Grandes modelos de IA estão se expandindo rapidamente, com arquiteturas maiores e treinamentos mais longos se tornando a norma. À medida que os modelos crescem, contudo, uma questão elementary de estabilidade da formação permanece por resolver. O DeepSeek mHC aborda diretamente esse problema, repensando como as conexões residuais se comportam em escala. Este artigo explica o DeepSeek mHC (hiperconexões restritas ao coletor) e mostra como ele melhora modelo de linguagem grande treinando estabilidade e desempenho sem adicionar complexidade arquitetônica desnecessária.
O problema oculto com conexões residuais e hiperconexões
Conexões residuais têm sido um alicerce central do aprendizado profundo desde o lançamento do ResNet em 2016. Eles permitem que as redes criem caminhos de atalho, permitindo que as informações fluam diretamente através das camadas, em vez de serem reaprendidas a cada passo. Em termos simples, elas funcionam como vias expressas em uma rodovia, facilitando o treinamento de redes profundas.

Essa abordagem funcionou bem durante anos. Mas à medida que os modelos passaram de milhões para milhares de milhões, e agora para centenas de milhares de milhões de parâmetros, as suas limitações tornaram-se claras. Para impulsionar ainda mais o desempenho, os pesquisadores introduziram Hiperconexões (HC), ampliando efetivamente essas rodovias de informações ao adicionar mais caminhos. O desempenho melhorou visivelmente, mas a estabilidade não.
O treinamento tornou-se altamente instável. Os modelos treinariam normalmente e, de repente, entrariam em colapso em torno de uma etapa específica, com picos de perda acentuados e gradientes explosivos. Para equipes que treinam grandes modelos de linguagem, esse tipo de falha pode significar o desperdício de grandes quantidades de computação, tempo e recursos.
O que são hiperconexões com restrições múltiplas (mHC)?
É uma estrutura geral que mapeia o espaço de conexão residual do HC para uma determinada variedade para reforçar a propriedade de mapeamento de identidade e, ao mesmo tempo, envolve otimização estrita da infraestrutura para ser eficiente.
Testes empíricos mostram que o mHC é bom para treinamento em larga escala, proporcionando não apenas claros ganhos de desempenho, mas também excelente escalabilidade. Esperamos que o mHC, sendo uma adição versátil e acessível ao HC, ajude na compreensão do projeto de arquitetura topológica e proponha novos caminhos para o desenvolvimento de modelos fundamentais.
O que torna o mHC diferente?
A estratégia da DeepSeek não é apenas inteligente, é brilhante porque faz você pensar “Oh, por que ninguém nunca pensou nisso antes?” Eles ainda mantiveram as hiperconexões, mas as limitaram com um método matemático preciso.
Esta é a parte técnica (não desista de mim, valerá a pena entender): Conexões residuais padrão permitem realizar o que é conhecido como “mapeamento de identidade”. Think about isso como a lei da conservação de energia, onde os sinais viajam pela rede no mesmo nível de potência. Quando o HC aumentou a largura do fluxo residual e o combinou com padrões de conexão que podem ser aprendidos, eles violaram involuntariamente essa propriedade.
Os pesquisadores do DeepSeek compreenderam que os mapeamentos compostos do HC, essencialmente, quando você empilha essas conexões camada após camada, aumentam os sinais em multiplicadores de 3.000 vezes ou até mais. Think about que você inicia um diálogo e cada vez que alguém comunica sua mensagem, a sala inteira grita 3.000 vezes mais alto. Isso não é nada além de caos.
O mHC resolve o problema projetando essas matrizes de conexão no politopo de Birkhoff, um objeto geométrico abstrato em que cada linha e coluna tem uma soma igual a 1. Pode parecer teórico, mas na realidade faz com que a rede trate a propagação do sinal como uma combinação convexa de características. Chega de explosões, chega de sinais desaparecendo completamente.
A arquitetura: como o mHC realmente funciona
Vamos explorar os detalhes de como o DeepSeek alterou as conexões dentro do modelo. O design depende de três mapeamentos principais que determinam a direção da informação:
O sistema de três mapeamentos
Em Hyper-Connections, três matrizes que podem ser aprendidas executam tarefas diferentes:
- H_pré: Leva as informações do fluxo residual estendido para a camada
- H_post: Envia a saída da camada de volta ao stream
- H_res: Combina e atualiza as informações no próprio fluxo
Visualize-o como um sistema de rodovias onde H_pre é a rampa de entrada, H_post é a rampa de saída e H_res é o gerenciador do fluxo de tráfego entre as faixas.
Uma das descobertas dos estudos de ablação do DeepSeek é muito interessante – H_res (o mapeamento aplicado aos resíduos) é o principal contribuinte para o aumento de desempenho. Eles o desativaram, permitindo apenas mapeamentos pré e pós, e o desempenho caiu drasticamente. Isso é lógico: o ponto alto do processo é quando recursos de diferentes profundidades interagem e trocam informações.
A restrição múltipla
Este é o ponto onde o mHC começa a se desviar do HC regular. Em vez de permitir que H_res seja escolhido arbitrariamente, eles impõem que ele seja duplamente estocástico, uma característica que faz com que cada linha e cada coluna soma 1.
Qual é a importância disso? Existem três razões principais:
- As normas são mantidas intactas: A norma espectral é mantida dentro dos limites de 1, portanto os gradientes não podem explodir.
- Encerramento sob composição: Dobrar matrizes duplamente estocásticas resulta em outra matriz duplamente estocástica; portanto, toda a profundidade da rede ainda é estável.
- Uma ilustração em termos de geometria: As matrizes estão no politopo de Birkhoff, que é o casco convexo de todas as matrizes de permutação. Em outras palavras, a rede aprende combinações ponderadas de padrões de roteamento onde as informações fluem de maneira diferente.
O algoritmo Sinkhorn-Knopp é o usado para impor essa restrição, que é um método iterativo que mantém normalizando linhas e colunas alternadamente até que a precisão desejada seja alcançada. Nos experimentos, foi estabelecido que 20 iterações produzem uma aproximação adequada sem cálculo excessivo.
Detalhes de parametrização
A execução é inteligente. Em vez de trabalhar em vetores de características únicas, o mHC comprime toda a matriz oculta n×C em um vetor. Isto permite que as informações de contexto completas sejam usadas na computação do mapeamento dinâmico.
Os últimos mapeamentos restritos se aplicam:
- Ativação sigmóide para H_pre e H_post (garantindo assim a não negatividade)
- Projeção Sinkhorn-Knopp para H_res (reforçando assim a estocasticidade dupla)
- Valores de inicialização pequenos (α = 0,01) para fatores de portas começarem com conservadores
Esta configuração interrompe o cancelamento do sinal causado pelas interações entre coeficientes positivos-negativos e ao mesmo tempo mantém a importante propriedade de mapeamento de identidade.
Comportamento de dimensionamento: ele se sustenta?
Uma das coisas mais surpreendentes é como os benefícios do mHC aumentam. DeepSeek conduziu seus experimentos em três dimensões diferentes:
- Dimensionamento de computação: Eles treinaram nos parâmetros 3B, 9B e 27B com dados proporcionais. A vantagem de desempenho permaneceu a mesma e até aumentou ligeiramente com orçamentos mais elevados para a computação. Isso é incrível porque geralmente muitos truques arquitetônicos que funcionam em pequena escala não funcionam quando ampliados.
- Dimensionamento de token: Eles monitoraram o desempenho durante todo o treinamento de seu modelo 3B treinado em 1 trilhão de tokens. A melhoria das perdas foi estável desde o início do treino até à fase de convergência, indicando que os benefícios do mHC não se limitam ao período de treino inicial.
- Análise de propagação: Você se lembra daqueles fatores de amplificação de sinal de 3.000x no vanilla HC? Com o mHC, a magnitude máxima do ganho foi reduzida para cerca de 1,6, sendo três ordens de grandeza mais estável. Mesmo depois de compor mais de 60 camadas, os ganhos de sinal para frente e para trás permaneceram bem controlados.
Referências de desempenho
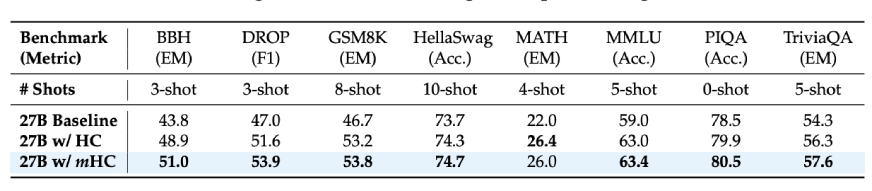
A DeepSeek avaliou o mHC em diferentes modelos com tamanhos de parâmetros variando de 3 bilhões a 27 bilhões e os ganhos de estabilidade foram particularmente visíveis:
- A perda de treinamento foi suave durante todo o processo, sem picos repentinos
- As normas do gradiente foram mantidas na mesma faixa, em contraste com o HC, que apresentou comportamento selvagem
- O mais significativo foi que o desempenho não só melhorou, mas também foi demonstrado em vários benchmarks
Se considerarmos os resultados das tarefas posteriores para o modelo 27B:
- Tarefas de raciocínio BBH: 51,0% (vs. 43,8% da linha de base)
- Compreensão de leitura DROP: 53,9% (vs. 47,0% da linha de base)
- Problemas matemáticos GSM8K: 53,8% (vs. 46,7% da linha de base)
- Conhecimento MMLU: 63,4% (vs. 59,0% da linha de base)
Estas não representam pequenas melhorias, mas na verdade estamos falando de aumentos de 7 a ten pontos em benchmarks de raciocínio difícil. Além disso, essas melhorias não foram observadas apenas nos modelos maiores, mas também durante períodos de treinamento mais longos, como foi o caso do escalonamento dos modelos de aprendizagem profunda.
Leia também: DeepSeek-V3.2-Exp: 50% mais barato, 3x mais rápido, valor máximo
Conclusão
Se você estiver trabalhando ou treinando grandes modelos de linguagem, o mHC é um aspecto que você definitivamente deve considerar. É um daqueles artigos raros, que identifica um problema actual, apresenta uma solução matematicamente válida e até prova que funciona em larga escala.
As principais revelações são:
- O aumento da largura do fluxo residual leva a um melhor desempenho; no entanto, métodos ingênuos causam instabilidade
- Limitar as interações a matrizes duplamente estocásticas mantém as propriedades do mapeamento de identidade
- Se bem feito, a sobrecarga pode ser quase imperceptível
- As vantagens podem ser reaplicadas a modelos com tamanho de dezenas de bilhões de parâmetros
Além disso, o mHC é um lembrete de que o projeto arquitetônico ainda é um fator essential. A questão de como usar mais computação e dados não pode durar para sempre. Haverá momentos em que será necessário dar um passo atrás, compreender o motivo da falha em grande escala e corrigi-la adequadamente.
E para ser sincero, essa pesquisa é o que mais gosto. Não são pequenas mudanças a serem feitas, mas sim mudanças profundas que tornarão todo o campo um pouco mais robusto.
Estagiário de geração de IA na Analytics Vidhya
Departamento de Ciência da Computação, Vellore Institute of Expertise, Vellore, Índia
Atualmente trabalho como estagiário de Gen AI na Analytics Vidhya, onde contribuo para soluções inovadoras baseadas em IA que capacitam as empresas a aproveitar os dados de forma eficaz. Como estudante do último ano de Ciência da Computação no Vellore Institute of Expertise, trago para minha função uma base sólida em desenvolvimento de software program, análise de dados e aprendizado de máquina.
Sinta-se à vontade para se conectar comigo em (e-mail protegido)
Faça login para continuar lendo e desfrutar de conteúdo com curadoria de especialistas.