores e de gestão de infraestruturas complexas. O ajuste fino de reforço é uma técnica avançada que treina modelos usando suggestions em vez de enormes conjuntos de dados rotulados, mas implementá-lo normalmente requer conhecimento especializado em ML, infraestrutura complicada e investimento significativo – sem garantia de alcançar a precisão necessária para casos de uso específicos.
Hoje, estamos anunciando o ajuste fino do reforço em Base Amazônicaum novo personalização do modelo capacidade que cria modelos mais inteligentes e econômicos que aprendem com o suggestions e fornecem resultados de maior qualidade para necessidades comerciais específicas. O ajuste fino do reforço usa uma abordagem orientada por suggestions, onde os modelos melhoram iterativamente com base em sinais de recompensa, proporcionando ganhos de precisão de 66%, em média, em relação aos modelos básicos.
O Amazon Bedrock automatiza o fluxo de trabalho de ajuste fino de reforço, tornando essa técnica avançada de personalização de modelos acessível para desenvolvedores comuns sem a necessidade de aprendizado de máquina (ML) experiência ou grandes conjuntos de dados rotulados.
Como funciona o ajuste fino do reforço
O ajuste fino do reforço é baseado em aprendizagem por reforço princípios para enfrentar um desafio comum: fazer com que os modelos produzam consistentemente resultados alinhados aos requisitos de negócios e às preferências do usuário.
Embora o ajuste fino tradicional exija conjuntos de dados grandes e rotulados e anotações humanas caras, o ajuste fino de reforço adota uma abordagem diferente. Em vez de aprender com exemplos fixos, utiliza funções de recompensa para avaliar e julgar quais respostas são consideradas boas para casos de uso de negócios específicos. Isso ensina os modelos a entender o que constitui uma resposta de qualidade sem exigir grandes quantidades de dados de treinamento pré-rotulados, tornando a personalização avançada de modelos no Amazon Bedrock mais acessível e econômica.
Aqui estão os benefícios de usar o ajuste fino de reforço no Amazon Bedrock:
- Facilidade de uso – O Amazon Bedrock automatiza grande parte da complexidade, tornando o ajuste fino do reforço mais acessível para desenvolvedores que criam aplicações de IA. Os modelos podem ser treinados usando logs de API existentes no Amazon Bedrock ou fazendo add de conjuntos de dados como dados de treinamento, eliminando a necessidade de conjuntos de dados rotulados ou configuração de infraestrutura.
- Melhor desempenho do modelo – O ajuste fino do reforço melhora a precisão do modelo em 66%, em média, em relação aos modelos básicos, permitindo a otimização de preço e desempenho por meio do treinamento de variantes de modelos menores, mais rápidas e mais eficientes. Isso funciona com Amazon Nova 2 Lite modelo, melhorando o desempenho de qualidade e preço para necessidades comerciais específicas, com suporte para modelos adicionais em breve.
- Segurança – Os dados permanecem no ambiente seguro da AWS durante todo o processo de personalização, mitigando questões de segurança e conformidade.
A capacidade suporta duas abordagens complementares para fornecer flexibilidade para otimizar modelos:
- Aprendizagem por Reforço com Recompensas Verificáveis (RLVR) usa avaliadores baseados em regras para tarefas objetivas, como geração de código ou raciocínio matemático.
- Aprendizagem por reforço com suggestions de IA (RLAIF) emprega juízes baseados em IA para tarefas subjetivas, como acompanhamento de instruções ou moderação de conteúdo.
Primeiros passos com ajuste fino de reforço no Amazon Bedrock
Vamos examinar a criação de um trabalho de ajuste fino de reforço.
Primeiro eu acesso o Console Amazon Bedrock. Então, eu navego até o Modelos personalizados página. eu escolho Criar e então escolha Trabalho de ajuste fino de reforço.
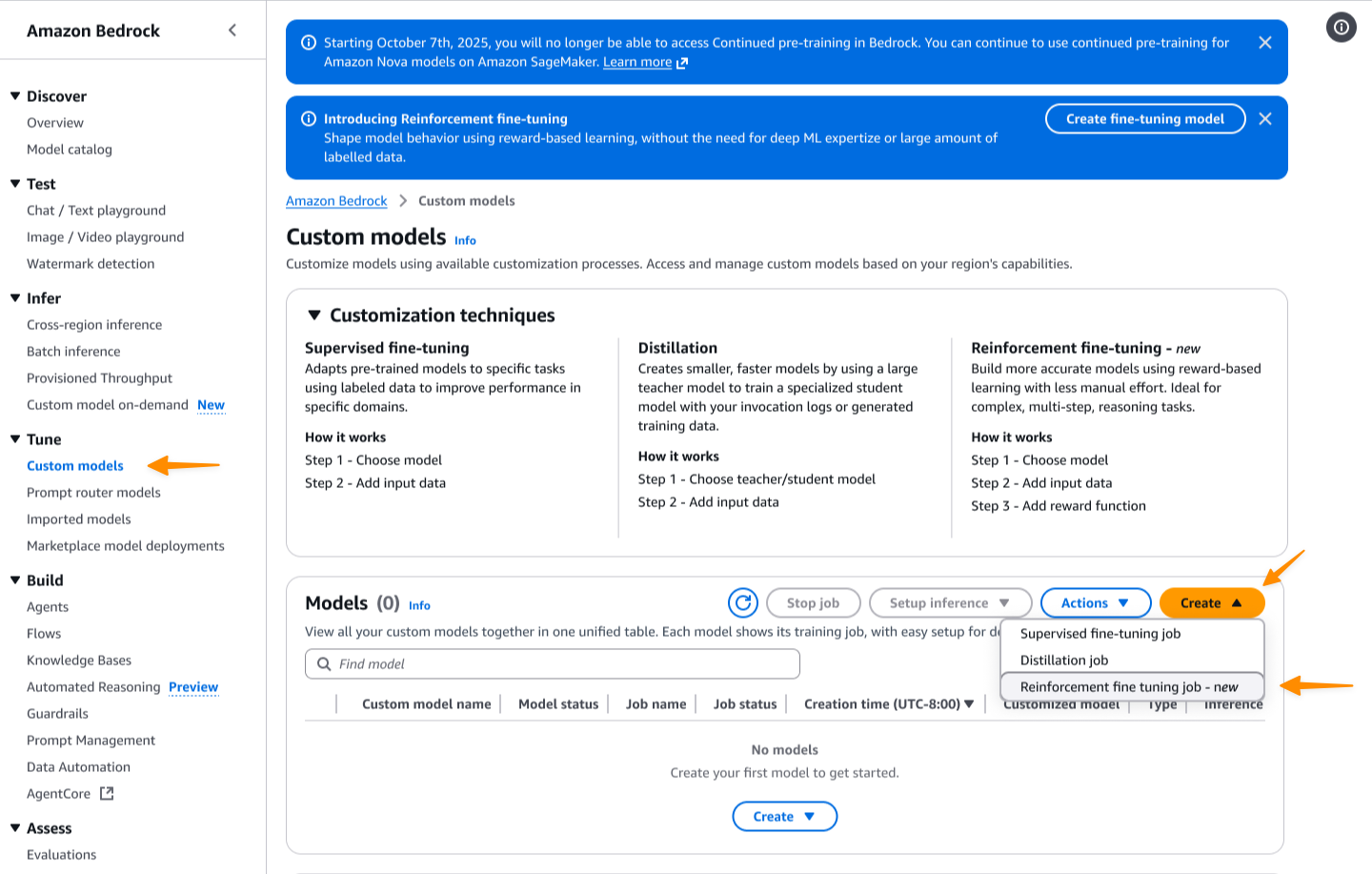
Começo inserindo o nome deste trabalho de customização e depois seleciono meu modelo base. No lançamento, o ajuste fino do reforço suporta Amazon Nova 2 Litecom suporte para modelos adicionais em breve.
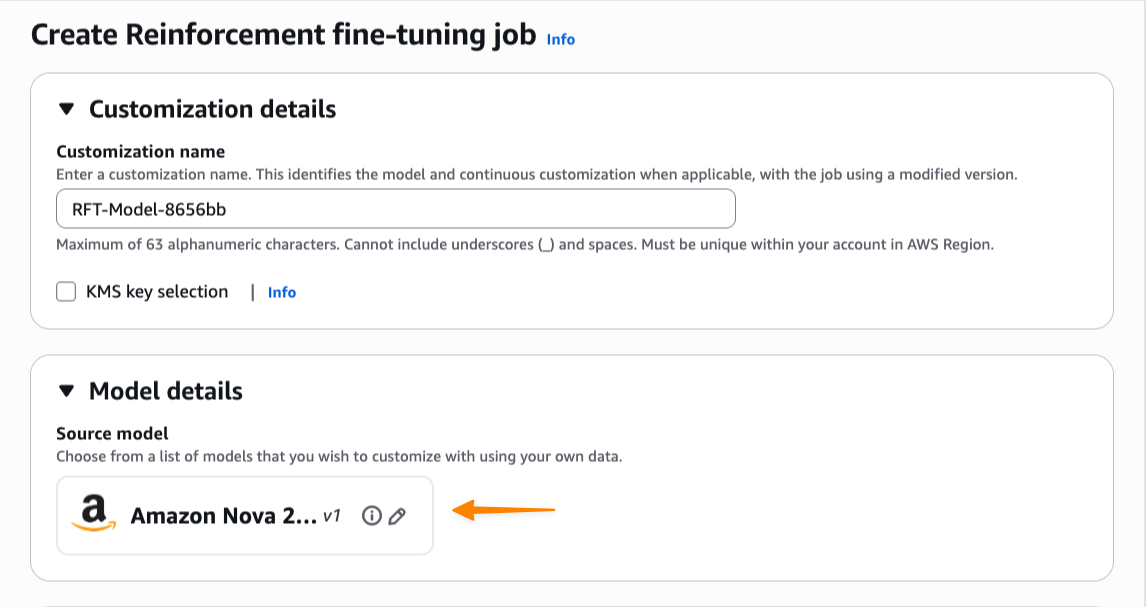
Em seguida, preciso fornecer dados de treinamento. Posso usar meus logs de invocação armazenados diretamente, eliminando a necessidade de fazer add de conjuntos de dados separados. Também posso fazer add de novos arquivos JSONL ou selecionar conjuntos de dados existentes em Serviço de armazenamento simples da Amazon (Amazon S3). O ajuste fino do reforço valida automaticamente meu conjunto de dados de treinamento e oferece suporte ao formato de dados OpenAI Chat Completions. Se eu fornecer logs de invocação no Amazon Bedrock invocar ou conversar formato, o Amazon Bedrock os converte automaticamente para o formato Chat Completions.
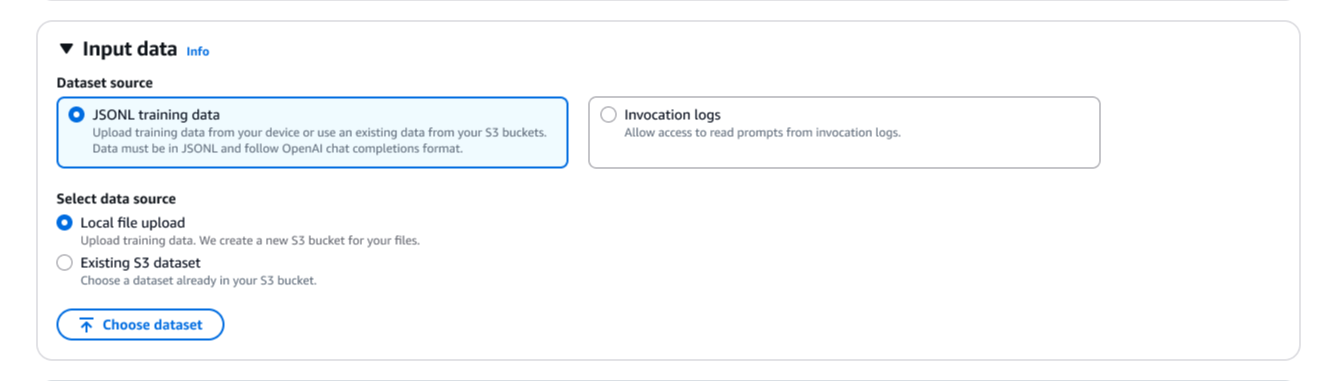
A configuração da função de recompensa é onde defino o que constitui uma boa resposta. Eu tenho duas opções aqui. Para tarefas objetivas, posso selecionar Código personalizado e escrever código Python personalizado que é executado por meio AWS Lambda funções. Para avaliações mais subjetivas, posso selecionar Modelo como juiz usar modelos de fundação (FMs) como juízes, fornecendo instruções de avaliação.
Aqui eu seleciono Código personalizadoe crio uma nova função Lambda ou uso uma existente como função de recompensa. Posso começar com um dos modelos fornecidos e personalizá-lo de acordo com minhas necessidades específicas.
Opcionalmente, posso modificar hiperparâmetros padrão, como taxa de aprendizagem, tamanho do lote e épocas.

Para maior segurança, posso definir configurações de nuvem privada digital (VPC) e Serviço de gerenciamento de chaves da AWS (AWS KMS) criptografia para atender aos requisitos de conformidade da minha organização. Então, eu escolho Criar para iniciar o trabalho de personalização do modelo.
Durante o processo de treinamento, posso monitorar métricas em tempo actual para entender como o modelo está aprendendo. O painel de métricas de treinamento mostra os principais indicadores de desempenho, incluindo pontuações de recompensa, curvas de perdas e melhorias de precisão ao longo do tempo. Essas métricas me ajudam a entender se o modelo está convergindo adequadamente e se a função de recompensa está orientando efetivamente o processo de aprendizagem.

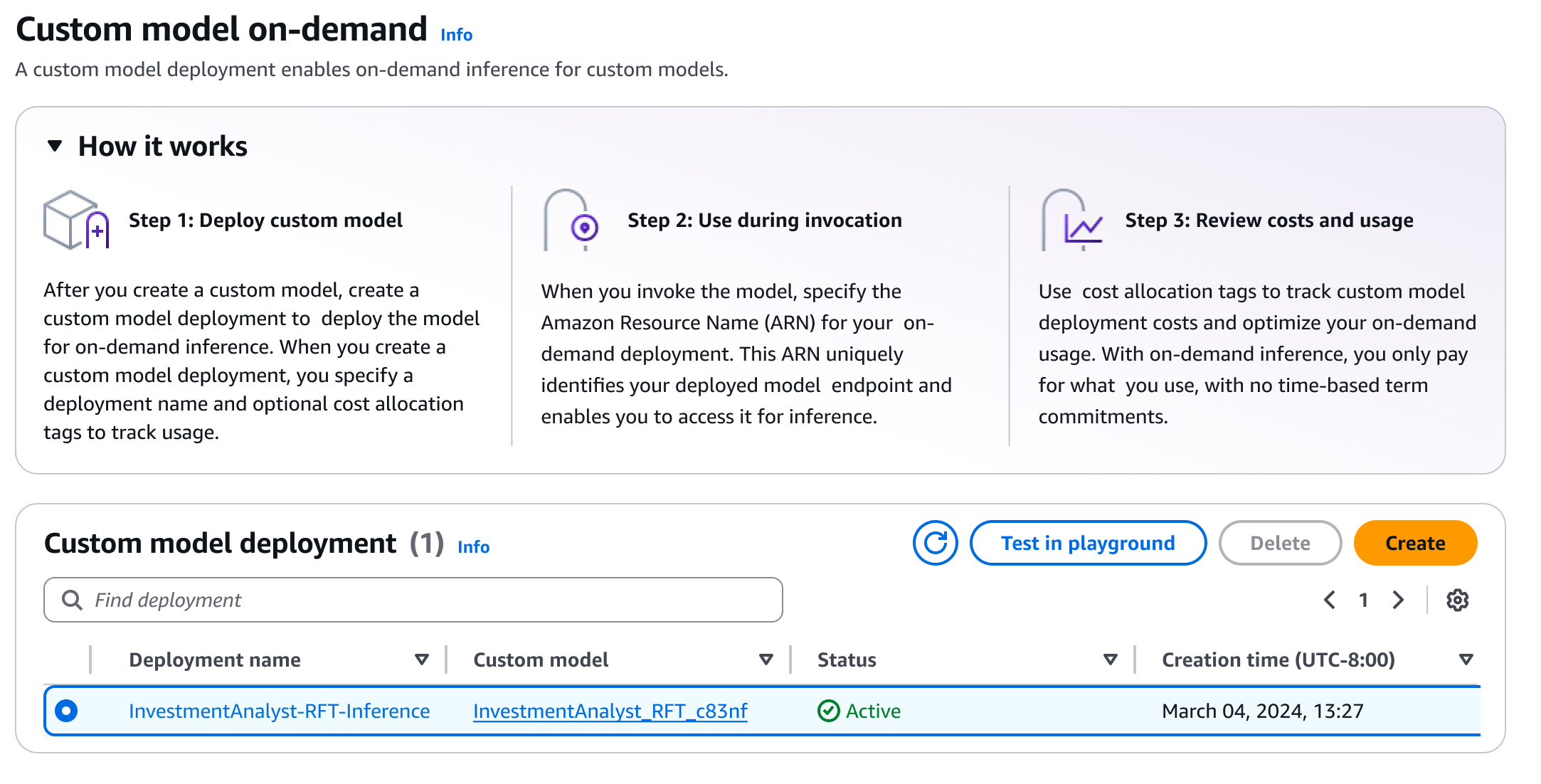
Quando o trabalho de ajuste fino do reforço for concluído, posso ver o standing remaining do trabalho no Detalhes do modelo página.
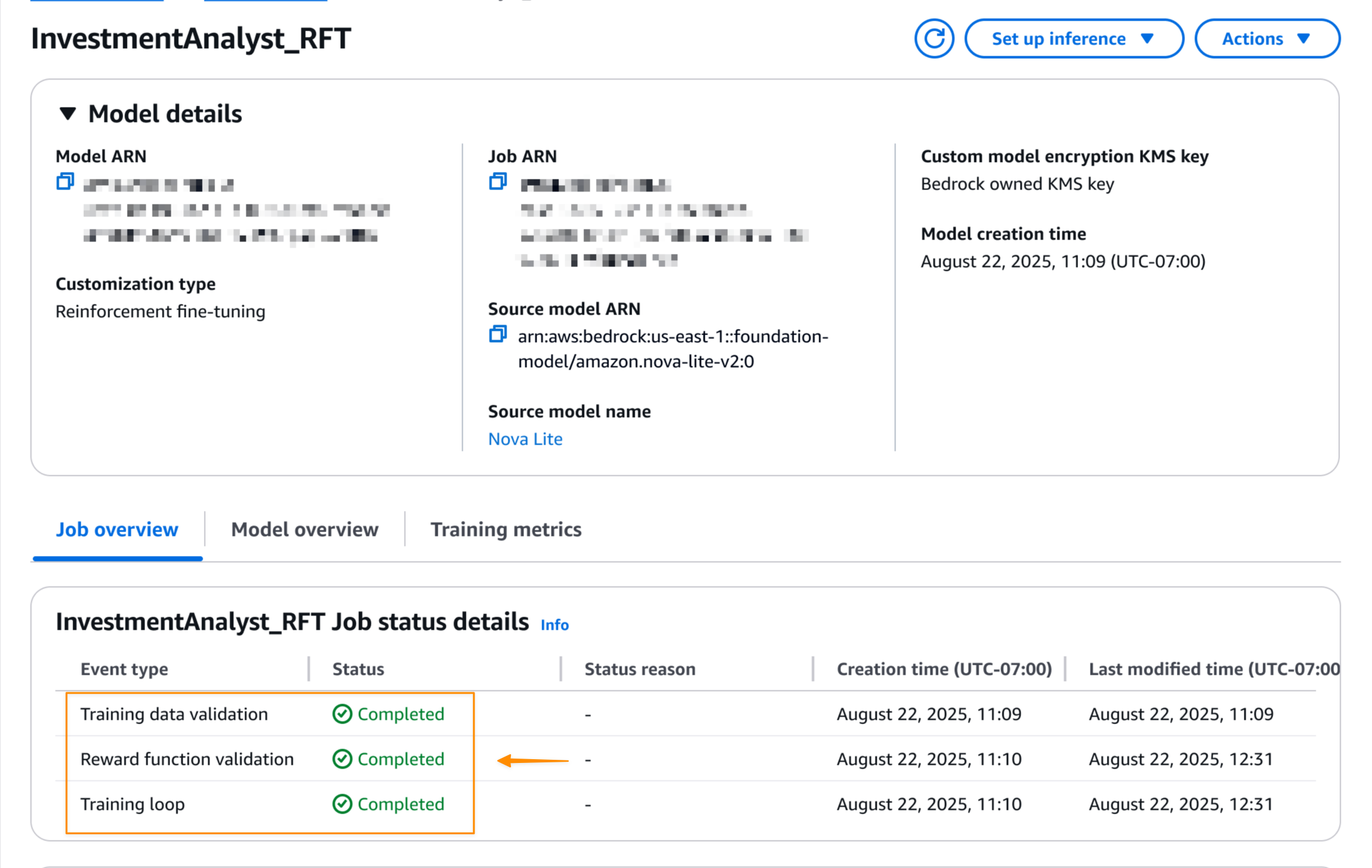
Assim que o trabalho for concluído, posso implantar o modelo com um único clique. eu seleciono Configurar inferênciae escolha Implantar sob demanda.
Aqui, forneço alguns detalhes do meu modelo.
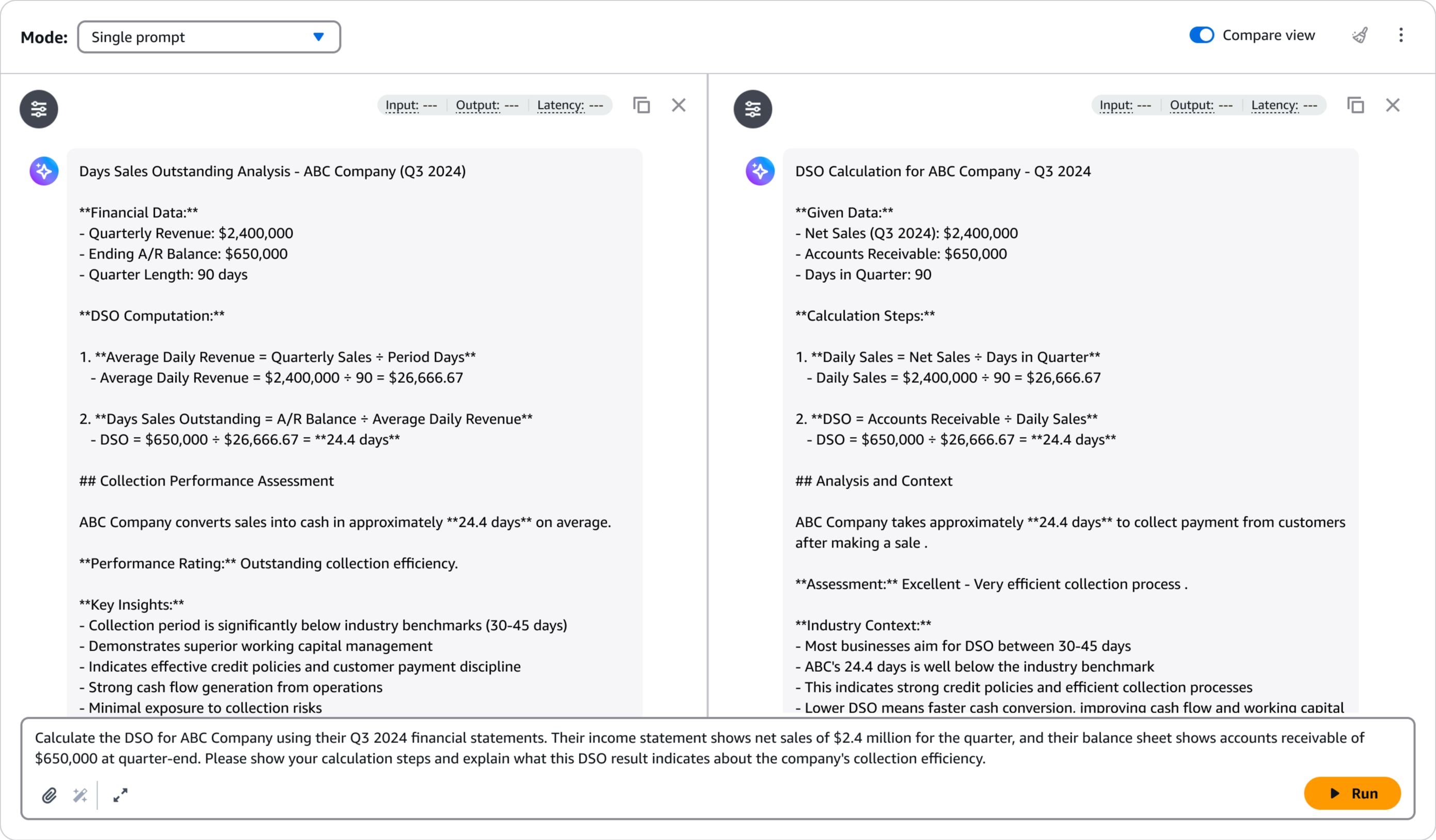
Após a implantação, posso avaliar rapidamente o desempenho do modelo usando o Amazon Bedrock Playground. Isso me ajuda a testar o modelo ajustado com prompts de amostra e comparar suas respostas com o modelo base para validar as melhorias. eu seleciono Teste no playground.
O playground fornece uma interface intuitiva para testes e iterações rápidas, ajudando-me a confirmar se o modelo atende aos meus requisitos de qualidade antes de integrá-lo aos aplicativos de produção.
Demonstração interativa
Saiba mais navegando em uma demonstração interativa de Ajuste fino do reforço Amazon Bedrock em ação.

Coisas adicionais para saber
Aqui estão os pontos principais a serem observados:
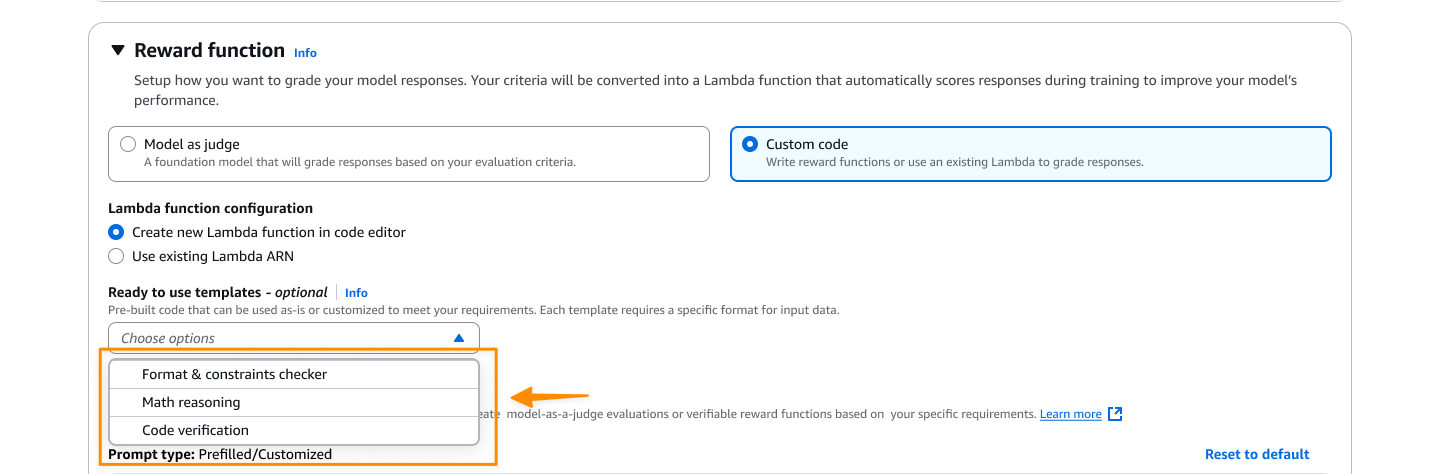
- Modelos — Existem sete modelos de funções de recompensa prontos para uso que cobrem casos de uso comuns para tarefas objetivas e subjetivas.
- Preços – Para saber mais sobre preços, consulte o Página de preços do Amazon Bedrock.
- Segurança – Os dados de treinamento e os modelos personalizados permanecem privados e não são usados para melhorar FMs para uso público. Ele oferece suporte à criptografia VPC e AWS KMS para maior segurança.
Comece com o ajuste fino do reforço visitando o documentação de ajuste fino de reforço e acessando o Console Amazon Bedrock.
Feliz edifício!
– Donnie