Introdução
Construir ferramentas internas ou aplicativos com potência de IA, a maneira “tradicional” que eleva os desenvolvedores em um labirinto de tarefas repetitivas e propensas a erros. Primeiro, eles devem aumentar uma instância dedicada do Postgres, configurar redes, backups e monitoramento e, em seguida, passar horas (ou dias) encanamento esse banco de dados na estrutura do remaining da frente que estão usando. Além disso, eles precisam escrever fluxos de autenticação personalizados, mapear permissões granulares e manter esses controles de segurança sincronizados na interface do usuário, na camada de API e no banco de dados. Cada componente de aplicativo vive em um ambiente diferente, de um serviço de nuvem gerenciado a uma VM auto -posterior. Isso força os desenvolvedores a fazer malabarismos com pipelines de implantação díspares, variáveis ambientais e lojas de credenciais. O resultado é uma pilha fragmentada, onde uma única alteração, como uma migração de esquema ou uma nova função, ondula através de vários sistemas, exigindo atualizações manuais, testes extensos e coordenação constante. Todas essas despesas gerais distraem os desenvolvedores do valor actual: construir os principais recursos e inteligência do produto.
Com os aplicativos Databricks Lakebase e Databricks, toda a pilha de aplicativos se senta, ao lado da casa Lakehouse. Lakebase é um banco de dados Postgres totalmente gerenciado que oferece leituras e gravações de baixa latência, integradas às mesmas mesas de Lakehouse subjacente que alimentam suas análises e cargas de trabalho de IA. Os aplicativos Databricks fornecem um tempo de execução sem servidor para a interface do usuário, juntamente com autenticação interna, permissões de granulação fina e controles de governança que são aplicados automaticamente aos mesmos dados que Lakebase atende. Isso facilita a criação e implantação de aplicativos que combinem estado transacional, análise e IA sem costurar várias plataformas, sincronizar bancos de dados, replicar tubulações ou reconciliar políticas de segurança entre os sistemas.
Por que Lakebase + Databricks Apps
Os aplicativos Lakebase e Databricks funcionam juntos para simplificar o desenvolvimento da pilha completa na plataforma Databricks:
- Base Lake Fornece um banco de dados Postgres totalmente gerenciado com leituras, gravações e atualizações rápidas, além de recursos modernos como ramificação e recuperação ponto-tempo.
- Databricks Apps Fornece o tempo de execução sem servidor para o seu front-end de aplicativo, com identidade interna, controle de acesso e integração com o catálogo de unidades e outros componentes de Lakehouse.
Ao combinar os dois, você pode criar ferramentas interativas que armazenam e atualizam o estado em Lakebase, o Entry governou os dados no Lakehouse e sirva tudo através de uma interface do usuário segura e sem servidor, tudo sem gerenciar a infraestrutura separada. No exemplo abaixo, mostraremos como criar um aplicativo de aprovação de solicitação de férias simples usando essa configuração.
Introdução: Construa um aplicativo transacional com LakeBase
Este passo a passo mostra como criar um aplicativo simples de banco de dados que ajuda os gerentes a revisar e aprovar solicitações de férias de sua equipe. O aplicativo é criado com os aplicativos Databricks e usa o LakeBase como banco de dados de again -end para armazenar e atualizar as solicitações.

Aqui está o que a solução cobre:
- Provisão de um banco de dados
Configure um banco de dados OLTP PostGres e sem servidor com alguns cliques. - Crie um aplicativo Databricks
Crie um aplicativo interativo usando uma estrutura Python (como o streamlit ou o Sprint) que lê e grava para o LakeBase. - Configurar esquema, tabelas e controles de acesso
Crie as tabelas necessárias e atribua permissões de granulação fina ao aplicativo usando o ID do cliente do aplicativo. - Conecte -se com segurança e interaja com o lago
Use o Databricks SDK e o SQLALCHEMY para ler e escrever com segurança para LakeBase a partir do seu código de aplicativo.
O passo a passo foi projetado para começar rapidamente com um exemplo de trabalho mínimo. Mais tarde, você pode estendê -lo com uma configuração mais avançada.
Etapa 1: Provisão Lakebase
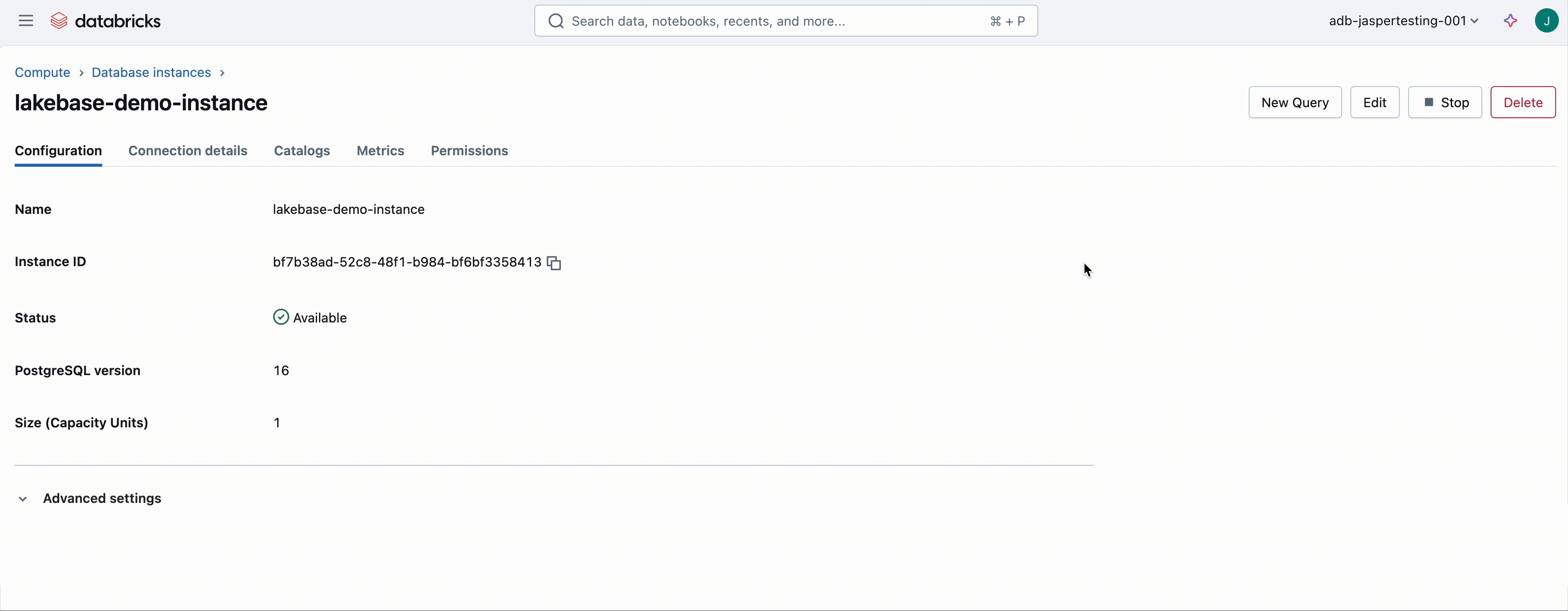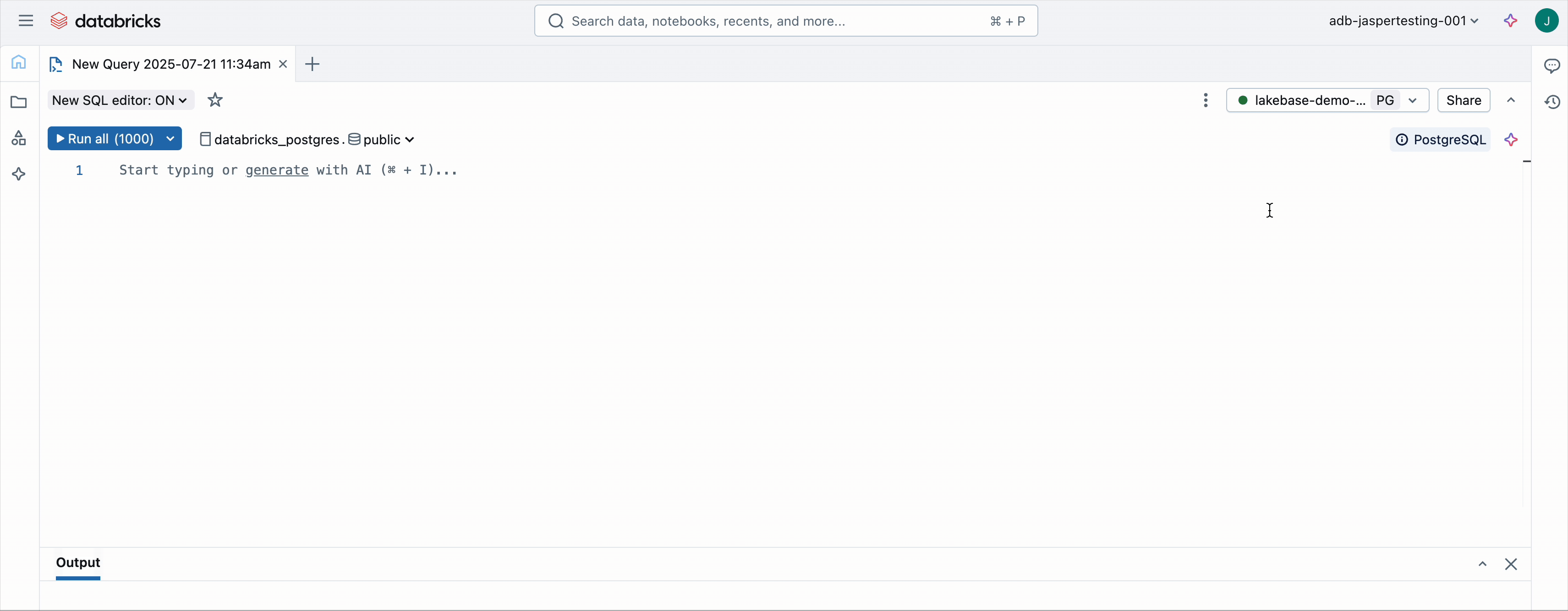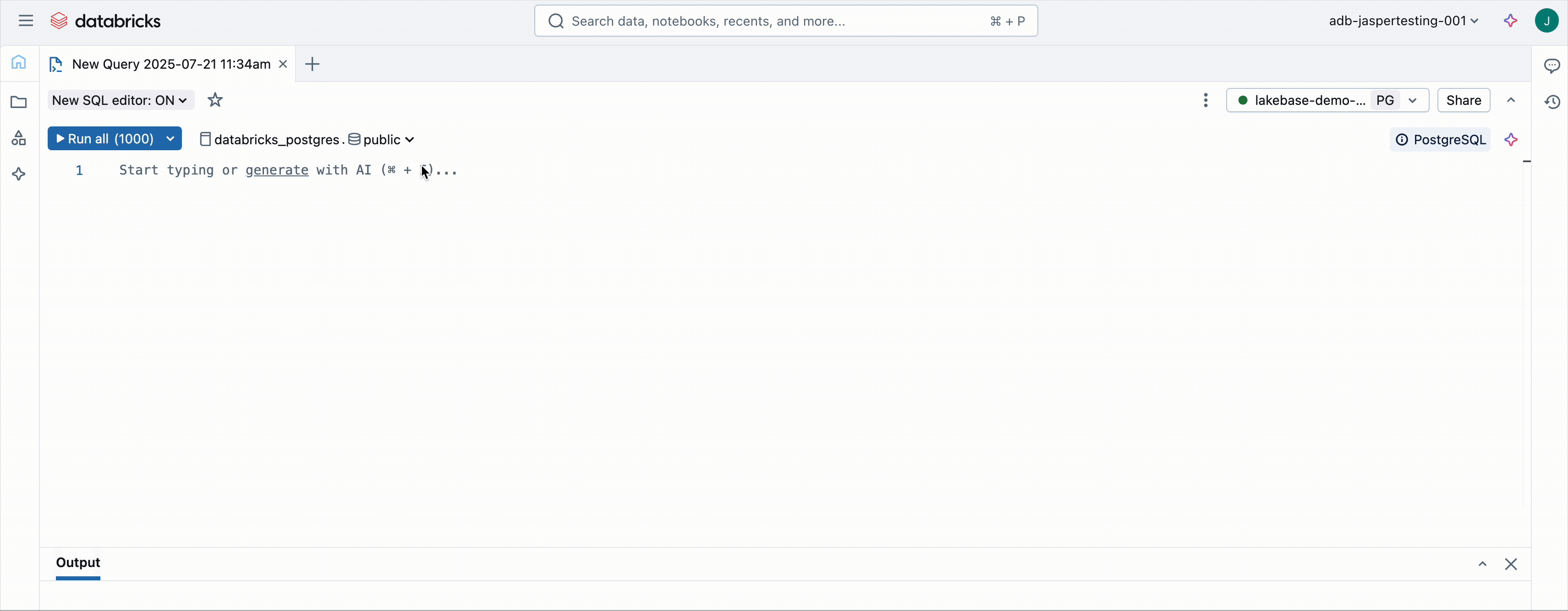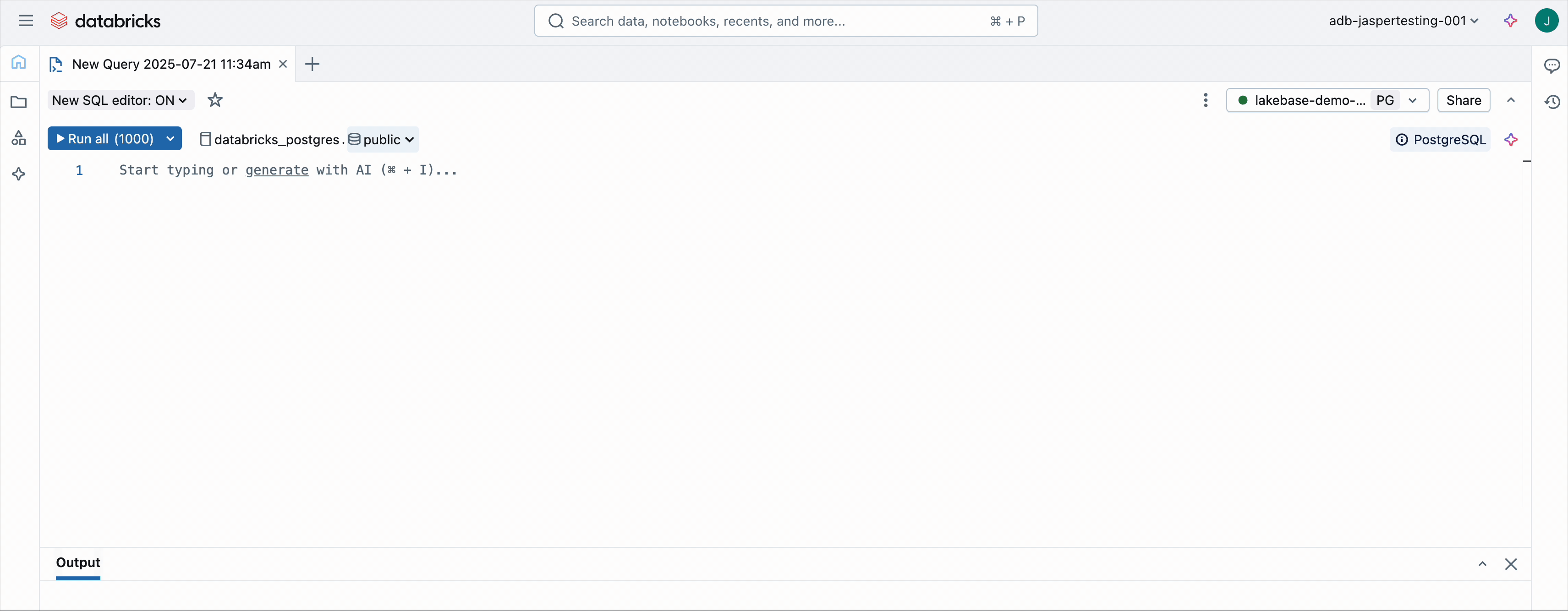
Antes de construir o aplicativo, você precisará criar um banco de dados de base de lago. Para fazer isso, vá para o Calcular guia, selecione Banco de dados OLTPe fornecer um nome e tamanho. Isso provisões uma instância sem servidor Lakebase. Neste exemplo, nossa instância de banco de dados é chamada Lakebase—instância.

Etapa 2: Crie um aplicativo Databricks e adicione acesso ao banco de dados
Agora que temos um banco de dados, vamos criar o aplicativo Databricks que se conectará a ele. Você pode começar em um aplicativo em branco ou escolher um modelo (por exemplo, simplidade ou balão). Depois de nomear seu aplicativo, adicione o Banco de dados como um recurso. Neste exemplo, o pré-criado DATABRICKS_POSTGRES O banco de dados está selecionado.
Adicionando o recurso de banco de dados automaticamente:
- Concede o aplicativo conectar e criar privilégios
- Cria uma função pós -gres ligada ao ID do cliente do aplicativo
Esta função será posteriormente usada para conceder acesso ao nível da tabela.

Etapa 3: Crie um esquema, tabela e defina permissões
Com o banco de dados provisionado e o aplicativo conectado, agora você pode definir o esquema e a tabela do aplicativo usará.
1. Recupere o ID do cliente do aplicativo
Do aplicativo Ambiente guia, copie o valor da variável DATABRICKS_CLIENT_ID. Você precisará disso para as declarações de concessão.
2. Abra o editor SQL da Base LakeSe
Vá para a sua instância de Lakebase e clique Nova consulta. Isso abre o editor SQL com o endpoint do banco de dados já selecionado.
3. Execute o seguinte SQL:
Observe que, ao usar o editor SQL, é uma maneira rápida e eficaz de executar esse processo, o gerenciamento de esquemas de banco de dados em escala é melhor tratado por ferramentas dedicadas que oferecem suporte ao versão, colaboração e automação. Ferramentas como Flyway e LIFIBASE permitem rastrear as alterações do esquema, integrar -se aos pipelines CI/CD e garantir que sua estrutura de banco de dados evolui com segurança ao lado do código do aplicativo.
Etapa 4: construa o aplicativo
Com permissões em vigor, agora você pode criar seu aplicativo. Neste exemplo, o aplicativo busca solicitações de férias da Lakebase e permite que um gerente os aprove ou rejeite. As atualizações são escritas de volta para a mesma tabela.

Etapa 5: conecte -se com segurança à base de lago
Use o SQLalChemy e o Databricks SDK para conectar seu aplicativo ao LakeBase com autenticação segura baseada em token. Quando você adiciona o recurso Lakebase, PGHOST e PGUSER são expostos automaticamente. O SDK lida com o cache de token.
Etapa 6: Leia e atualize dados
As seguintes funções leiam e atualizam a tabela de solicitações de férias:
Os trechos de código acima podem ser usados em combinação com estruturas como o Stiratrlit, o Sprint e o Flask para extrair os dados da LakeBase e visualizá -los em seu aplicativo. Para garantir que todas as dependências necessárias sejam instaladas, adicione os pacotes necessários ao seu aplicativo requisitos.txt arquivo. Os pacotes usados nos trechos de código estão listados abaixo.
Estendendo a casa lake com a base de lago
Lakebase adiciona recursos transacionais à casa Lakehouse, integrando um banco de dados OLTP totalmente gerenciado diretamente na plataforma. Isso reduz a necessidade de bancos de dados externos ou pipelines complexos ao criar aplicativos que requerem leituras e gravações.

Por ser integrado nativamente aos bancos de dados, incluindo sincronização de dados, autenticação de identidade e segurança de rede – assim como outros ativos de dados na casa de Lakehouse. Você não precisa de ETL personalizado ou ETL reverso para mover dados entre os sistemas. Por exemplo:
- Você pode servir os recursos analíticos de volta às aplicações em tempo actual (disponível hoje) usando a loja de recursos on -line e as tabelas sincronizadas.
- Você pode sincronizar dados operacionais com a tabela Delta, por exemplo, para análise de dados históricos (em visualização privada).
Esses recursos facilitam o suporte aos casos de uso de grau de produção, como:
- Atualizando o estado em agentes de IA
- Gerenciando fluxos de trabalho em tempo actual (por exemplo, aprovações, roteamento de tarefas)
- Alimentando dados ao vivo em sistemas de recomendação ou mecanismos de precificação
O Lakebase já está sendo usado em todos os setores para aplicações, incluindo recomendações personalizadas, aplicativos de chatbot e ferramentas de gerenciamento de fluxo de trabalho.
O que vem a seguir
Se você já está usando o Databricks para análise e IA, o LakeBase facilita a adição de interatividade em tempo actual aos seus aplicativos. Com suporte para transações de baixa latência, segurança interna e integração rígida com aplicativos Databricks, você pode ir do protótipo para a produção sem sair da plataforma.
Resumo
O LakeBase fornece um banco de dados transacional do Postgres que funciona perfeitamente com os aplicativos Databricks e fornece fácil integração com os dados de Lakehouse. Ele simplifica o desenvolvimento de dados de pilha completa e aplicativos de IA, eliminando a necessidade de sistemas OLTP externos ou etapas de integração handbook.
Neste exemplo, mostramos como:
- Configure uma instância de Lakebase e configure o acesso
- Crie um aplicativo Databricks que lê e grava no LakeBase
- Use autenticação segura e baseada em token com configuração mínima
- Crie um aplicativo básico para gerenciar solicitações de férias usando Python e SQL
Lakebase está agora em pré -visualização pública. Você pode experimentá -lo hoje diretamente do seu espaço de trabalho do Databricks. Para detalhes sobre uso e preço, consulte o Base Lake e Aplicativos documentação.