O desafio das aplicações de dados de produção
Criar aplicativos de dados prontos para produção é complexo. Freqüentemente, você precisa de ferramentas separadas para hospedar o aplicativo, gerenciar o banco de dados e mover dados entre sistemas. Cada camada adiciona sobrecarga de configuração, manutenção e implantação.
Databricks simplifica isso consolidando tudo em uma única plataforma – o Plataforma de inteligência de dados Databricks. Aplicativos de blocos de dados executa seus aplicativos da internet em computação sem servidor. Base do lago fornece um banco de dados Postgres gerenciado que sincroniza com Catálogo de Unidadedando ao seu aplicativo acesso rápido a dados controlados. E com Pacotes de ativos do Databricks (DABs)você pode empacotar código, infraestrutura e pipelines de dados e implantá-los com um único comando.
Este weblog mostra como essas três peças funcionam juntas para construir e implantar um aplicativo de dados actual, desde a sincronização de dados do Unity Catalog com Lakebase, até a execução de um aplicativo internet em Databricks e automatização da implantação com Asset Bundles.
Arquitetura e como funciona
Examinaremos um aplicativo de viagem de táxi que demonstra todo o padrão: um aplicativo React e FastAPI que lê tabelas sincronizadas do Lakebase, com atualizações automáticas de dados das tabelas Delta do Unity Catalog acontecendo em segundos.
O diagrama a seguir fornece uma visão simplificada da arquitetura da solução:

Em alto nível, o Databricks Apps serve como front-end onde os usuários exploram e visualizam dados. Lakebase fornece o banco de dados Postgres que o aplicativo consulta, mantendo-o próximo dos dados ativos do Unity Catalog com tabelas sincronizadas. Os Databricks Asset Bundles unem tudo definindo e implantando todos os recursos – aplicativo, banco de dados e sincronização de dados – como uma unidade controlada por versão.
Principais componentes da solução:
O aplicativo de exemplo exibe viagens recentes de táxi em formato de tabela e gráfico e pesquisa automaticamente novas viagens. Ele lê dados de uma tabela sincronizada do Lakebase, que espelha uma tabela Delta no Unity Catalog.
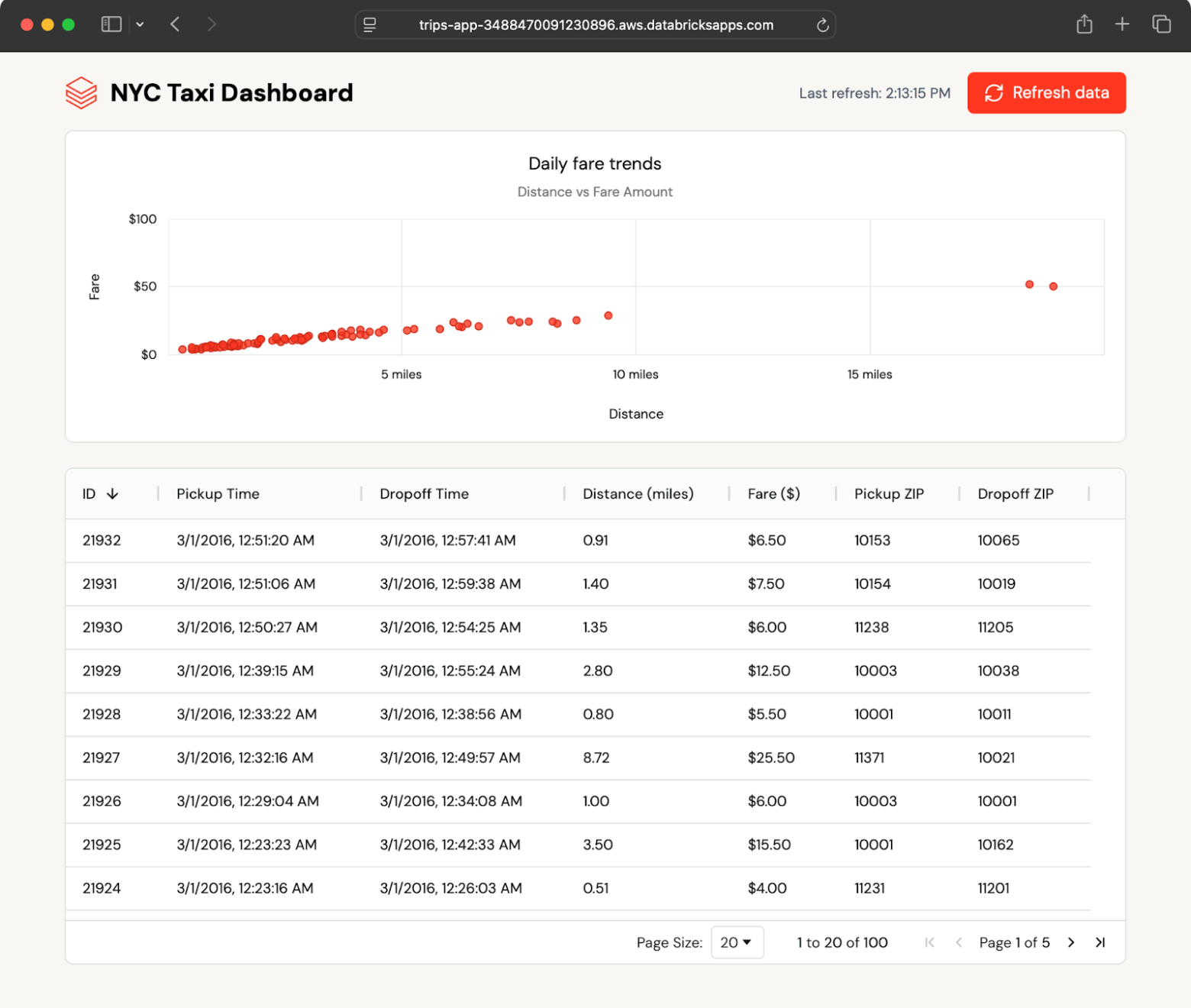
Como a tabela sincronizada é atualizada automaticamente, qualquer alteração na tabela do Catálogo do Unity aparece no aplicativo em segundos, sem necessidade de ETL personalizado.
Você pode testar isso inserindo novos dados na tabela Delta de origem e atualizando a tabela sincronizada:
Em seguida, acione uma atualização da tabela trips_synced sincronizada.
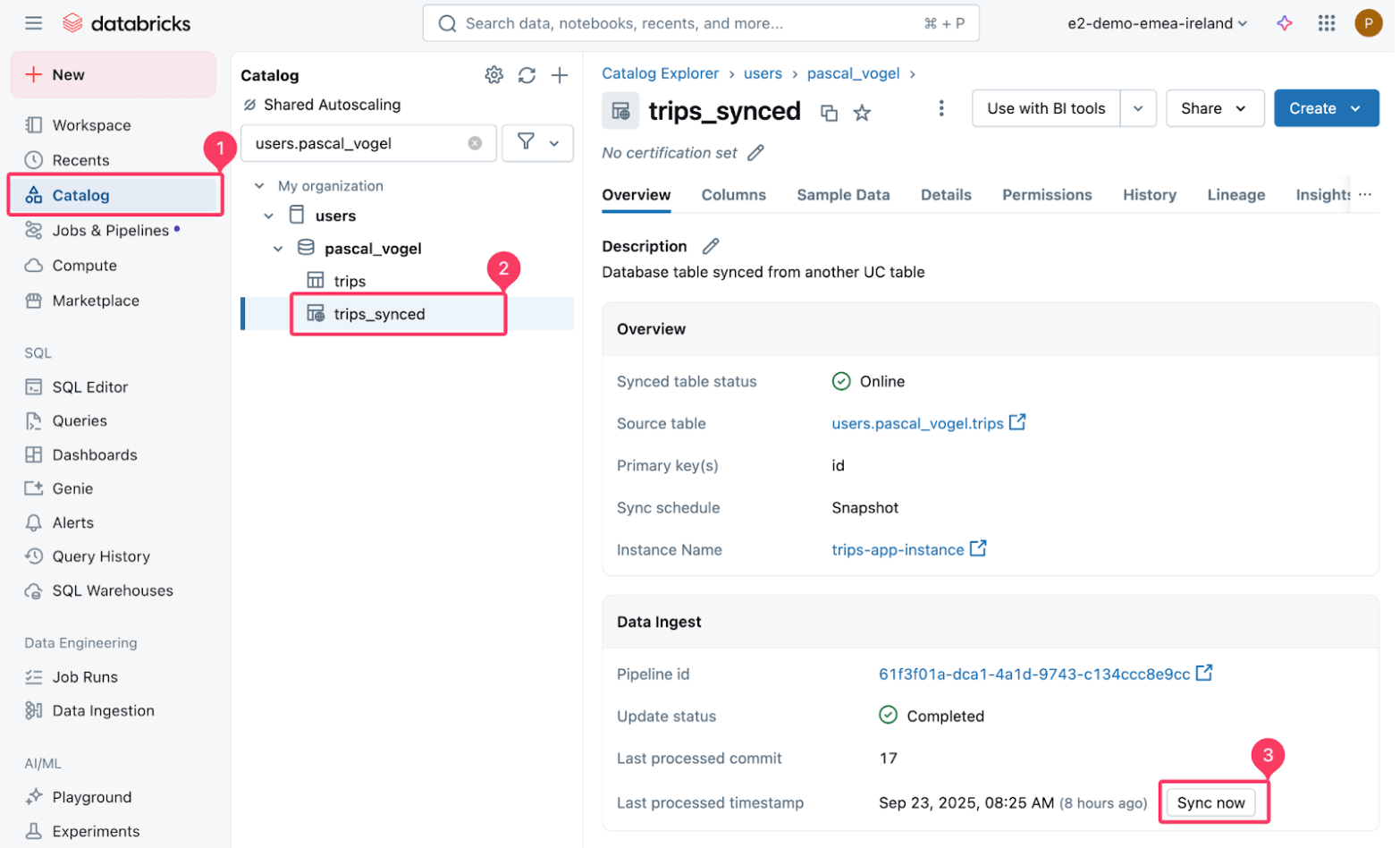
O pipeline gerenciado que alimenta a sincronização executa uma cópia instantânea da tabela Delta de origem para a tabela Postgres de destino.
Dentro de alguns segundos, os novos registros aparecem no painel. O aplicativo pesquisa atualizações e permite que os usuários atualizem sob demanda, mostrando como o Lakebase mantém os dados operacionais atualizados sem engenharia additional.
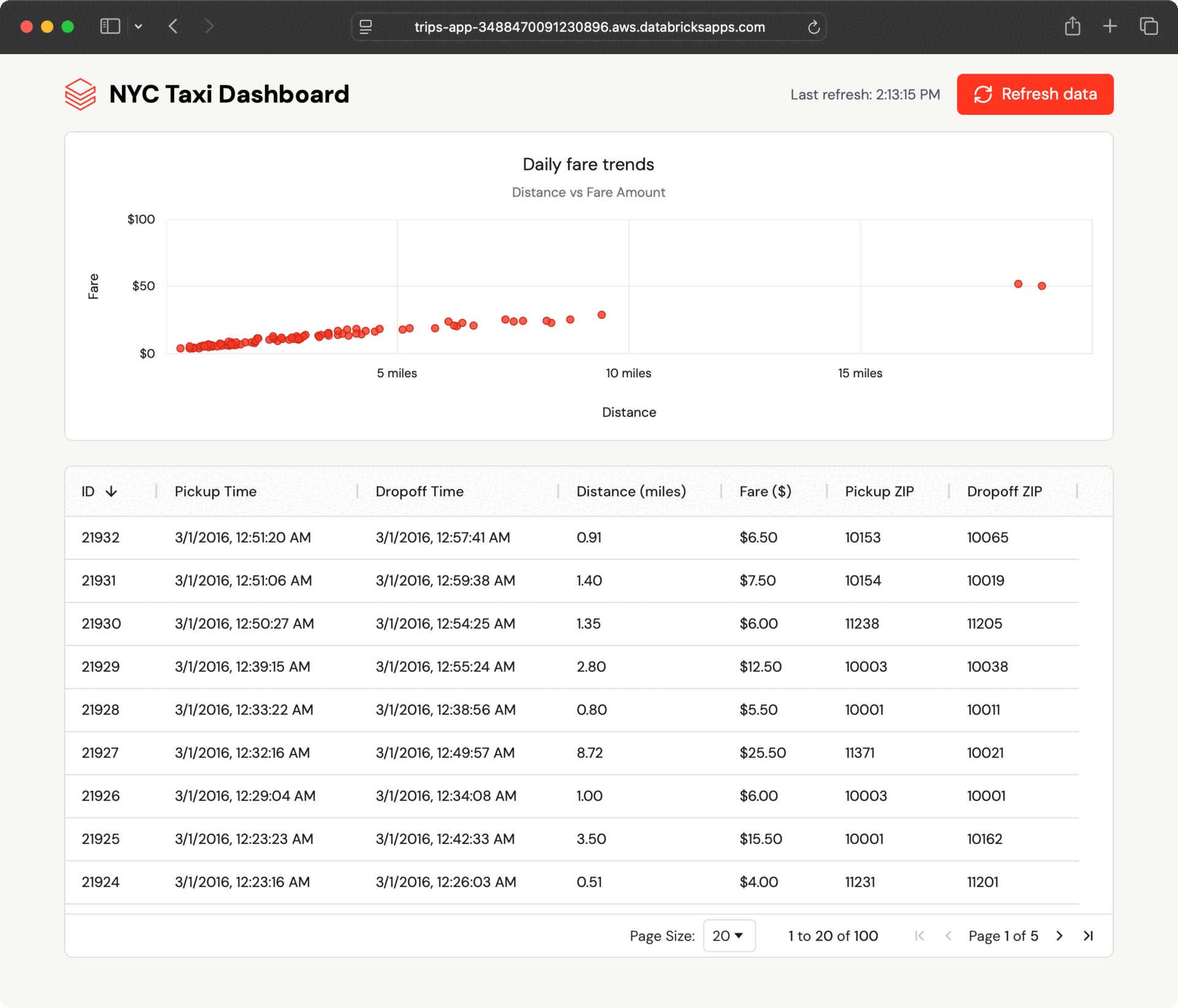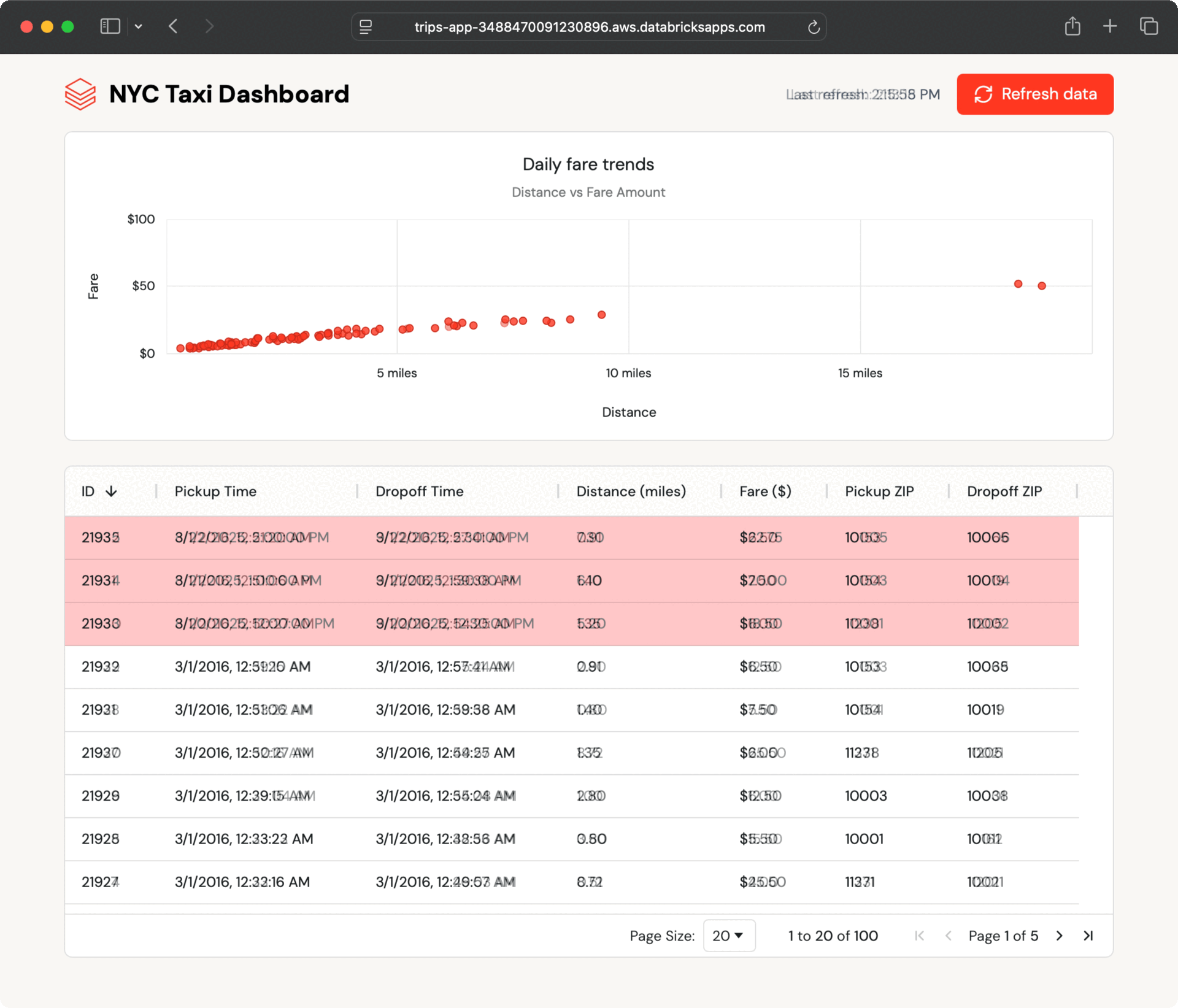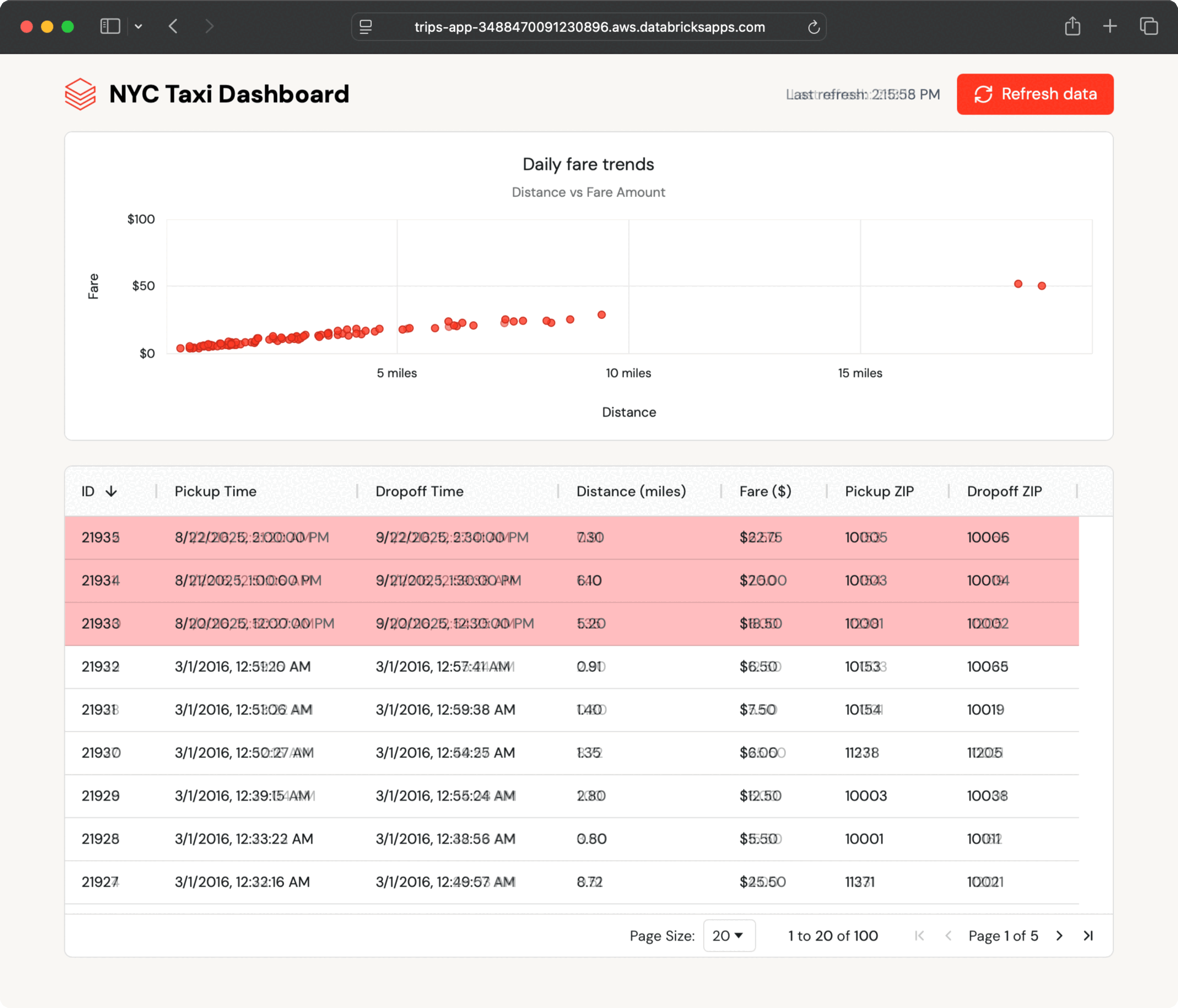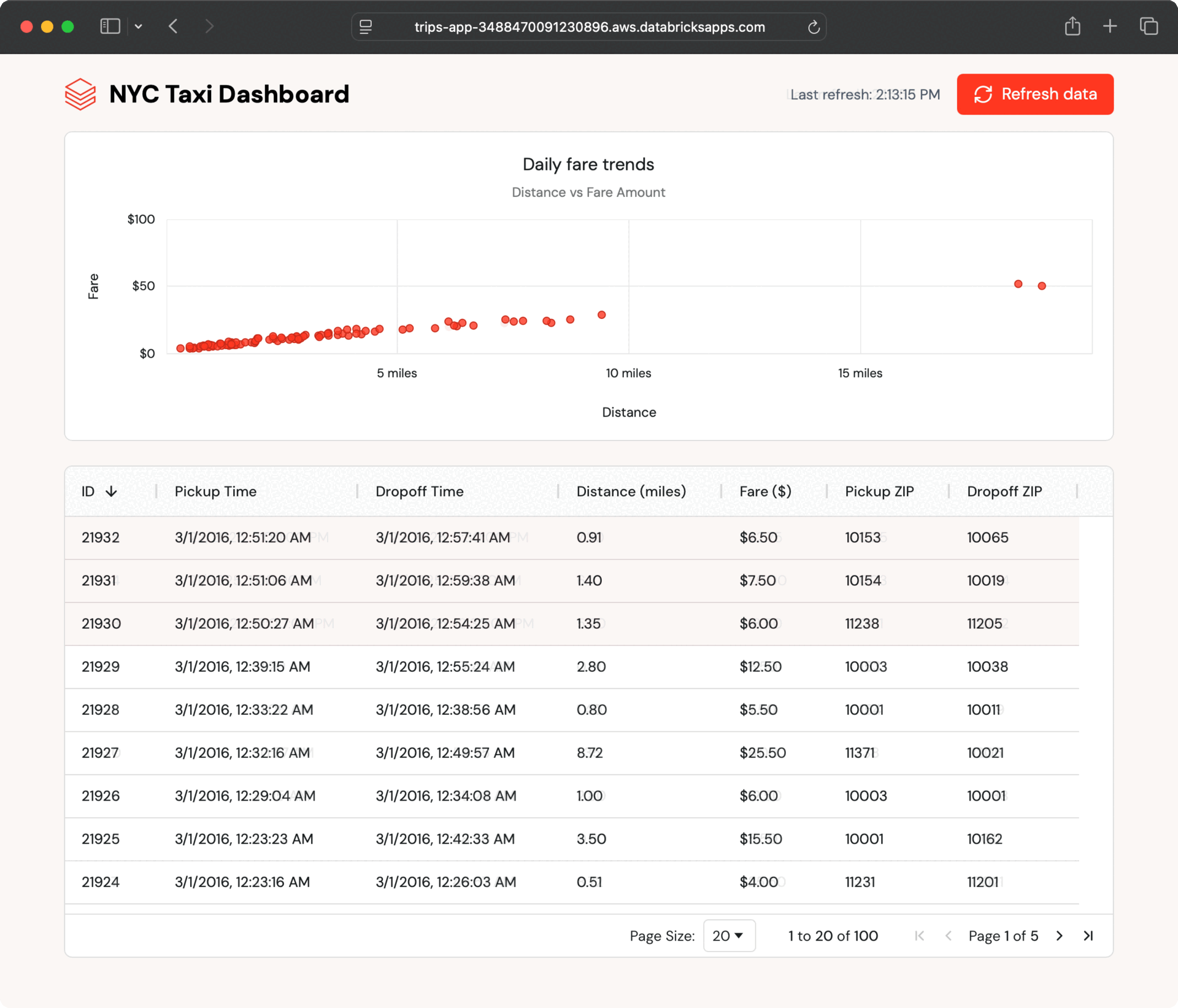
Esse fluxo de dados contínuo acontece porque as tabelas sincronizadas do Lakebase lidam com toda a sincronização automaticamente, sem a necessidade de código ETL personalizado ou coordenação entre equipes.
Anatomia do aplicativo Databricks
Vamos dar uma olhada em como os diferentes elementos da solução se reúnem no aplicativo Databricks.
Autenticação e conexão com banco de dados
Cada aplicativo Databricks tem um único diretor de serviço identidade atribuída na criação que o aplicativo usa para interagir com outros recursos do Databricks, incluindo Lakebase.
Suportes Lakebase Autenticação máquina a máquina (M2M) OAuth. Um aplicativo pode obter um token válido usando o SDK do Databricks para Pythonde Cliente do espaço de trabalho e suas credenciais principais de serviço. O WorkspaceClient se encarrega de atualizar o token OAuth de curta duração (uma hora).
O aplicativo então usa esse token ao estabelecer uma conexão com Lakebase usando o Psicopg Adaptador Python Postgres:
O host Postgres e o nome do banco de dados são definidos automaticamente como variáveis de ambiente para o aplicativo Databricks ao usar o Recurso Lakebase para aplicativos.
O utilizador Postgres é o principal do serviço de aplicações (quando implantado em aplicações Databricks) ou o nome de utilizador Databricks do utilizador que executa a aplicação localmente.
Again-end RESTful FastAPI
O back-end FastAPI do aplicativo usa esta conexão para consultar o Lakebase e buscar os dados de viagens mais recentes da tabela sincronizada:
Além de servir endpoints de API, FastAPI também pode servir arquivos estáticos usando o Classe StaticFiles. Ao agrupar nosso frontend React (app/frontend) usando o processo de construção do Vite, podemos gerar um conjunto de arquivos estáticos que podemos servir usando FastAPI.
Interface de reação
O frontend React chama o endpoint FastAPI para exibir os dados:
O aplicativo de exemplo usa ag-grid e ag-charts para visualização e verifica automaticamente novos dados a cada poucos segundos:
Definindo recursos de Databricks Asset Bundles (DABs)
Todos os recursos do Databricks e código de aplicativo mostrados acima podem ser mantidos como um pacote DABs em um repositório de código-fonte. Isto também significa que todos os recursos podem ser implantados num espaço de trabalho Databricks com um único comando. Veja o Repositório GitHub para obter instruções detalhadas de implantação.
Isso simplifica o ciclo de vida de desenvolvimento de software program e permite implantações por meio de práticas recomendadas de CI/CD em ambientes de desenvolvimento, preparação e produção.
As seções a seguir explicam os arquivos do pacote com mais detalhes.
Configuração do pacote
O databricks.yml contém a configuração do pacote DABs na forma de configurações do pacote e recursos incluídos:
Em nosso exemplo, definimos apenas um ambiente de desenvolvimento e um ambiente de teste. Para um caso de uso de produção, considere adicionar ambientes adicionais. Veja o repositório databricks-dab-examples e o Documentação de DABs para exemplos de configuração mais avançados.
Configuração do Lakebase e sincronização com o Unity Catalog
Para definir uma instância Lakebase em DABs, use o instâncias_de_banco de dados recurso. No mínimo, precisamos definir o campo de capacidade da instância.
Além disso, definimos um tabelas_de_banco_de_dados sincronizados recurso, que configura um pipeline de sincronização gerenciado entre uma tabela do Unity Catalog e uma tabela Postgres.
Para isso, defina uma tabela de origem through source_table_full_name. A tabela de origem no Catálogo do Unity precisa de uma chave primária exclusiva (composta) para poder processar atualizações definidas no campo Primary_key_columns.
A localização da tabela de destino no Lakebase é determinada pelo objeto do banco de dados de destino especificado como nome_do_banco_de_dados_lógico e pelo nome da tabela definido como nome.
Uma tabela sincronizada também é um objeto do Unity Catalog. Nesta definição de recurso, colocamos a tabela sincronizada no mesmo catálogo e esquema que a tabela de origem utilizando variáveis DABs definidas em databricks.yml. Você pode substituir esses padrões definindo diferentes valores de variáveis.
Para nosso caso de uso, usamos o modo de sincronização SNAPSHOP. Consulte as seções de considerações e práticas recomendadas para uma discussão sobre as opções disponíveis.
Recurso de aplicativos Databricks
DABs nos permitem definir o recurso de computação do Databricks Apps como um aplicativos recurso, bem como o código-fonte do aplicativo em um pacote. Isso nos permite manter a definição de recurso e o código-fonte do Databricks em um único repositório. No nosso caso, o código-fonte do aplicativo baseado em FastAPI e Vite é armazenado no diretório de aplicativo de nível superior do projeto.
A configuração faz referência dinamicamente a database_name e instance_name definidos na definição de recurso database.yml.
banco de dados é um suporte recurso de aplicativo que pode ser definido em DABs. Ao definir o banco de dados como um recurso de aplicativocriamos automaticamente uma função Postgres para ser usada pela entidade de serviço do aplicativo ao interagir com a instância do Lakebase.
Considerações e Melhores Práticas
Crie pacotes modulares e reutilizáveis
Embora este exemplo seja implantado em ambientes de desenvolvimento e preparação, os DABs facilitam a definição de vários ambientes para se adequar ao seu ciclo de vida de desenvolvimento. Automatize a implantação nesses ambientes configurando pipelines de CI/CD com Azure DevOps, Ações do GitHubou outras plataformas DevOps.
Usar DABs substituições e variáveis para definir configurações específicas do ambiente. Por exemplo, você pode definir diferentes configurações de capacidade de instância Lakebase para desenvolvimento e produção para reduzir custos. Da mesma forma, você pode definir diferentes modos de sincronização do Lakebase para suas tabelas sincronizadas para atender aos requisitos de latência de dados específicos do ambiente.
Escolha os modos de sincronização do Lakebase e otimize o desempenho
Escolhendo o Lakebase certo modo de sincronização é a chave para equilibrar custos e atualização de dados.
Instantâneo | Provocado | Contínuo | |
Método de atualização | Substituição completa da tabela em cada execução | Cópia completa inicial + alterações incrementais | Carga inicial + atualizações de streaming em tempo actual |
Desempenho | 10x mais eficiente que outros modos | Custo e desempenho equilibrados | Custo mais alto (em funcionamento contínuo) |
Latência | Alta latência (programado/handbook) | Latência média (Sob demanda) | Latência mais baixa (tempo actual, aproximadamente 15 segundos) |
Melhor para |
|
|
|
Limitações |
|
|
|
Configure notificações para que seu pipeline de sincronização gerenciado seja alertado em caso de falhas.
Para melhorar o desempenho da consulta, dimensione corretamente sua instância de banco de dados Lakebase escolhendo um apropriado capacidade da instância. Considere criar índices na tabela sincronizada no Postgres que corresponda aos seus padrões de consulta. Use o pré-instalado Extensão pg_stat_statements para investigar o desempenho da consulta.
Put together seu aplicativo para produção
O aplicativo de exemplo implementa uma abordagem baseada em pesquisas para obter os dados mais recentes do Lakebase. Dependendo de seus requisitos, você também pode implementar uma abordagem baseada em push baseada em WebSockets ou Eventos enviados pelo servidor para usar os recursos do servidor com mais eficiência e aumentar a pontualidade das atualizações de dados.
Para escalar para um número maior de usuários de aplicativos, reduzindo a necessidade do back-end FastAPI para acionar operações de banco de dados, considere implementar o cache, por exemplo, usando fastapi-cache para armazenar em cache os resultados da consulta na memória.
Autenticação e autorização
Use OAuth 2.0 para autorização e autenticação – não confie em tokens de acesso pessoal legados (PATs). Durante o desenvolvimento em sua máquina native, use a CLI do Databricks para configurar Autenticação OAuth U2M para interagir perfeitamente com recursos ativos do Databricks, como Lakebase.
Da mesma forma, seu aplicativo implantado usa sua entidade de serviço associada para autenticação e autorização OAuth M2M com outros serviços do Databricks. Como alternativa, configure autorização de usuário para seu aplicativo para executar ações nos recursos do Databricks em nome dos usuários do seu aplicativo.
Veja também Práticas recomendadas para aplicativos na documentação do Databricks Apps para obter práticas recomendadas gerais e de segurança adicionais.
Conclusão
Criar aplicativos de dados de produção não deve significar fazer malabarismos com ferramentas separadas para implantação, sincronização de dados e gerenciamento de infraestrutura. O Databricks Apps oferece computação sem servidor para executar seus aplicativos Python e Node.js sem gerenciar a infraestrutura. As tabelas sincronizadas do Lakebase entregam automaticamente dados de baixa latência das tabelas Delta do Unity Catalog para o Postgres, eliminando pipelines ETL personalizados. Os Databricks Asset Bundles unem tudo, permitindo que você empacote o código do aplicativo, as definições de infraestrutura e as configurações de sincronização de dados em um único pacote controlado por versão que é implantado de forma consistente em todos os ambientes.
A complexidade da implantação mata o impulso. Quando você não consegue entregar as mudanças com rapidez e confiança, você desacelera a iteração, introduz variações no ambiente e perde tempo na coordenação entre as equipes. Ao tratar toda a sua pilha de aplicativos como código com DABs, você habilita a automação de CI/CD, garante implantações consistentes em desenvolvimento, preparação e produção e permite que você e sua equipe se concentrem na construção de recursos em vez de lutar contra pipelines de implantação. É assim que você passa do protótipo para a produção sem as dores de cabeça habituais de implantação.
O exemplo completo está disponível no Repositório GitHub com instruções de implantação passo a passo.
Comece
Saiba mais sobre Base do lago, Aplicativos de blocos de dadose Pacotes de ativos do Databricks visitando a documentação do Databricks. Para obter mais recursos para desenvolvedores em aplicativos Databricks, dê uma olhada no Livro de receitas de aplicativos do Databricks e Coleção de recursos do livro de receitas.