Detecção de objetos é elementary em inteligência syntheticservindo como espinha dorsal para inúmeras aplicações de ponta. Desde veículos autónomos e sistemas de vigilância até imagens médicas e realidade aumentada, a capacidade de identificar e localizar objetos em imagens e vídeos está a transformar as indústrias em todo o mundo. A API Object Detection do TensorFlow, uma ferramenta poderosa e versátil, simplifica a construção de modelos robustos de detecção de objetos. Ao aproveitar esta API, os desenvolvedores podem treinar modelos personalizados adaptados a necessidades específicas, reduzindo significativamente o tempo e a complexidade do desenvolvimento.
Neste guia, exploraremos o processo passo a passo de treinamento de um modelo de detecção de objetos usando o TensorFlow, com foco na integração de conjuntos de dados de Universo Roboflowum rico repositório de conjuntos de dados anotados projetados para acelerar o desenvolvimento de IA.
Objetivos de aprendizagem
- Aprenda a instalar e configurar TensorFlowAmbiente de API de detecção de objetos do para treinamento de modelo eficiente.
- Entenda como preparar e pré-processar conjuntos de dados para treinamento usando o formato TFRecord.
- Obtenha experiência na seleção e personalização de um modelo de detecção de objetos pré-treinado para necessidades específicas.
- Aprenda a ajustar os arquivos de configuração do pipeline e os parâmetros do modelo para otimizar o desempenho.
- Domine o processo de treinamento, incluindo o tratamento de pontos de verificação e a avaliação do desempenho do modelo durante o treinamento.
- Entenda como exportar o modelo treinado para inferência e implantação em aplicações do mundo actual.
Este artigo foi publicado como parte do Blogatona de Ciência de Dados.
Implementação passo a passo de detecção de objetos com TensorFlow
Nesta seção, orientaremos você em uma implementação passo a passo da detecção de objetos usando o TensorFlow, orientando você desde a configuração até a implantação.
Passo 1: Configurando o Ambiente
A API TensorFlow Object Detection requer várias dependências. Comece clonando o repositório de modelos do TensorFlow:
# Clone the tensorflow fashions repository from GitHub
!pip uninstall Cython -y # Short-term repair for "No module named 'object_detection'" error
!git clone --depth 1 https://github.com/tensorflow/fashions- Desinstale o Cython: Esta etapa garante que não haja conflitos com a biblioteca Cython durante a configuração.
- Clonar repositório de modelos do TensorFlow: Este repositório contém os modelos oficiais do TensorFlow, incluindo a API de detecção de objetos.

Copie os arquivos de configuração e modifique o arquivo setup.py
# Copy setup information into fashions/analysis folder
%%bash
cd fashions/analysis/
protoc object_detection/protos/*.proto --python_out=.
#cp object_detection/packages/tf2/setup.py .
# Modify setup.py file to put in the tf-models-official repository focused at TF v2.8.0
import re
with open('/content material/fashions/analysis/object_detection/packages/tf2/setup.py') as f:
s = f.learn()
with open('/content material/fashions/analysis/setup.py', 'w') as f:
# Set fine_tune_checkpoint path
s = re.sub('tf-models-official>=2.5.1',
'tf-models-official==2.8.0', s)
f.write(s)Por que isso é necessário?
- Compilação de buffers de protocolo: A API de detecção de objetos usa arquivos .proto para definir configurações de modelo e estruturas de dados. Eles precisam ser compilados em código Python para funcionar.
- Compatibilidade de versão de dependência: O TensorFlow e suas dependências evoluem. Usar tf-models-official>=2.5.1 pode instalar inadvertidamente uma versão incompatível do TensorFlow v2.8.0.
- Definir explicitamente tf-models-official==2.8.0 evita possíveis conflitos de versão e garante estabilidade.
Instalando bibliotecas de dependência
Os modelos do TensorFlow geralmente dependem de versões específicas da biblioteca. A correção da versão do TensorFlow garante uma integração tranquila.
# Set up the Object Detection API
# Have to do a short lived repair with PyYAML as a result of Colab is not capable of set up PyYAML v5.4.1
!pip set up pyyaml==5.3
!pip set up /content material/fashions/analysis/
# Have to downgrade to TF v2.8.0 as a consequence of Colab compatibility bug with TF v2.10 (as of 10/03/22)
!pip set up tensorflow==2.8.0
# Set up CUDA model 11.0 (to take care of compatibility with TF v2.8.0)
!pip set up tensorflow_io==0.23.1
!wget https://developer.obtain.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin
!mv cuda-ubuntu1804.pin /and so on/apt/preferences.d/cuda-repository-pin-600
!wget http://developer.obtain.nvidia.com/compute/cuda/11.0.2/local_installers/cuda-repo-ubuntu1804-11-0-local_11.0.2-450.51.05-1_amd64.deb
!dpkg -i cuda-repo-ubuntu1804-11-0-local_11.0.2-450.51.05-1_amd64.deb
!apt-key add /var/cuda-repo-ubuntu1804-11-0-local/7fa2af80.pub
!apt-get replace && sudo apt-get set up cuda-toolkit-11-0
!export LD_LIBRARY_PATH=/usr/native/cuda-11.0/lib64:$LD_LIBRARY_PATHAo executar este bloco, você precisa reiniciar as sessões novamente e executar este bloco de código novamente para instalar todas as dependências com sucesso. Isso instalará todas as dependências com sucesso.
Instalando uma versão apropriada da biblioteca protobuf para resolver problemas de dependência
!pip set up protobuf==3.20.1
Passo 2: Verifique o ambiente e as instalações
Para confirmar se a instalação funciona, execute o seguinte teste:
# Run Mannequin Bulider Check file, simply to confirm every part's working correctly
!python /content material/fashions/analysis/object_detection/builders/model_builder_tf2_test.py
Se nenhum erro aparecer, sua configuração está concluída. Agora concluímos a configuração com sucesso.
Etapa 3: preparar os dados de treinamento
Para este tutorial, usaremos o “Detecção de Pessoas” conjunto de dados de Universo Roboflow. Siga estas etapas para prepará-lo:
Visite a página do conjunto de dados:

Bifurque o conjunto de dados em seu espaço de trabalho para torná-lo acessível para personalização.
Gere uma versão do conjunto de dados para finalizar suas configurações de pré-processamento, como aumento e redimensionamento.
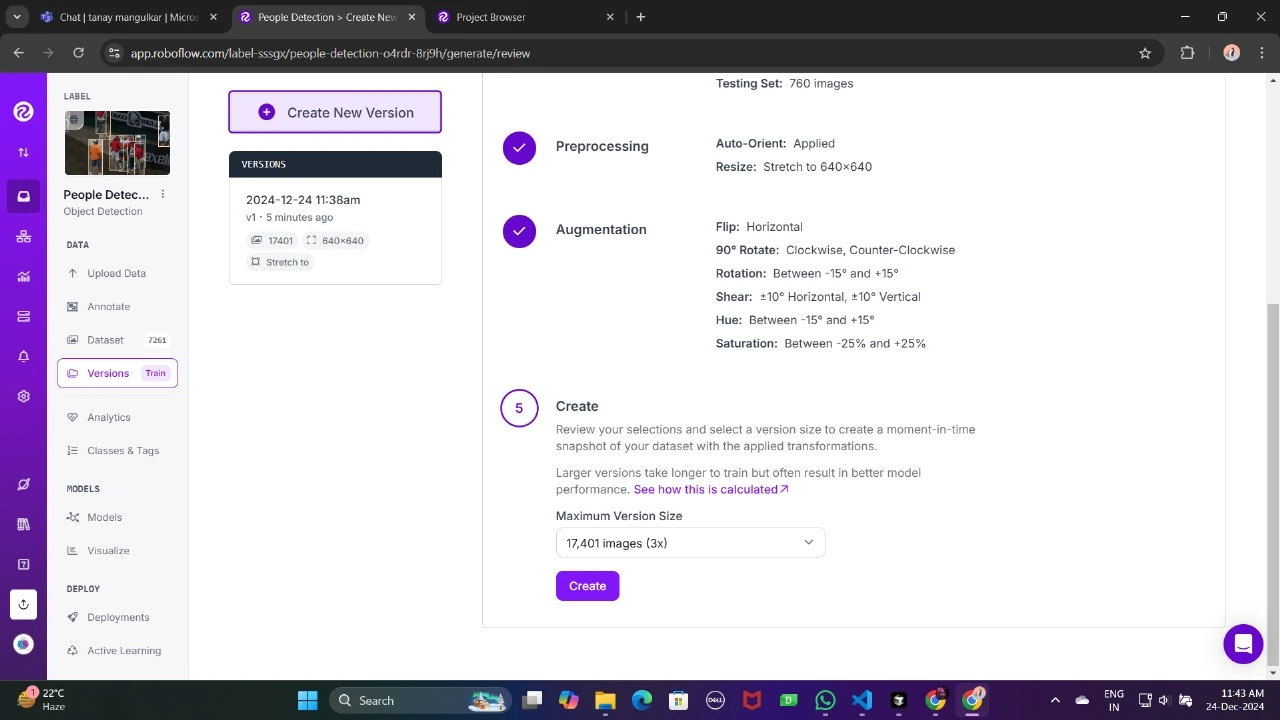
Agora, baixe-o no formato TFRecord, que é um formato binário otimizado para fluxos de trabalho do TensorFlow. O TFRecord armazena dados de forma eficiente e permite que o TensorFlow leia grandes conjuntos de dados durante o treinamento com sobrecarga mínima.
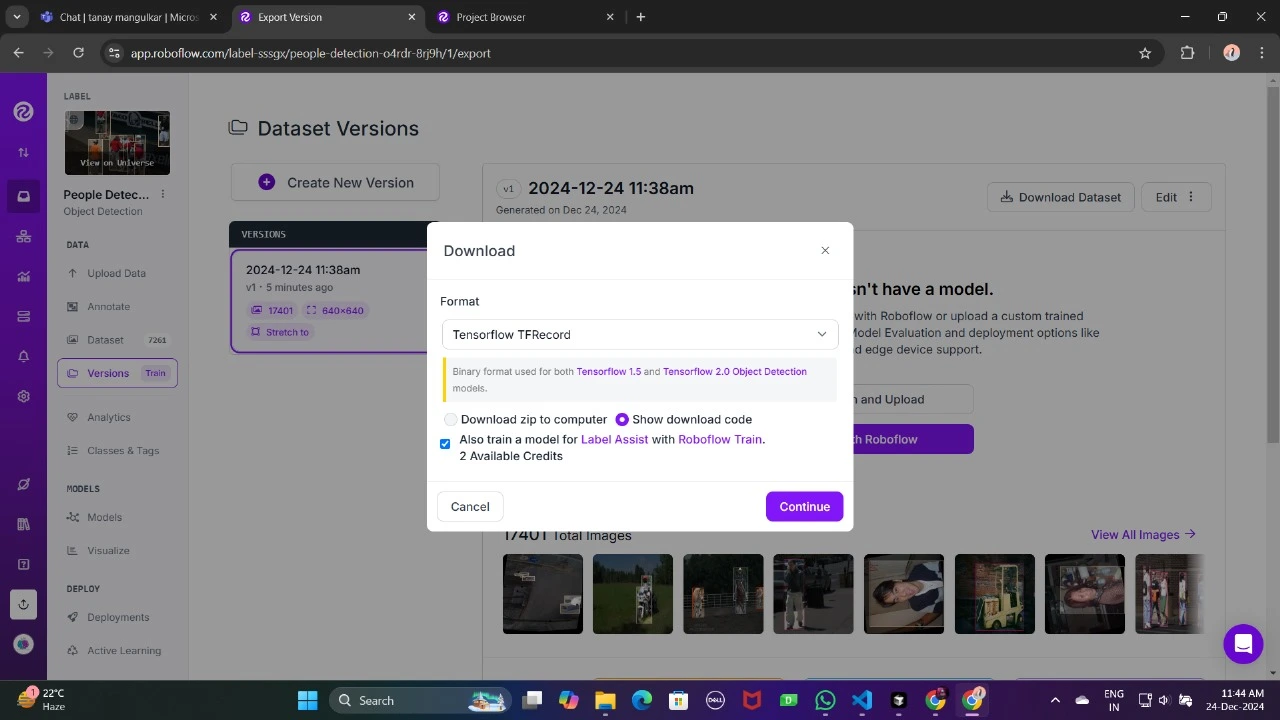
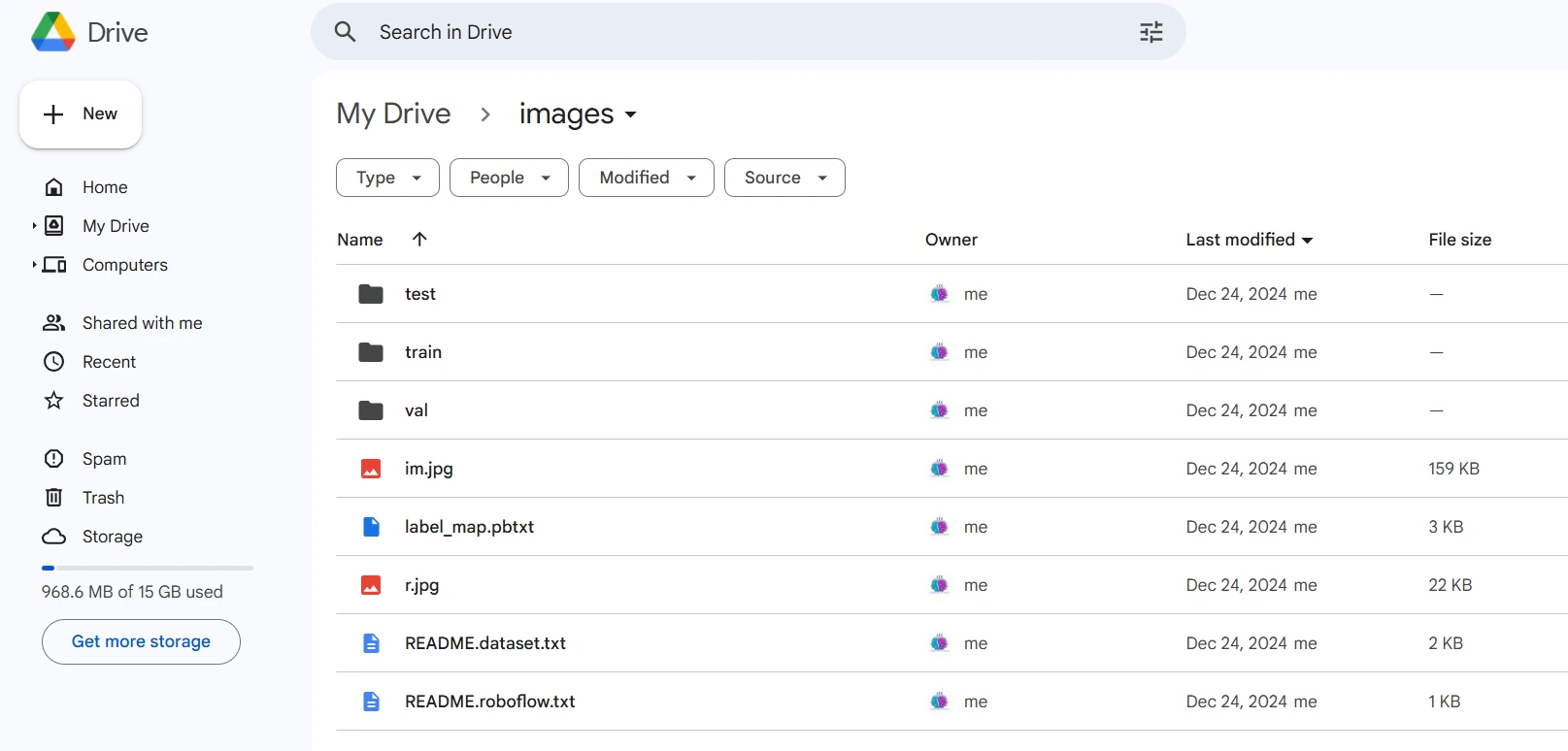
Depois de fazer o obtain, coloque os arquivos do conjunto de dados em seu Google Drive, monte seu código em sua unidade e carregue esses arquivos no código para usá-lo.
from google.colab import drive
drive.mount('/content material/gdrive')
train_record_fname="/content material/gdrive/MyDrive/photos/prepare/prepare.tfrecord"
val_record_fname="/content material/gdrive/MyDrive/photos/check/check.tfrecord"
label_map_pbtxt_fname="/content material/gdrive/MyDrive/photos/label_map.pbtxt"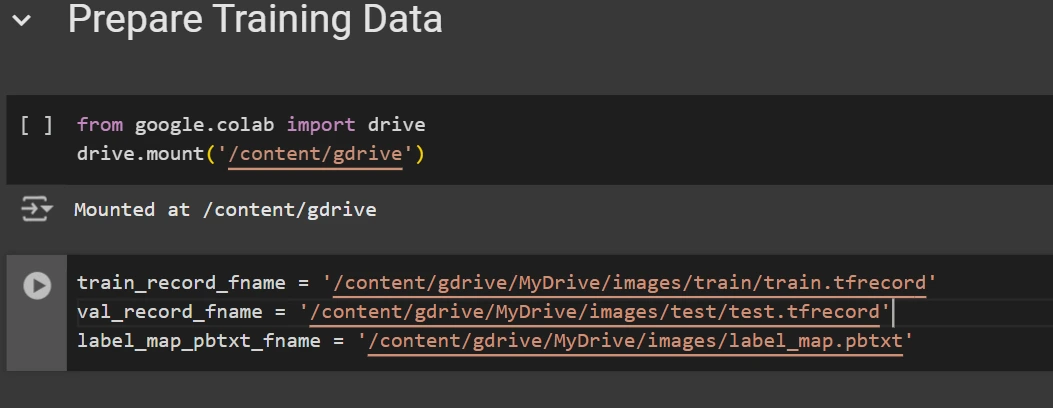
Etapa 4: definir a configuração do treinamento
Agora é hora de definir a configuração do modelo de detecção de objetos. Para este exemplo, usaremos o modeloefficientdet-d0. Você pode escolher entre outros modelos como ssd-mobilenet-v2 ou ssd-mobilenet-v2-fpnlite-320, mas para este guia vamos nos concentrar noefficientdet-d0.
# Change the chosen_model variable to deploy completely different fashions obtainable within the TF2 object detection zoo
chosen_model="efficientdet-d0"
MODELS_CONFIG = {
'ssd-mobilenet-v2': {
'model_name': 'ssd_mobilenet_v2_320x320_coco17_tpu-8',
'base_pipeline_file': 'ssd_mobilenet_v2_320x320_coco17_tpu-8.config',
'pretrained_checkpoint': 'ssd_mobilenet_v2_320x320_coco17_tpu-8.tar.gz',
},
'efficientdet-d0': {
'model_name': 'efficientdet_d0_coco17_tpu-32',
'base_pipeline_file': 'ssd_efficientdet_d0_512x512_coco17_tpu-8.config',
'pretrained_checkpoint': 'efficientdet_d0_coco17_tpu-32.tar.gz',
},
'ssd-mobilenet-v2-fpnlite-320': {
'model_name': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8',
'base_pipeline_file': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8.config',
'pretrained_checkpoint': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8.tar.gz',
},
}
model_name = MODELS_CONFIG(chosen_model)('model_name')
pretrained_checkpoint = MODELS_CONFIG(chosen_model)('pretrained_checkpoint')
base_pipeline_file = MODELS_CONFIG(chosen_model)('base_pipeline_file')Em seguida baixamos os pesos pré-treinados e o arquivo de configuração correspondente para o modelo escolhido:
# Create "mymodel" folder for holding pre-trained weights and configuration information
%mkdir /content material/fashions/mymodel/
%cd /content material/fashions/mymodel/
# Obtain pre-trained mannequin weights
import tarfile
download_tar="http://obtain.tensorflow.org/fashions/object_detection/tf2/20200711/" + pretrained_checkpoint
!wget {download_tar}
tar = tarfile.open(pretrained_checkpoint)
tar.extractall()
tar.shut()
# Obtain coaching configuration file for mannequin
download_config = 'https://uncooked.githubusercontent.com/tensorflow/fashions/grasp/analysis/object_detection/configs/tf2/' + base_pipeline_file
!wget {download_config}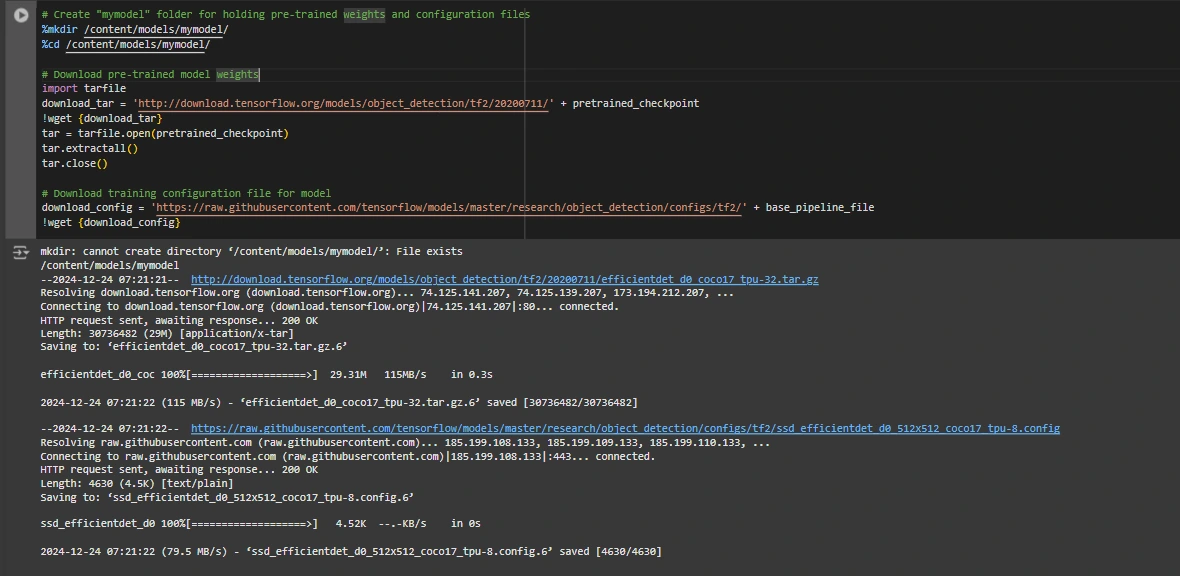
Depois disso, configuramos o número de etapas de treinamento e tamanho do lote com base no modelo selecionado:
# Set coaching parameters for the mannequin
num_steps = 4000
if chosen_model == 'efficientdet-d0':
batch_size = 8
else:
batch_size = 8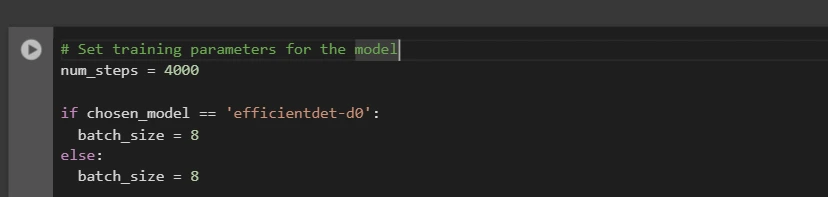
Você pode aumentar e diminuir num_steps e batch_size de acordo com suas necessidades.
Etapa 5: modificar o arquivo de configuração do pipeline
Precisamos personalizar o arquivo pipeline.config com os caminhos para nosso conjunto de dados e parâmetros de modelo. O arquivo pipeline.config contém várias configurações, como tamanho do lote, número de lessons e pontos de verificação de ajuste fino. Fazemos essas modificações lendo o modelo e substituindo os campos relevantes:
# Set file areas and get variety of lessons for config file
pipeline_fname="/content material/fashions/mymodel/" + base_pipeline_file
fine_tune_checkpoint="/content material/fashions/mymodel/" + model_name + '/checkpoint/ckpt-0'
def get_num_classes(pbtxt_fname):
from object_detection.utils import label_map_util
label_map = label_map_util.load_labelmap(pbtxt_fname)
classes = label_map_util.convert_label_map_to_categories(
label_map, max_num_classes=90, use_display_name=True)
category_index = label_map_util.create_category_index(classes)
return len(category_index.keys())
num_classes = get_num_classes(label_map_pbtxt_fname)
print('Whole lessons:', num_classes)
# Create customized configuration file by writing the dataset, mannequin checkpoint, and coaching parameters into the bottom pipeline file
import re
%cd /content material/fashions/mymodel
print('writing customized configuration file')
with open(pipeline_fname) as f:
s = f.learn()
with open('pipeline_file.config', 'w') as f:
# Set fine_tune_checkpoint path
s = re.sub('fine_tune_checkpoint: ".*?"',
'fine_tune_checkpoint: "{}"'.format(fine_tune_checkpoint), s)
# Set tfrecord information for prepare and check datasets
s = re.sub(
'(input_path: ".*?)(PATH_TO_BE_CONFIGURED/prepare)(.*?")', 'input_path: "{}"'.format(train_record_fname), s)
s = re.sub(
'(input_path: ".*?)(PATH_TO_BE_CONFIGURED/val)(.*?")', 'input_path: "{}"'.format(val_record_fname), s)
# Set label_map_path
s = re.sub(
'label_map_path: ".*?"', 'label_map_path: "{}"'.format(label_map_pbtxt_fname), s)
# Set batch_size
s = re.sub('batch_size: (0-9)+',
'batch_size: {}'.format(batch_size), s)
# Set coaching steps, num_steps
s = re.sub('num_steps: (0-9)+',
'num_steps: {}'.format(num_steps), s)
# Set variety of lessons num_classes
s = re.sub('num_classes: (0-9)+',
'num_classes: {}'.format(num_classes), s)
# Change fine-tune checkpoint sort from "classification" to "detection"
s = re.sub(
'fine_tune_checkpoint_type: "classification"', 'fine_tune_checkpoint_type: "{}"'.format('detection'), s)
# If utilizing ssd-mobilenet-v2, cut back studying price (as a result of it is too excessive within the default config file)
if chosen_model == 'ssd-mobilenet-v2':
s = re.sub('learning_rate_base: .8',
'learning_rate_base: .08', s)
s = re.sub('warmup_learning_rate: 0.13333',
'warmup_learning_rate: .026666', s)
# If utilizing efficientdet-d0, use fixed_shape_resizer as a substitute of keep_aspect_ratio_resizer (as a result of it is not supported by TFLite)
if chosen_model == 'efficientdet-d0':
s = re.sub('keep_aspect_ratio_resizer', 'fixed_shape_resizer', s)
s = re.sub('pad_to_max_dimension: true', '', s)
s = re.sub('min_dimension', 'peak', s)
s = re.sub('max_dimension', 'width', s)
f.write(s)
# (Non-compulsory) Show the customized configuration file's contents
!cat /content material/fashions/mymodel/pipeline_file.config
# Set the trail to the customized config file and the listing to retailer coaching checkpoints in
pipeline_file="/content material/fashions/mymodel/pipeline_file.config"
model_dir="/content material/coaching/"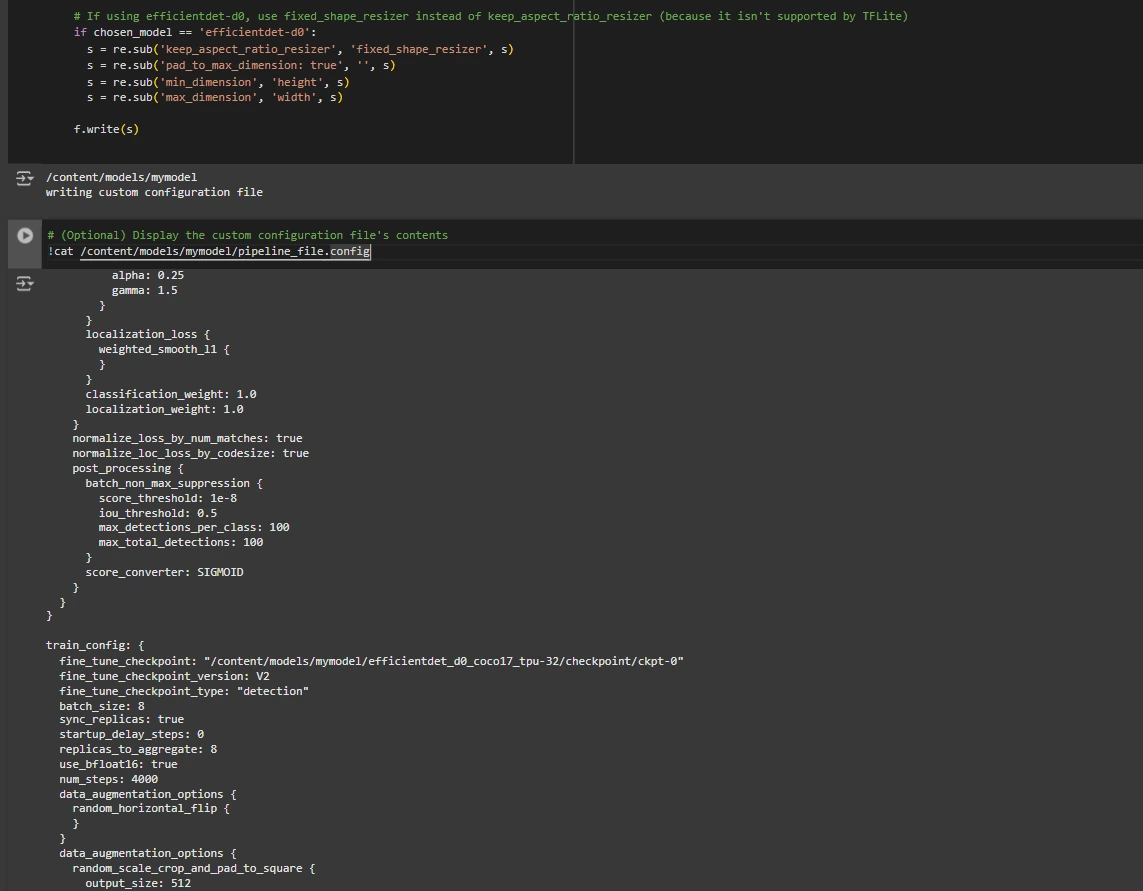
Etapa 6: treinar o modelo
Agora podemos treinar o modelo usando o arquivo de configuração do pipeline personalizado. O script de treinamento salvará pontos de verificação, que você pode usar para avaliar o desempenho do seu modelo:
# Run coaching!
!python /content material/fashions/analysis/object_detection/model_main_tf2.py
--pipeline_config_path={pipeline_file}
--model_dir={model_dir}
--alsologtostderr
--num_train_steps={num_steps}
--sample_1_of_n_eval_examples=1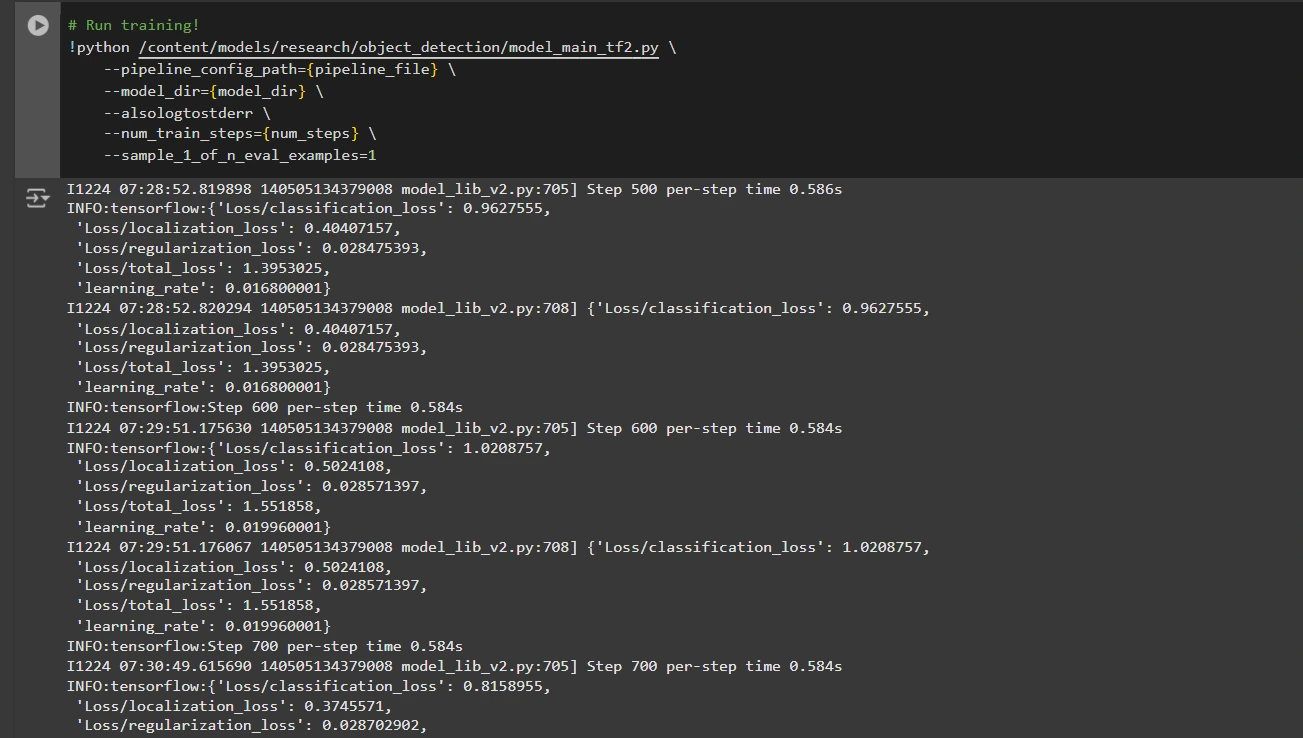
Passo 7: Salve o modelo treinado
Após a conclusão do treinamento, exportamos o modelo treinado para que possa ser usado para inferência. Usamos o script exporter_main_v2.py para exportar o modelo:
!python /content material/fashions/analysis/object_detection/exporter_main_v2.py
--input_type image_tensor
--pipeline_config_path {pipeline_file}
--trained_checkpoint_dir {model_dir}
--output_directory /content material/exported_model
Por fim, compactamos o modelo exportado em um arquivo zip para facilitar o obtain e então você pode baixar o arquivo zip contendo seu modelo treinado:
import shutil
# Path to the exported mannequin folder
exported_model_path="/content material/exported_model"
# Path the place the zip file will probably be saved
zip_file_path="/content material/exported_model.zip"
# Create a zipper file of the exported mannequin folder
shutil.make_archive(zip_file_path.change('.zip', ''), 'zip', exported_model_path)
# Obtain the zip file utilizing Google Colab's file obtain utility
from google.colab import information
information.obtain(zip_file_path)
Você pode usar esses arquivos de modelo baixados para testá-los em imagens invisíveis ou em seus aplicativos de acordo com suas necessidades.
Você pode consultar isto: pocket book collab para código detalhado
Conclusão
Concluindo, este guia fornece o conhecimento e as ferramentas necessárias para treinar um modelo de detecção de objetos usando a API de detecção de objetos do TensorFlow, aproveitando conjuntos de dados do Roboflow Universe para personalização rápida. Seguindo as etapas descritas, você pode preparar seus dados com eficácia, configurar o pipeline de treinamento, selecionar o modelo certo e ajustá-lo para atender às suas necessidades específicas. Além disso, a capacidade de exportar e implementar o seu modelo treinado abre vastas possibilidades para aplicações do mundo actual, seja em veículos autônomos, imagens médicas ou sistemas de vigilância. Esse fluxo de trabalho permite criar sistemas de detecção de objetos poderosos e escaláveis com complexidade reduzida e tempo de implantação mais rápido.
Principais conclusões
- A API TensorFlow Object Detection oferece uma estrutura flexível para criar modelos personalizados de detecção de objetos com opções pré-treinadas, reduzindo o tempo de desenvolvimento e a complexidade.
- O formato TFRecord é essencial para o manuseio eficiente de dados, especialmente com grandes conjuntos de dados no TensorFlow, permitindo treinamento rápido e sobrecarga mínima.
- Os arquivos de configuração do pipeline são cruciais para ajustar e ajustar o modelo para funcionar com seu conjunto de dados específico e características de desempenho desejadas.
- Modelos pré-treinados comoefficientdet-d0 e ssd-mobilenet-v2 fornecem pontos de partida sólidos para o treinamento de modelos personalizados, cada um com pontos fortes específicos, dependendo do caso de uso e das restrições de recursos.
- O processo de treinamento envolve o gerenciamento de parâmetros como tamanho do lote, número de etapas e pontos de verificação do modelo para garantir que o modelo aprenda de maneira excellent.
- A exportação do modelo é essencial para usar o modelo de detecção de objetos treinado em um modelo do mundo actual que está sendo empacotado e pronto para implantação.
Perguntas frequentes
R: A API TensorFlow Object Detection é uma estrutura flexível e de código aberto para criar, treinar e implantar modelos personalizados de detecção de objetos. Ele fornece ferramentas para ajustar modelos pré-treinados e criar soluções adaptadas para casos de uso específicos.
R: TFRecord é um formato de arquivo binário otimizado para pipelines do TensorFlow. Ele permite o manuseio eficiente de dados, garantindo carregamento mais rápido, sobrecarga mínima de E/S e treinamento mais suave, especialmente com grandes conjuntos de dados.
R: Esses arquivos permitem a personalização perfeita do modelo, definindo parâmetros como caminhos do conjunto de dados, taxa de aprendizagem, arquitetura do modelo e etapas de treinamento para atender conjuntos de dados específicos e metas de desempenho.
R: Selecione EfficientDet-D0 para um equilíbrio entre precisão e eficiência, excellent para dispositivos de borda, e SSD-MobileNet-V2 para aplicativos leves e rápidos em tempo actual, como aplicativos móveis.
A mídia mostrada neste artigo não é propriedade da Analytics Vidhya e é usada a critério do Autor.
Sou Neha Dwivedi, entusiasta da ciência de dados, formada pela MIT World Peace College, Pune. Sou apaixonado por Information Science e pelas tendências emergentes com ela. Estou animado para compartilhar ideias e aprender com esta comunidade!