 |
Hoje, estamos anunciando dois novos recursos para Tabelas Amazon S3: suporte para a nova classe de armazenamento Clever-Tiering que otimiza automaticamente os custos com base em padrões de acesso e suporte de replicação para manter automaticamente a consistência Iceberg Apache réplicas de tabela em Regiões da AWS e contas sem sincronização guide.
As organizações que trabalham com dados tabulares enfrentam dois desafios comuns. Primeiro, eles precisam gerenciar manualmente os custos de armazenamento à medida que seus conjuntos de dados crescem e os padrões de acesso mudam ao longo do tempo. Em segundo lugar, ao manter réplicas de tabelas Iceberg em regiões ou contas, eles devem construir e manter arquiteturas complexas para rastrear atualizações, gerenciar a replicação de objetos e lidar com transformações de metadados.
Classe de armazenamento de camadas inteligentes do S3 Tables
Com a classe de armazenamento S3 Tables Clever-Tiering, os dados são automaticamente hierarquizados para o nível de acesso mais econômico com base em padrões de acesso. Os dados são armazenados em três níveis de baixa latência: Acesso Frequente, Acesso Infrequente (custo 40% menor que o Acesso Frequente) e Acesso Instantâneo de Arquivo (custo 68% menor em comparação com o Acesso Infrequente). Após 30 dias sem acesso, os dados passam para Acesso Infrequente e, após 90 dias, passam para Acesso Instantâneo de Arquivo. Isso acontece sem alterações em seus aplicativos ou impacto no desempenho.
As atividades de manutenção de tabelas, incluindo compactação, expiração de instantâneos e remoção de arquivos não referenciados, operam sem afetar as camadas de acesso aos dados. A compactação processa automaticamente apenas os dados na camada de acesso frequente, otimizando o desempenho dos dados consultados ativamente e, ao mesmo tempo, reduzindo os custos de manutenção ao ignorar arquivos mais frios nas camadas de custo mais baixo.
Por padrão, todas as tabelas existentes usam a classe de armazenamento Padrão. Ao criar novas tabelas, você pode especificar Clever-Tiering como a classe de armazenamento ou pode confiar na classe de armazenamento padrão configurada no nível do bucket de tabela. Você pode definir o Clever-Tiering como a classe de armazenamento padrão para seu bucket de tabela para armazenar automaticamente tabelas no Clever-Tiering quando nenhuma classe de armazenamento for especificada durante a criação.
Deixe-me mostrar como funciona
Você pode usar o Interface de linha de comando da AWS (AWS CLI) e o put-table-bucket-storage-class e get-table-bucket-storage-class comandos para alterar ou verificar o nível de armazenamento do seu bucket de tabela S3.
# Change the storage class
aws s3tables put-table-bucket-storage-class
--table-bucket-arn $TABLE_BUCKET_ARN
--storage-class-configuration storageClass=INTELLIGENT_TIERING
# Confirm the storage class
aws s3tables get-table-bucket-storage-class
--table-bucket-arn $TABLE_BUCKET_ARN
{ "storageClassConfiguration":
{
"storageClass": "INTELLIGENT_TIERING"
}
}Suporte à replicação de tabelas S3
O novo suporte à replicação do S3 Tables ajuda a manter réplicas de leitura consistentes de suas tabelas em regiões e contas da AWS. Você especifica o bucket da tabela de destino e o serviço cria tabelas de réplica somente leitura. Ele duplicate todas as atualizações cronologicamente, preservando os relacionamentos de instantâneos pai-filho. A replicação de tabelas ajuda a criar conjuntos de dados globais para minimizar a latência de consulta para equipes distribuídas geograficamente, atender aos requisitos de conformidade e fornecer proteção de dados.
Agora você pode criar facilmente tabelas de réplica que oferecem desempenho de consulta semelhante ao de suas tabelas de origem. As tabelas de réplica são atualizadas minutos após as atualizações da tabela de origem e oferecem suporte a políticas independentes de criptografia e retenção de suas tabelas de origem. As tabelas de réplica podem ser consultadas usando Estúdio unificado Amazon SageMaker ou qualquer motor compatível com Iceberg, incluindo PatoDB, Py Iceberg, Apache Faíscae Trino.
Você pode criar e manter réplicas de suas tabelas por meio do Console de gerenciamento da AWS ou APIs e SDKs da AWS. Você especifica um ou mais buckets de tabela de destino para replicar suas tabelas de origem. Quando você ativa a replicação, o S3 Tables cria automaticamente tabelas de réplica somente leitura nos buckets da tabela de destino, preenche-as com o estado mais recente da tabela de origem e monitora continuamente novas atualizações para manter as réplicas sincronizadas. Isso ajuda você a atender aos requisitos de viagem no tempo e auditoria, ao mesmo tempo que mantém diversas réplicas de seus dados.
Deixe-me mostrar como funciona
Para mostrar como funciona, procedo em três etapas. Primeiro, crio um bucket de tabela S3, crio uma tabela Iceberg e preencho-a com dados. Segundo, configuro a replicação. Terceiro, eu me conecto à tabela replicada e consulto os dados para mostrar que as alterações são replicadas.
Para esta demonstração, a equipe S3 gentilmente me deu acesso a um Amazon EMR cluster já provisionado. Você pode seguir a documentação do Amazon EMR para criar seu próprio cluster. Eles também criaram dois buckets de tabela S3, uma origem e um destino para a replicação. De novo, a documentação do S3 Tables ajudará você a começar.
Anoto os dois nomes de recursos da Amazon (ARNs) do bucket de tabelas S3. Nesta demonstração, me refiro a elas como variáveis de ambiente SOURCE_TABLE_ARN e DEST_TABLE_ARN.
Primeira etapa: preparar o banco de dados de origem
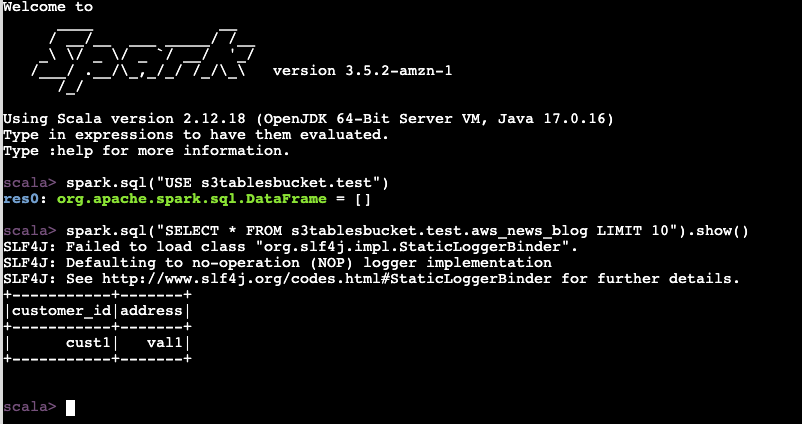
Eu inicio um terminal, conecto-me ao cluster EMR, inicio uma sessão Spark, crio uma tabela e insiro uma linha de dados. Os comandos que uso nesta demonstração estão documentados em Acessar tabelas usando o endpoint REST Iceberg do Amazon S3 Tables.
sudo spark-shell
--packages "org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,software program.amazon.awssdk:bundle:2.20.160,software program.amazon.awssdk:url-connection-client:2.20.160"
--master "native(*)"
--conf "spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions"
--conf "spark.sql.defaultCatalog=spark_catalog"
--conf "spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkCatalog"
--conf "spark.sql.catalog.spark_catalog.kind=relaxation"
--conf "spark.sql.catalog.spark_catalog.uri=https://s3tables.us-east-1.amazonaws.com/iceberg"
--conf "spark.sql.catalog.spark_catalog.warehouse=arn:aws:s3tables:us-east-1:012345678901:bucket/aws-news-blog-test"
--conf "spark.sql.catalog.spark_catalog.relaxation.sigv4-enabled=true"
--conf "spark.sql.catalog.spark_catalog.relaxation.signing-name=s3tables"
--conf "spark.sql.catalog.spark_catalog.relaxation.signing-region=us-east-1"
--conf "spark.sql.catalog.spark_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO"
--conf "spark.hadoop.fs.s3a.aws.credentials.supplier=org.apache.hadoop.fs.s3a.SimpleAWSCredentialProvider"
--conf "spark.sql.catalog.spark_catalog.rest-metrics-reporting-enabled=false"
spark.sql("""
CREATE TABLE s3tablesbucket.take a look at.aws_news_blog (
customer_id STRING,
tackle STRING
) USING iceberg
""")
spark.sql("INSERT INTO s3tablesbucket.take a look at.aws_news_blog VALUES ('cust1', 'val1')")
spark.sql("SELECT * FROM s3tablesbucket.take a look at.aws_news_blog LIMIT 10").present()
+-----------+-------+
|customer_id|tackle|
+-----------+-------+
| cust1| val1|
+-----------+-------+Até agora tudo bem.
Segunda etapa: configurar a replicação para tabelas S3
Agora, eu uso o CLI no meu laptop computer para configurar a replicação do bucket da tabela S3.
Antes de fazer isso, crio um AWS Identification and Entry Administration (IAM) política para autorizar o serviço de replicação a acessar meu bucket de tabela S3 e chaves de criptografia. Consulte a documentação de replicação do S3 Tables para obter detalhes. As permissões que usei para esta demonstração são:
{
"Model": "2012-10-17",
"Assertion": (
{
"Impact": "Enable",
"Motion": (
"s3:*",
"s3tables:*",
"kms:DescribeKey",
"kms:GenerateDataKey",
"kms:Decrypt"
),
"Useful resource": "*"
}
)
}Depois de criar esta política IAM, posso prosseguir e configurar a replicação:
aws s3tables-replication put-table-replication
--table-arn ${SOURCE_TABLE_ARN}
--configuration '{
"position": "arn:aws:iam:::position/S3TableReplicationManualTestingRole",
"guidelines":(
{
"locations": (
{
"destinationTableBucketARN": "${DST_TABLE_ARN}"
})
}
)
A replicação é iniciada automaticamente. As atualizações normalmente são replicadas em minutos. O tempo necessário para concluir depende do quantity de dados na tabela de origem.
Terceira etapa: Conecte-se à tabela replicada e consulte os dados
Agora, me conecto ao cluster do EMR novamente e inicio uma segunda sessão do Spark. Desta vez, uso a tabela de destino.
Para verificar se a replicação funciona, insiro uma segunda linha de dados na tabela de origem.
spark.sql("INSERT INTO s3tablesbucket.take a look at.aws_news_blog VALUES ('cust2', 'val2')")
Aguardo alguns minutos para que a replicação seja acionada. Acompanho o standing da replicação com o get-table-replication-status comando.
aws s3tables-replication get-table-replication-status
--table-arn ${SOURCE_TABLE_ARN}
{
"sourceTableArn": "arn:aws:s3tables:us-east-1:012345678901:bucket/manual-test/desk/e0fce724-b758-4ee6-85f7-ca8bce556b41",
"locations": (
{
"replicationStatus": "pending",
"destinationTableBucketArn": "arn:aws:s3tables:us-east-1:012345678901:bucket/manual-test-dst",
"destinationTableArn": "arn:aws:s3tables:us-east-1:012345678901:bucket/manual-test-dst/desk/5e3fb799-10dc-470d-a380-1a16d6716db0",
"lastSuccessfulReplicatedUpdate": {
"metadataLocation": "s3://e0fce724-b758-4ee6-8-i9tkzok34kum8fy6jpex5jn68cwf4use1b-s3alias/e0fce724-b758-4ee6-85f7-ca8bce556b41/metadata/00001-40a15eb3-d72d-43fe-a1cf-84b4b3934e4c.metadata.json",
"timestamp": "2025-11-14T12:58:18.140281+00:00"
}
}
)
}Quando o standing da replicação é exibido preparedeu me conecto ao cluster do EMR e consulto a tabela de destino. Sem surpresa, vejo a nova linha de dados.

Coisas adicionais para saber
Aqui estão alguns pontos adicionais aos quais você deve prestar atenção:
- A replicação para tabelas S3 oferece suporte aos formatos de tabela Apache Iceberg V2 e V3, proporcionando flexibilidade na escolha do formato de tabela.
- Você pode configurar a replicação no nível do bucket de tabela, simplificando a replicação de todas as tabelas desse bucket sem configurações de tabela individuais.
- Suas tabelas de réplica mantêm a classe de armazenamento escolhida para suas tabelas de destino, o que significa que você pode otimizar de acordo com suas necessidades específicas de custo e desempenho.
- Qualquer catálogo compatível com Iceberg pode consultar diretamente suas tabelas de réplica sem coordenação adicional – eles só precisam apontar para o native da tabela de réplica. Isso lhe dá flexibilidade na escolha de mecanismos e ferramentas de consulta.
Preço e disponibilidade
Você pode rastrear seu uso de armazenamento por nível de acesso por meio de Relatórios de uso e custos da AWS e Amazon CloudWatch métricas. Para monitoramento de replicação, AWS CloudTrail logs fornecem eventos para cada objeto replicado.
Não há custos adicionais para configurar o Clever-Tiering. Você paga apenas pelos custos de armazenamento em cada nível. Suas tabelas continuam funcionando como antes, com otimização automática de custos baseada em seus padrões de acesso.
Para replicação do S3 Tables, você paga as cobranças do S3 Tables pelo armazenamento na tabela de destino, pelas solicitações PUT de replicação, pelas atualizações de tabela (confirmações) e pelo monitoramento de objetos nos dados replicados. Para replicação de tabelas entre regiões, você também paga pela transferência de dados entre regiões do Amazon S3 para a região de destino com base no par de regiões.
Como de costume, consulte o Página de preços do Amazon S3 para os detalhes.
Ambos os recursos estão disponíveis hoje em todas as regiões da AWS onde Tabelas S3 são suportadas.
Para saber mais sobre esses novos recursos, visite o Documentação de tabelas do Amazon S3 ou experimente-os no Console Amazon S3 hoje. Compartilhe seu suggestions por meio do AWS re:Submit para Amazon S3 ou por meio de seus contatos do AWS Help.