Os LLMs não estão mais restritos a um formato de pergunta-resposta. Eles agora formam a base de aplicativos inteligentes que ajudam nos problemas do mundo actual em tempo actual. Nesse contexto, o Kimi K2 é um LLM de múltiplos fins que é imensamente standard entre os usuários de IA em todo o mundo. Enquanto todos conhecem suas poderosas capacidades agênticas, muitos não têm certeza de como ele se sai na API. Aqui, testamos Kimi K2 em um cenário de produção do mundo actual, através de um fluxo de trabalho baseado em API para avaliar se Kimi K2 mantém sua promessa de um grande LLM.
Leia também: Deseja encontrar o melhor sistema de código aberto? Leia nossa revisão de comparação entre Kimi K2 e Llama 4 aqui.
O que é Kimi K2?
Kimi K2 é um modelo de grande idioma de código aberto de última geração construído pela Moonshot AI. Emprega um Arquitetura da mistura de especialistas (MOE) e possui 1 trilhão de parâmetros totais (32 bilhões de atividades por token). O Kimi K2 incorpora particularmente os casos de uso de visão de futuro para inteligência agêntica avançada. É capaz não apenas de gerar e entender a linguagem pure, mas também de resolver problemas complexos autonomamente, utilizar ferramentas e concluir tarefas de várias etapas em uma ampla gama de domínios. Cobrimos tudo sobre sua referência, desempenho e pontos de acesso em detalhes em um artigo anterior: Kimi K2 O melhor modelo agêntico de código aberto.
Variantes de modelo
Existem duas variantes de Kimi K2:
- Kimi-K2-BASE: O modelo nua, um ótimo ponto de partida para pesquisadores e construtores que desejam ter controle complete sobre soluções de ajuste fino e personalizadas.
- Kimi-K2-Instruct: O modelo pós-treino que é melhor para uma experiência de chat de uso geral e de uso geral e agêntica. É um modelo de nível reflexo sem pensamento profundo.

Mecanismo da mistura de especialistas (MOE)
Computação fracionária: O Kimi K2 não ativa todos os parâmetros para cada entrada. Em vez disso, o Kimi K2 rotina todos os token para 8 de seus 384 “especialistas” especializados (mais um especialista compartilhado), que oferece uma diminuição significativa na computação por inferência em comparação com o modelo MOE e os modelos densos de tamanho comparável.
Especialização especializada: Cada especialista dentro do MOE é especializado em diferentes domínios de conhecimento ou padrões de raciocínio, levando a resultados ricos e eficientes.
Roteamento esparso: A Kimi K2 utiliza o Gating Good para rotear especialistas relevantes para cada token, que suporta enorme capacidade e inferência computacionalmente viável.
Atenção e contexto
Janela de contexto massiva: Kimi K2 tem um comprimento de contexto de até 128.000 tokens. Ele pode processar documentos ou bases de código extremamente longas em um único passe, uma janela de contexto sem precedentes, excedendo muito a maioria dos LLMs Legacy.
Atenção complexa: O modelo possui 64 cabeças de atenção por camada, permitindo rastrear e aproveitar relacionamentos e dependências complicadas em toda a sequência de tokens, normalmente até 128.000.
Treinando inovações
Otimizador Muonclip: Para permitir treinamento estável nessa escala sem precedentes, a Moonshot AI desenvolveu um novo otimizador chamado MuOnClip. Ele limita a escala das logits de atenção, redimensionando as matrizes de consulta e peso-chave em cada atualização para evitar a instabilidade extrema (isto é, valores explosivos) comuns em modelos em larga escala.
Escala de dados: Kimi K2 foi pré-treinado em 15,5 trilhões de tokens, que desenvolve o conhecimento e a capacidade de generalizar do modelo.
Como acessar Kimi K2?
Como mencionado, Kimi K2 pode ser acessado de duas maneiras:
Interface da Net/Aplicativo: Kimi pode ser acessado instantaneamente para uso do Chat da internet oficial.
API: O Kimi K2 pode ser integrado ao seu código usando a API junto ou a API da Moonshot, suportando fluxos de trabalho Agentic e o uso de ferramentas.
Passos para obter uma chave da API
Para executar o Kimi K2 através de uma API, você precisará de uma chave da API. Aqui está como obtê -lo:
API da lua:
- Inscreva -se ou faça login no console de desenvolvedores de IA da lua.
- Vá para a seção “API Keys”.
- Clique em “Criar chave da API”, forneça um nome e projeto (ou deixe como padrão) e salve sua chave para uso.
Juntos API AI:
- Registre -se ou faça login em AI juntos.
- Localize a área de “chaves da API” no seu painel.
- Gere uma nova chave e grave -a para uso posterior.
Instalação native
Faça o obtain dos pesos de Hugging Face ou Github e execute-os localmente com VLLM, Tensorrt-llm ou Sglang. Simplesmente siga estas etapas.
Etapa 1: Crie um ambiente Python
Usando conda:
conda create -n kimi-k2 python=3.10 -y
conda activate kimi-k2Usando Venv:
python3 -m venv kimi-k2
supply kimi-k2/bin/activateEtapa 2: Instale as bibliotecas necessárias
Para todos os métodos:
pip set up torch transformers huggingface_hubvllm:
pip set up vllmTensorrt-llm:
Siga a documentação oficial (Tensorrt-llm de instalação) (requer pytorch> = 2.2 e cuda == 12.x; não o PIP instalável para todos os sistemas).
Para Sglang:
pip set up sglangEtapa 3: Baixe os pesos do modelo
De abraçar o rosto:
Com git-lfs:
git lfs set up
git clone https://huggingface.co/moonshot-ai/Kimi-K2-InstructOu usando huggingface_hub:
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="moonshot-ai/Kimi-K2-Instruct",
local_dir="./Kimi-K2-Instruct",
local_dir_use_symlinks=False,
)Etapa 4: Verifique seu ambiente
Para garantir CUDA, Pytorch e as dependências estão prontas:
import torch
import transformers
print(f"CUDA Accessible: {torch.cuda.is_available()}")
print(f"CUDA Units: {torch.cuda.device_count()}")
print(f"CUDA Model: {torch.model.cuda}")
print(f"Transformers Model: {transformers.__version__}")Etapa 5: Execute Kimi K2 com seu again -end preferido
Com vllm:
python -m vllm.entrypoints.openai.api_server
--model ./Kimi-K2-Instruct
--swap-space 512
--tensor-parallel-size 2
--dtype float16Ajuste o tamanho tensor-paralelo e o DTYPE com base no seu {hardware}. Substitua por pesos quantizados se estiver usando variantes INT8 ou 4 bits.
Prática com kimi k2
Neste exercício, daremos uma olhada em como os grandes modelos de idiomas, como o Kimi K2, funcionam na vida actual com chamadas reais de API. O objetivo é testar sua eficácia em movimento e ver se fornece um desempenho forte.
Tarefa 1: Criando um gerador de relatório de 360 ° usando Langgraph e Kimi K2:
Nesta tarefa, criaremos um gerador de relatório de 360 graus usando o Langgraph Framework e o Kimi K2 LLM. O aplicativo é uma vitrine de como os fluxos de trabalho agênticos podem ser coreografados para recuperar, processar e resumir informações automaticamente através do uso de interações da API.
Hyperlink de código: https://github.com/sjsoumil/tutorials/blob/important/kimi_k2_hands_on.py
Saída de código:
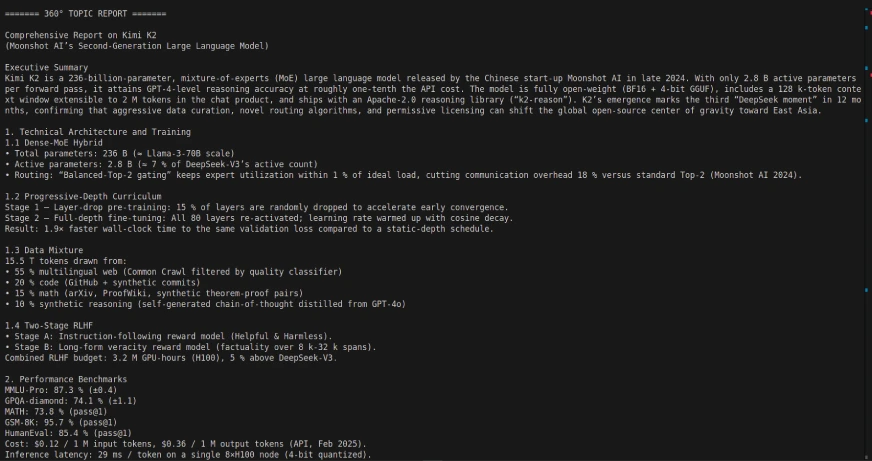
Empregar a Kimi K2 com Langgraph pode permitir um poderoso fluxo de trabalho agêntico, de várias etapas, como Kimi K2 foi projetado para decompor autonomamente tarefas de várias etapas, como consultas, relatórios e processamento de documentos de banco de dados, usando integrações de ferramentas/API. Apenas modele suas expectativas para alguns dos tempos de resposta.
Tarefa 2: Criando um chatbot simples usando Kimi K2
Código:
from dotenv import load_dotenv
import os
from openai import OpenAI
load_dotenv()
OPENROUTER_API_KEY = os.getenv("OPENROUTER_API_KEY")
if not OPENROUTER_API_KEY:
elevate EnvironmentError("Please set your OPENROUTER_API_KEY in your .env file.")
consumer = OpenAI(
api_key=OPENROUTER_API_KEY,
base_url="https://openrouter.ai/api/v1"
)
def kimi_k2_chat(messages, mannequin="moonshotai/kimi-k2:free", temperature=0.3, max_tokens=1000):
response = consumer.chat.completions.create(
mannequin=mannequin,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
)
return response.decisions(0).message.content material
# Dialog loop
if __name__ == "__main__":
historical past = ()
print("Welcome to the Kimi K2 Chatbot (sort 'exit' to stop)")
whereas True:
user_input = enter("You: ")
if user_input.decrease() == "exit":
break
historical past.append({"position": "consumer", "content material": user_input})
reply = kimi_k2_chat(historical past)
print("Kimi:", reply)
historical past.append({"position": "assistant", "content material": reply})Saída:
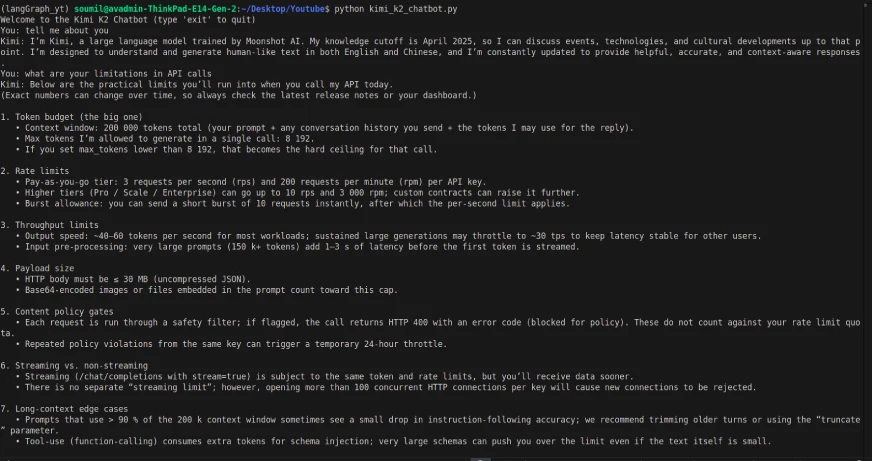
Apesar do modelo ser multimodal, as chamadas da API só tinham a capacidade de fornecer entrada/saída baseada em texto (e a entrada de texto teve um atraso). Portanto, a interface e a chamada da API agem de maneira um pouco diferente.
Minha resenha depois da prática
O Kimi K2 é um modelo de idioma de código aberto e grande, o que significa que é gratuito, e isso é uma grande vantagem para desenvolvedores e pesquisadores. Para este exercício, acessei o Kimi K2 com uma chave da API do OpenRouter. Embora eu tenha acessado o modelo anteriormente através da interface da internet fácil de usar, preferia usar a API para obter mais flexibilidade e criar um fluxo de trabalho agêntico personalizado no Langgraph.
Durante o teste do chatbot, os tempos de resposta que experimentei com as chamadas da API foram visivelmente atrasados, e o modelo ainda não pode suportar recursos multimodais (por exemplo, processamento de imagem ou arquivo) através da API como pode na interface. Independentemente disso, o modelo funcionou bem com o Langgraph, o que me permitiu projetar um pipeline completo para gerar relatórios dinâmicos de 360 °.
Embora não fosse destruidor de terra, ilustra como Modelos de código aberto estão rapidamente alcançando os líderes proprietários, como Openai e Gêmeos, e eles continuarão fechando as lacunas com modelos como Kimi K2. É um desempenho e flexibilidade impressionantes para um modelo gratuito, e mostra que a barra está aumentando mais de recursos multimodais com LLMs que são de código aberto.
Conclusão
Kimi K2 é uma ótima opção no cenário de código aberto LLM, especialmente para fluxos de trabalho agênticos e facilidade de integração. Enquanto tivemos algumas limitações, como tempos de resposta mais lentos by way of API e falta de suporte à multimodalidade, ela fornece um ótimo lugar para começar a desenvolver aplicações inteligentes no mundo actual. Além disso, não ter que pagar por esses recursos é uma enorme vantagem que ajuda desenvolvedores, pesquisadores e startups. À medida que o ecossistema evolui e amadurece, veremos modelos como Kimi K2 obtendo recursos avançados rapidamente, quando eles rapidamente fecham a lacuna com empresas proprietárias. No geral, se você está pensando em LLMs de código aberto para uso da produção, o Kimi K2 é uma opção possível que vale o seu tempo e experimentação.
Perguntas frequentes
A. Kimi K2 é o modelo de linguagem de grande geração da próxima geração da lua ai (MOE) com 1 trilhão de parâmetros totais (32 bilhões de parâmetros ativados por interação). Ele foi projetado para tarefas agênticas, raciocínio avançado, geração de código e uso de ferramentas.
– Geração avançada de código e depuração
– Execução automatizada de tarefas agênticas
-Raciocínio e resolução de problemas complexos e de várias etapas
– Análise e visualização de dados
– Planejamento, assistência à pesquisa e criação de conteúdo
– Arquitetura: Transformador da mistura de especialistas
– Parâmetros totais: 1T (trilhão)
– Parâmetros ativados: 32b (bilhão) para cada consulta
– Duração do contexto: Até 128.000 tokens
– Especialização: Uso da ferramenta, fluxos de trabalho agênticos, codificação, processamento de sequência longa
– Acesso API: Disponível no Console da API da Moonshot AI (e também suportado de AI e OpenRouter)
– Implantação native: Possível localmente; requer {hardware} native poderoso normalmente (para uso eficaz requer múltiplas GPUs de ponta)
– Variantes de modelo: Lançado como “Kimi-K2-Base” (para personalização/ajuste fino) e “Kimi-K2-Instruct” (para bate-papo de uso geral, interações agênticas).
A. Kimi K2 normalmente é igual ou excede, os principais modelos de código aberto (por exemplo, Deepseek V3, Qwen 2.5). É competitivo com modelos proprietários em benchmarks para tarefas de codificação, raciocínio e agitação. Também é notavelmente eficiente e de baixo custo em comparação com outros modelos de escala semelhante ou menor!
Cientista de dados | AWS Licensed Options Architect | Ai & ML Innovator
Como cientista de dados da Analytics Vidhya, especializo-me em aprendizado de máquina, aprendizado profundo e soluções orientadas a IA, alavancando a PNL, visão computacional e tecnologias em nuvem para criar aplicativos escaláveis.
Com um B.Tech em ciência da computação (ciência de dados) da VIT e certificações como arquiteto e tensorflow de soluções certificadas da AWS, meu trabalho abrange IA generativa, detecção de anomalias, detecção de notícias falsas e reconhecimento de emoções. Apaixonado pela inovação, eu me esforço para desenvolver sistemas inteligentes que moldem o futuro da IA.
Faça login para continuar lendo e desfrutar de conteúdo com curado especialista.