Qwen acaba de lançar 8 novos modelos como parte de sua mais recente família – Qwen3, apresentando recursos promissores. O principal modelo, QWEN3-235B-A22B, superou a maioria dos outros modelos, incluindo Deepseek-R1, Openi’s O1O3-mini, Grok 3 e Gêmeos 2.5-Professionalem benchmarks padrão. Enquanto isso, o pequeno QWEN3-30B-A3B superou QWQ-32B que possui aproximadamente 10 vezes os parâmetros ativados como o novo modelo. Com esses recursos avançados, esses modelos provam ser uma ótima opção para uma ampla gama de aplicações. Neste artigo, exploraremos os recursos de todos os modelos QWEN3 e aprenderemos a usá -los para criar sistemas de pano e agentes de IA.
O que é Qwen3?
Qwen3 é a última série de grandes modelos de linguagem (LLMS) na família Qwen, composta por 8 modelos diferentes. Isso inclui QWEN3-235B-A22B, QWEN3-30B-A3B, QWEN3-32B, QWEN3-14B, QWEN3-8B, QWEN3-4B, QWEN3-1.7B e QWEN3-0.6B. Todos esses modelos são lançados na licença Apache 2.0, disponibilizando -os gratuitamente para indivíduos, desenvolvedores e empresas.
Enquanto 6 desses modelos são densos, o que significa que eles usam ativamente todos os parâmetros durante o tempo de inferência e treinamento, 2 deles são ponderados abertos:
- QWEN3-235B-A22B: Um modelo grande com 235 bilhões de parâmetros, dos quais 22 bilhões são parâmetros ativados.
- QWEN3-30B-A3B: Um MOE menor com 30 bilhões de parâmetros totais e 3 bilhões de parâmetros ativados.
Aqui está uma comparação detalhada de todos os 8 modelos QWEN3:
| Modelos | Camadas | Cabeças (Q/KV) | Incorporação de amarração | Comprimento do contexto |
| QWEN3-0.6B | 28 | 16/8 | Sim | 32k |
| QWEN3-1.7B | 28 | 16/8 | Sim | 32k |
| QWEN3-4B | 36 | 32/8 | Sim | 32k |
| QWEN3-8B | 36 | 32/8 | Não | 128K |
| QWEN3-14B | 40 | 40/8 | Não | 128K |
| QWEN3-32B | 64 | 64/8 | Não | 128K |
| QWEN3-30B-A3B | 48 | 32/4 | Não | 128K |
| QWEN3-235B-A22B | 94 | 64/4 | Não | 128K |
Aqui está o que a tabela diz:
- Camadas: As camadas representam o número de blocos de transformadores utilizados. Inclui mecanismo de auto-atendimento de várias cabeças, redes de alimentação, codificação posicional, normalização da camada e conexões residuais. Portanto, quando digo que o QWEN3-30B-A3B possui 48 camadas, isso significa que o modelo usa 48 blocos de transformadores, empilhados sequencialmente ou em paralelo.
- Cabeças: Os transformadores usam atenção de várias cabeças, que divide seu mecanismo de atenção em várias cabeças, cada uma para aprender um novo aspecto dos dados. Aqui, P/KV representa:
- Q (cabeças de consulta): Número whole de cabeças de atenção usadas para gerar consultas.
- Kv (chave e valor): O número de cabeças de chave/valor por bloco de atenção.
Observação: Essas cabeças de atenção para a chave, a consulta e o valor são completamente diferentes da chave, consulta e vetor de valor gerado por uma auto-atimento.
Leia também: Modelos QWEN3: Como acessar, desempenho, recursos e aplicativos
Principais recursos de Qwen3
Aqui estão alguns dos principais recursos dos modelos QWEN3:
- Pré-treinamento: O processo de pré-treinamento consiste em três estágios:
- Na primeira etapa, o modelo foi pré -terenciado em mais de 30 trilhões de tokens com um comprimento de contexto de 4K tokens. Isso ensinou ao modelo habilidades básicas de linguagem e conhecimento geral.
- No segundo estágio, a qualidade dos dados foi aprimorada aumentando a proporção de dados intensivos em conhecimento, como TEM, codificação e tarefas de raciocínio. O modelo foi então treinado em mais de 5 trilhões de tokens.
- Na fase last, dados de contexto longo de alta qualidade foram usados aumentando o comprimento do contexto para 32k tokens. Isso foi feito para garantir que o modelo possa lidar com entradas mais longas de maneira eficaz.
- Pós-treinamento: Para desenvolver um modelo híbrido capaz de raciocínio passo a passo e respostas rápidas, foi implementado um pipeline de treinamento em quatro etapas. Isso consistia em:
- Modos de pensamento híbrido: Os modelos QWEN3 usam uma abordagem híbrida para resolver problemas, com dois novos modos:
- Modo de pensamento: Nesse modo, os modelos levam tempo quebrando uma declaração complexa de problemas em etapas pequenas e processuais para resolvê -la.
- Modo de não pensar: Nesse modo, o modelo fornece resultados rápidos e é principalmente adequado para perguntas mais simples.
- Suporte multilíngue: Os modelos QWEN3 suportam 119 idiomas e dialetos. Isso ajuda usuários de todo o mundo a se beneficiar desses modelos.
- Recursos agênticos improvisados: Qwen otimizou os modelos QWEN3 para obter melhores recursos de codificação e agitação, apoiando Modelo Protocolo de contexto (MCP) também.
Como acessar os modelos QWEN3 by way of API
Para usar os modelos QWEN3, estaremos acessando -o by way of API usando a API do OpenRouter. Veja como fazer:
- Criar uma conta em OpenRouter E vá para a barra de pesquisa de modelos para encontrar a API para esse modelo.

- Selecione o modelo de sua escolha e clique em ‘Criar chave da API’ na página de destino para gerar uma nova API.
Usando QWEN3 para alimentar suas soluções de IA
Nesta seção, passaremos pelo processo de criação de aplicativos de IA usando QWEN3. Primeiro, criaremos um agente de planejador de viagens a IA usando o modelo e depois um bot de pano Q/A usando Langchain.
Pré -requisitos
Antes de construir algumas soluções de IA do mundo actual com QWEN3, precisamos primeiro cobrir os pré-requisitos básicos como:
Construindo um agente de IA usando QWEN3
Nesta seção, usaremos o QWEN3 para criar um agente de viagens movido a IA que dará os principais pontos de viagem para a cidade ou o lugar que você está visitando. Também permitiremos que o agente pesquise na Web para encontrar informações atualizadas e adicionar uma ferramenta que permite a conversão de moeda.
Etapa 1: Configurando bibliotecas e ferramentas
Primeiro, estaremos instalando e importando as bibliotecas e ferramentas necessárias para criar o agente.
!pip set up langchain langchain-community openai duckduckgo-search
from langchain.chat_models import ChatOpenAI
from langchain.brokers import Instrument
from langchain.instruments import DuckDuckGoSearchRun
from langchain.brokers import initialize_agent
llm = ChatOpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your_api_key",
mannequin="qwen/qwen3-235b-a22b:free"
)
# Net Search Instrument
search = DuckDuckGoSearchRun()
# Instrument for DestinationAgent
def get_destinations(vacation spot):
return search.run(f"High 3 vacationer spots in {vacation spot}")
DestinationTool = Instrument(
title="Vacation spot Recommender",
func=get_destinations,
description="Finds high locations to go to in a metropolis"
)
# Instrument for CurrencyAgent
def convert_usd_to_inr(question):
quantity = (float(s) for s in question.break up() if s.substitute('.', '', 1).isdigit())
if quantity:
return f"{quantity(0)} USD = {quantity(0) * 83.2:.2f} INR"
return "Could not parse quantity."
CurrencyTool = Instrument(
title="Foreign money Converter",
func=convert_usd_to_inr,
description="Converts USD to inr primarily based on static price"
)- Search_tool: DuckDuckGoSearchRun () permite que o agente use a pesquisa na internet para obter informações em tempo actual sobre os locais turísticos populares.
- DestinationTool: Aplica a função get_destinations (), que usa a ferramenta de pesquisa para obter os três principais pontos turísticos em qualquer cidade.
- CurrencyTool: Usa a função convert_usd_to_inr () para converter os preços de USD para INR. Você pode alterar ‘INR’ na função para convertê -la em uma moeda de sua escolha.
Leia também: Construa um assistente de viagem Chatbot com Huggingface, Langchain e Mistralai
Etapa 2: Criando o agente
Agora que inicializamos todas as ferramentas, vamos criar um agente que usará as ferramentas e nos dará um plano para a viagem.
instruments = (DestinationTool, CurrencyTool)
agent = initialize_agent(
instruments=instruments,
llm=llm,
agent_type="zero-shot-react-description",
verbose=True
)
def trip_planner(metropolis, usd_budget):
dest = get_destinations(metropolis)
inr_budget = convert_usd_to_inr(f"{usd_budget} USD to INR")
return f"""Right here is your journey plan:
*High spots in {metropolis}*:
{dest}
*Price range*:
{inr_budget}
Take pleasure in your day journey!"""- Inicialize_agent: Esta função cria um agente com Langchain usando uma abordagem de reação de tiro zero, que permite ao agente entender as descrições da ferramenta.
- Agente_type: O “Zero-Shot-REACT-Description” permite que o Agent LLM decida qual ferramenta deve usar em uma determinada situação sem conhecimento prévio, usando a descrição e a entrada da ferramenta.
- Verbose: Verbose permite o registro do processo de pensamento do agente, para que possamos monitorar cada decisão que o agente toma, incluindo todas as interações e ferramentas invocadas.
- trip_planner: Esta é uma função python que chama manualmente ferramentas em vez de confiar no agente. Ele permite ao usuário selecionar a melhor ferramenta para um problema específico.
Etapa 3: inicializando o agente
Nesta seção, inicializaremos o agente e observaremos sua resposta.
# Initialize the Agent
metropolis = "Delhi"
usd_budget = 8500
# Run the multi-agent planner
response = agent.run(f"Plan a day journey to {metropolis} with a funds of {usd_budget} USD")
from IPython.show import Markdown, show
show(Markdown(response))- Invocação de agente: Agent.run () usa a intenção do usuário by way of immediate e planeja a viagem.
Saída

Construindo um sistema de pano usando QWEN3
Nesta seção, estaremos criando um Bot Bot Isso responde a qualquer consulta no documento de entrada relevante da base de conhecimento. Isso fornece uma resposta informativa usando QWEN/QWEN3-235B-A22B. O sistema também usaria o Langchain, para produzir respostas precisas e com consciência de contexto.
Etapa 1: Configurando as bibliotecas e ferramentas
Primeiro, estaremos instalando e importando as bibliotecas e ferramentas necessárias para construir o sistema de pano.
!pip set up langchain langchain-community langchain-core openai tiktoken chromadb sentence-transformers duckduckgo-search
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
# Load your doc
loader = TextLoader("/content material/my_docs.txt")
docs = loader.load()- Carregando documentos: A classe “TextLoader” de Langchain carrega o documento como um arquivo PDF, TXT ou DOC, que será usado para a recuperação Q/A. Aqui eu carreguei my_docs.txt.
- Selecionando a configuração do vetor: Eu usei o Chromadb para armazenar e pesquisar as incorporações do nosso banco de dados vetorial para o processo Q/A.
Etapa 2: Criando as incorporações
Agora que carregamos nosso documento, vamos criar incorporações a partir dele, o que ajudará a aliviar o processo de recuperação.
# Break up into chunks
splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=50)
chunks = splitter.split_documents(docs)
# Embed with HuggingFace mannequin
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
db = Chroma.from_documents(chunks, embedding=embeddings)
# Setup Qwen LLM from OpenRouter
llm = ChatOpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="YOUR_API_KEY",
mannequin="qwen/qwen3-235b-a22b:free"
)
# Create RAG chain
retriever = db.as_retriever(search_kwargs={"okay": 2})
rag_chain = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)- Documento dividindo: O características do característico () divide o texto em pedaços menores, o que ajudará principalmente em duas coisas. Primeiro, facilita o processo de recuperação e, segundo, ajuda a manter o contexto a partir do pedaço anterior by way of Chunk_overlap.
- Incorporar documentos: As incorporações convertem o texto nos vetores de incorporação de uma dimensão definida para cada token. Aqui usamos o Chunk_size de 300, o que significa que cada palavra/token será convertida em um vetor de 300 dimensões. Agora, essa incorporação do vetor terá todas as informações contextuais dessa palavra em relação às outras palavras no pedaço.
- Cadeia de pano: A cadeia de pano combina o cromadb com o LLM para formar um pano. Isso nos permite obter respostas contextualmente conscientes do documento e também do modelo.
Etapa 3: Inicializando o sistema de pano
# Ask a query
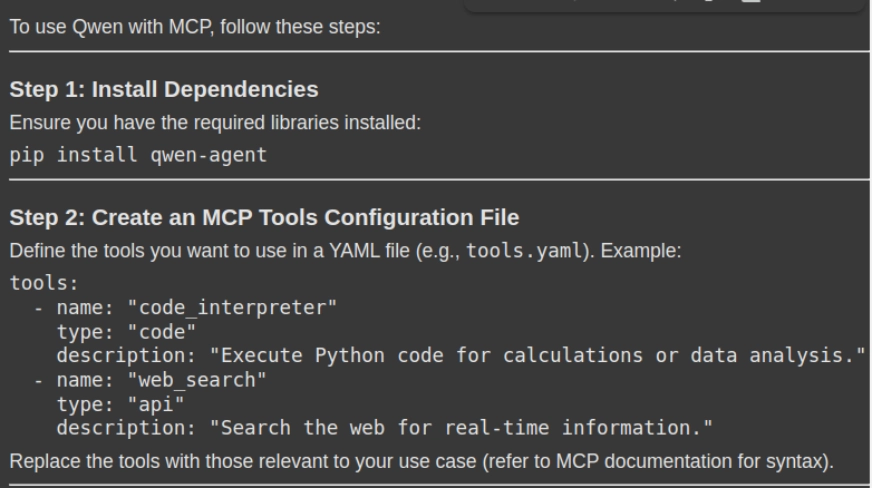
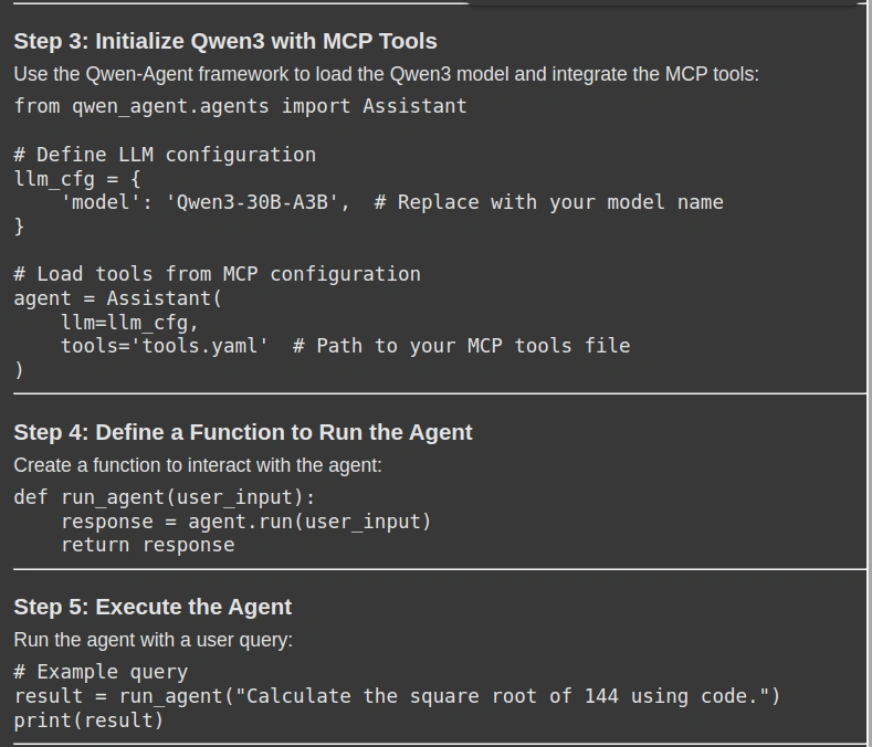
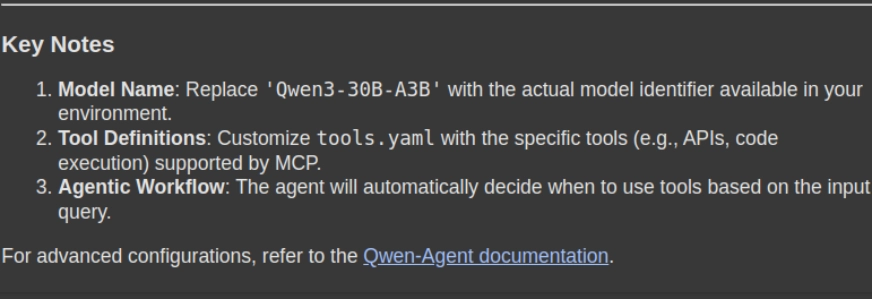
response = rag_chain.invoke({"question": "How can i exploit Qwen with MCP. Please give me a stepwise information together with the mandatory code snippets"})
show(Markdown(response('outcome')))- Execução de consulta: O método rag_chain_invoke () enviará a consulta do usuário para o sistema RAG, que recupera os pedaços relevantes com reconhecimento de contexto da loja de documentos (DB Vector) e gera uma resposta com reconhecimento de contexto.
Saída
Você pode encontrar o código completo aqui.
Aplicações de QWEN3
Aqui estão mais algumas aplicações do QWEN3 em todos os setores:
- Codificação automatizada: O QWEN3 pode gerar, depurar e fornecer documentação para o código, que ajuda os desenvolvedores a resolver erros sem esforço handbook. Seu modelo de parâmetro 22B se destaca na codificação, com performances comparáveis a modelos como Deepseek-r1Gemini 2.5 Professional e Openai’s O3-mini.
- Educação e pesquisa: A QWEN3 arquiva alta precisão em matemática, física e resolução de problemas de raciocínio lógico. Ele também rivaliza com o Gemini 2.5 Professional, enquanto se destaca com modelos como O1 O1, O3-mini, Deepseek-R1 e Grok 3 Beta.
- Integração de ferramentas baseada em agente: O QWEN3 também lidera as tarefas do agente de IA, permitindo o uso de ferramentas externas, APIs e MCPs para fluxos de trabalho de várias etapas e multi-agentes com seu modelo de chamada de ferramentas, o que simplifica ainda mais a interação agêntica.
- Tarefas avançadas de raciocínio: O QWEN3 usa uma extensa capacidade de pensamento para fornecer respostas ideais e precisas. O modelo usa o raciocínio da cadeia de pensamentos para tarefas complexas e um modo de não pensar em velocidade otimizada.
Conclusão
Neste artigo, aprendemos a construir sistemas de IA e pano Agentic AI e Rag de QWEN3. O alto desempenho, suporte multilíngue e capacidade avançado de raciocínio da QWEN3 o tornam uma forte escolha para tarefas de recuperação e agente. Ao integrar o QWEN3 em pipelines de pano e agênticos, podemos obter respostas precisas, com reconhecimento de contexto e suaves, tornando-o um forte candidato a aplicativos do mundo actual para sistemas movidos a IA.
Perguntas frequentes
A. QWEN3 possui uma capacidade de raciocínio híbrido que permite fazer alterações dinâmicas nas respostas, o que permite otimizar os fluxos de trabalho do RAG para análise de recuperação e complexa.
R. Inclui principalmente o banco de dados vetorial, modelos de incorporação, fluxo de trabalho de Langchain e uma API para acessar o modelo.
Sim, com os modelos de chamada de ferramentas internos QWEN-AGENT, podemos analisar e ativar operações de ferramentas seqüenciais, como pesquisa na Net, análise de dados e geração de relatórios.
R. Pode -se reduzir a latência de várias maneiras, alguns deles são:
1. Uso de modelos MOE como QWEN3-30B-A3B, que possuem apenas 3 bilhões de parâmetros ativos.
2. Usando inferências otimizadas para GPU.
A. O erro comum inclui:
1. Falhas de inicialização do servidor MCP, como formatação JSON e init.
2. Erros de emparelhamento de resposta à ferramenta.
3. Overflow da janela de contexto.
Oi, eu sou Vipin. Sou apaixonado por ciência de dados e aprendizado de máquina. Tenho experiência em analisar dados, criar modelos e resolver problemas do mundo actual. Pretendo usar dados para criar soluções práticas e continuar aprendendo nas áreas de ciência de dados, aprendizado de máquina e PNL.
Faça login para continuar lendo e desfrutar de conteúdo com curado especialista.