Databricks oferece suporte ao Apache Iceberg v3 na plataforma de inteligência de dados, oferecendo aos clientes uma camada de dados unificada e aberta com o melhor desempenho, interoperabilidade e governança da categoria.
Com esta versão, os clientes que executam cargas de trabalho Iceberg agora podem aproveitar os recursos do Databricks, incluindo E/S Preditiva, Pipelines Declarativos Lakeflow Spark e simultaneidade em nível de linha, que aproveitam vetores de exclusão, linhagem em nível de linha e o tipo de dados Variant. Isso permite que as equipes executem cargas de trabalho modernas de maneira eficiente e consistente. Com o Unity Catalog, esses recursos funcionam perfeitamente nas tabelas Delta e Iceberg, permitindo a interoperabilidade sem reescrever dados.

Esta versão fortalece o compromisso da Databricks com padrões abertos e ajuda os clientes a desenvolver a base do lago Delta Lake, Apache Iceberg, Apache Parquet e Apache Spark, tudo com whole governança e flexibilidade.
Neste weblog, exploraremos:
- Uma camada de dados unificada com Iceberg v3
- Cargas de trabalho eficientes do Iceberg v3 no Databricks
- Avanço nos formatos de tabelas abertas
Uma camada de dados unificada com Iceberg v3
Delta Lake e Apache Iceberg tornaram-se a base do lakehouse moderno, cada um com fortes capacidades de confiabilidade, governança e gerenciamento de dados escalonável. Ambos usam arquivos de metadados para rastrear arquivos de dados Parquet e exclusões em nível de linha. No entanto, pequenas diferenças entre os formatos desses dados e arquivos excluídos muitas vezes forçaram as organizações a escolher um formato e seus recursos, geralmente com base na plataforma de dados que usam. Esta escolha period muitas vezes irreversível, uma vez que reescrever petabytes de dados é impraticável.
Iceberg v3 fecha essa lacuna. Ele apresenta recursos que se alinham estreitamente com Delta e com o ecossistema aberto mais amplo, como Parquet e Spark, permitindo que as equipes usem uma única cópia de dados com comportamento e desempenho consistentes em todos os formatos.
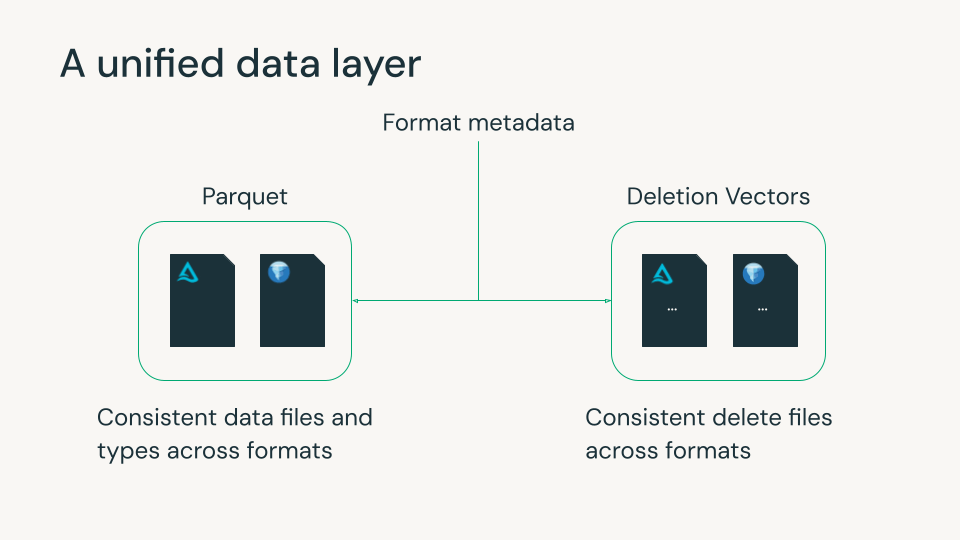
A Databricks acredita há muito tempo que o futuro da casa do lago é opcionalidade sem fragmentação. Nossas contribuições para o Iceberg v3 refletem esse compromisso: ajudar a unificar os principais comportamentos das tabelas para que os clientes possam usar os mecanismos e as ferramentas de sua preferência enquanto controlam tudo de forma consistente com o Unity Catalog.
Cargas de trabalho eficientes do Iceberg v3 no Databricks
Com o Iceberg v3, o Databricks traz os recursos da Plataforma de Inteligência de Dados para todas as tabelas gerenciadas do Unity Catalog.
Vetores de exclusão para atualizações mais rápidas com Predictive I/O
Os vetores de exclusão permitem excluir ou atualizar linhas sem reescrever arquivos Parquet. Em vez disso, as exclusões são armazenadas como arquivos separados e mescladas durante as leituras. A maioria das cargas de trabalho de engenharia de dados modifica apenas algumas linhas por vez, tornando esse um recurso crítico para gravações eficientes.

Com o Databricks, os clientes têm a melhor experiência de leitura e gravação com vetores de exclusão. Embora os vetores de exclusão melhorem o desempenho de gravação, eles adicionam uma penalidade de leitura para o mecanismo filtrar as linhas excluídas. O Databricks equilibra de forma inteligente o desempenho de leitura e gravação, aplicando e removendo vetores de exclusão conforme necessário usando E/S preditiva. Em comparação com as instruções MERGE clássicas, o Predictive I/O pode acelerar as atualizações em até 15x.
Os clientes também têm a flexibilidade de usar qualquer mecanismo com suas tabelas gerenciadas do Unity Catalog que possuem vetores de exclusão. Este é o poder dos padrões abertos: qualquer mecanismo nos ecossistemas Delta ou Iceberg pode ler e gravar nessas tabelas usando as APIs do Unity Catalog. Como observa Geodis:
“Agora que os vetores de exclusão chegaram ao Iceberg, podemos centralizar nosso conjunto de dados do Iceberg no Unity Catalog, aproveitando ao mesmo tempo o mecanismo de nossa escolha e mantendo o melhor desempenho da categoria.” — Delio Amato, arquiteto-chefe e diretor de dados, Geodis
Linhagem de linha para processamento incremental com Lakeflow Spark Declarative Pipelines
A linhagem de linha fornece a cada linha um ID exclusivo, facilitando o rastreamento de alterações ao longo do tempo. Isso significa que você processa apenas o que mudou em vez de reprocessar tudo, o que melhora a eficiência e reduz custos. A linhagem de linha está habilitada em todas as tabelas Iceberg v3.
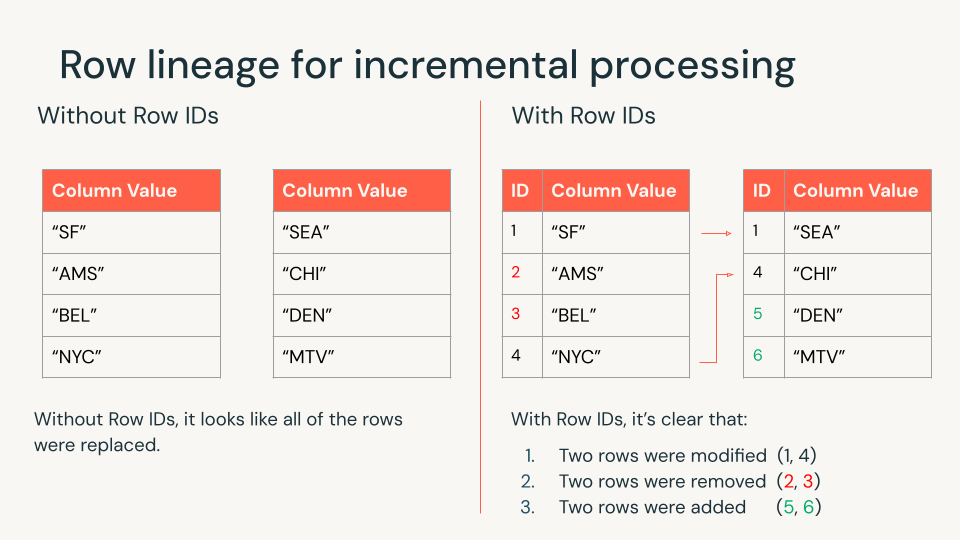
Databricks aproveita a linhagem de linhas para atualizações incrementais em toda a plataforma, usando Pipelines declarativos Lakeflow Spark para criar visualizações materializadas e tabelas de streaming, Vector Search, Lakehouse Monitoring e muito mais. Além disso, com vetores de exclusão e linhagem de linha, o Databricks pode reconciliar modificações simultâneas nos mesmos arquivos com simultaneidade em nível de linha. O Databricks continua sendo o único mecanismo lakehouse que traz esse recurso para abrir formatos de tabela.
Tipo de dados variante para ingestão flexível com o Auto Loader
Os dados modernos raramente cabem perfeitamente em linhas e colunas. Logs, eventos e dados de aplicativos geralmente chegam no formato JSON. O tipo de dados Variant armazena dados semiestruturados diretamente, oferecendo excelente desempenho sem a necessidade de esquemas complexos ou pipelines frágeis.

Usando o tipo de dados Variant no Databricks, você pode colocar dados JSON brutos diretamente em suas tabelas lakehouse usando funções de ingestão ou Carregador automático para processar incrementalmente arquivos de dados semiestruturados. Suportes variantes trituraçãoque extrai campos comuns em partes separadas para fornecer desempenho semelhante ao de colunas. Isso acelera consultas para BI, painéis e pipelines de alerta de baixa latência.
Variante funciona em Delta e Iceberg. Equipes que usam mecanismos diferentes podem consultar a mesma tabela, incluindo as colunas Variant, sem qualquer conversão ou perda de dados
“Já se foram os dias dos dados escalares simples, especialmente para casos de uso que exigiam segurança e logs de aplicativos. O Unity Catalog e o Iceberg v3 liberam o poder dos dados semiestruturados por meio do Variant e do processamento eficiente de dados por meio da linhagem de linhas. Isso permite interoperabilidade e coleta de log econômica em escala de petabytes.” — Russell Leighton, arquiteto-chefe, Panther
Avanço nos formatos de tabelas abertas
O Iceberg v3 marca um passo importante em direção à unificação dos formatos de tabelas abertas em toda a camada de dados. A próxima fronteira é melhorar a forma como os formatos gerenciam e sincronizam metadados em escala. Os esforços comunitários, como a árvore adaptativa de metadados introduzida pela primeira vez em a Cúpula do Icebergpode reduzir a sobrecarga de metadados e acelerar as operações de tabela em escala.
À medida que essas ideias amadurecem, elas aproximam as comunidades Delta e Iceberg, com objetivos compartilhados em torno de commits mais rápidos, gerenciamento eficiente de metadados e operações escalonáveis em várias mesas. A Databricks continua a contribuir para esta evolução, permitindo que os clientes obtenham desempenho e interoperabilidade sem serem limitados por diferenças de nível de formato.
Experimente o Iceberg v3 hoje com Databricks
Esses recursos do Iceberg v3 agora estão disponíveis no Databricks, fornecendo aos clientes a implementação do padrão mais abrangente e pronta para o futuro, apoiada pela governança e desempenho do Unity Catalog. Embora o ecossistema mais amplo adote a v3, o Databricks traz seu valor aos clientes imediatamente, liderando a adoção em todo o lago Delta e Iceberg tabelas.
Criar uma tabela gerenciada do Unity Catalog com Iceberg v3 é fácil:
Comece com Catálogo Unity e Iceberg v3 e junte-se a nós nos próximos Abra Lakehouse + IA eventos para saber mais sobre nosso trabalho em todo o ecossistema aberto.