Os modelos pequenos estão se tornando rapidamente mais capazes e aplicáveis em uma ampla variedade de casos de uso corporativo. Ao mesmo tempo, cada nova geração de GPU oferece muito mais largura de banda de computação e memória. O resultado? Mesmo sob cargas de trabalho de alta simultaneidade, pequenos LLMs geralmente deixam uma grande fração da computação da GPU e da largura de banda da memória ociosas.
Com casos de uso como conclusão de código, recuperação, correção gramatical ou modelos especializados, nossos clientes corporativos atendem muitos desses modelos de linguagem pequena no Databricks, e estamos constantemente levando as GPUs ao seu limite. Serviço multiprocesso da NVIDIA (MPS) parecia uma ferramenta promissora: ela permite que vários processos de inferência compartilhem um único contexto de GPU, permitindo que suas operações de memória e computação se sobreponham – extraindo efetivamente muito mais trabalho do mesmo {hardware}.
Decidimos testar rigorosamente se o MPS oferece maior rendimento por GPU em nossos ambientes de produção. Descobrimos que o MPS oferece ganhos significativos de rendimento nestes regimes:
- Modelos de linguagem muito pequenos (parâmetros ≤3B) com contexto curto a médio (<2k tokens)
- Modelos de linguagem muito pequenos (<3B) em cargas de trabalho somente pré-preenchidas
- Mecanismos com sobrecarga significativa de CPU
A explicação principal, com base em nossas ablações, é dupla: no nível da GPU, o MPS permite uma sobreposição significativa do kernel quando mecanismos individuais deixam a largura de banda de computação ou memória subutilizada – especialmente durante fases de atenção dominante em modelos pequenos; e, como efeito colateral útil, também pode mitigar gargalos de CPU, como sobrecarga do agendador ou sobrecarga de processamento de imagem em cargas de trabalho multimodais, fragmentando o lote whole entre mecanismos, reduzindo a carga de CPU por mecanismo.
O que é MPS?
O Multi-Course of Service (MPS) da NVIDIA é um recurso que permite que vários processos compartilhem uma única GPU de forma mais eficiente, multiplexando seus kernels CUDA no {hardware}. Como afirma a documentação oficial da NVIDIA:
O Multi-Course of Service (MPS) é uma implementação alternativa e compatível com binário da CUDA Software Programming Interface (API). A arquitetura de tempo de execução do MPS foi projetada para permitir de forma transparente aplicativos CUDA multiprocessos cooperativos.
Em termos mais simples, o MPS fornece uma implementação CUDA compatível com binário dentro do driver que permite que vários processos (como mecanismos de inferência) compartilhem a GPU com mais eficiência. Em vez de processos serializarem o acesso (e deixarem a GPU ociosa entre os turnos), seus kernels e operações de memória são multiplexados e sobrepostos pelo servidor MPS quando os recursos estão disponíveis.
O cenário de expansão: quando o MPS ajuda?
Em uma determinada configuração de {hardware}, a utilização efetiva depende muito do tamanho do modelo, da arquitetura e do comprimento do contexto. Como os grandes modelos recentes de linguagem tendem a convergir para arquiteturas semelhantes, usamos a família de modelos Qwen2.5 como um exemplo representativo para explorar o impacto do tamanho do modelo e do comprimento do contexto.
Os experimentos abaixo compararam dois mecanismos de inferência idênticos executados na mesma GPU NVIDIA H100 (com MPS habilitado) em relação a uma linha de base de instância única, usando cargas de trabalho homogêneas perfeitamente balanceadas.

Principais observações do estudo de escala:
- O MPS oferece aumento de rendimento superior a 50% para modelos pequenos com contextos curtos
- Os ganhos caem log-linearmente à medida que o comprimento do contexto aumenta – para o mesmo tamanho de modelo.
- Os ganhos também diminuem rapidamente à medida que o tamanho do modelo aumenta – mesmo em contextos curtos.
- Para o modelo 7B ou contexto 2k, o benefício cai abaixo de 10% e eventualmente incorre em desaceleração.
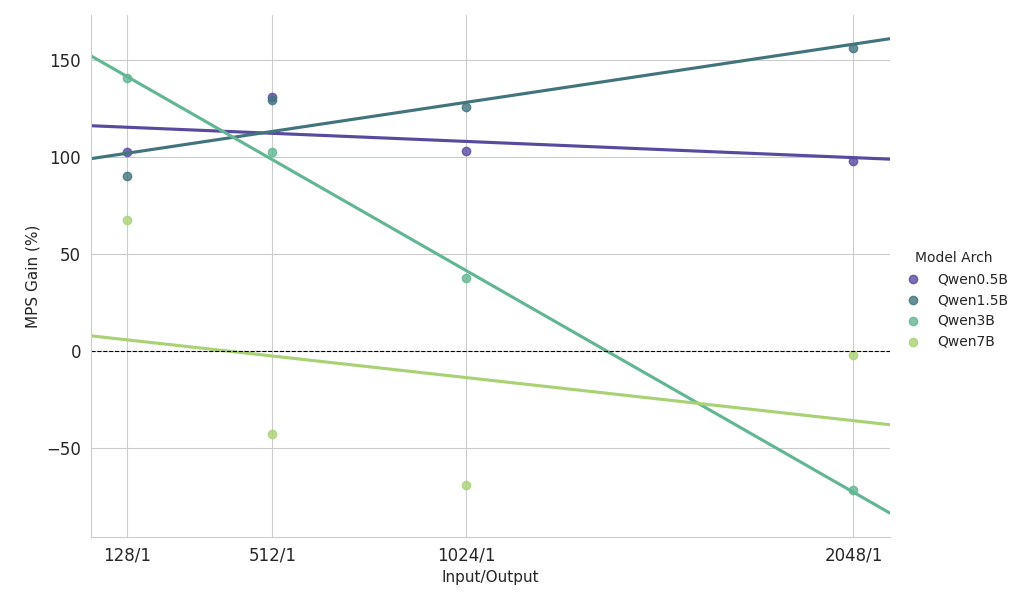
Principais observações do estudo de escalonamento sobre carga de trabalho pesada de pré-preenchimento
- Modelos pequenos (<3B): o MPS oferece consistentemente uma melhoria de rendimento de mais de 100%.
- Modelos de tamanho médio (~3B): Os benefícios diminuem à medida que o comprimento do contexto aumenta, eventualmente levando à regressão do desempenho.
- Modelos grandes (>3B): o MPS não oferece nenhum benefício de desempenho para esses tamanhos de modelo.
Os resultados de dimensionamento acima mostram que os benefícios do MPS são mais pronunciados para configurações de baixa utilização de GPU, modelo pequeno e contexto curto, o que facilita a sobreposição eficaz.
Dissecando os ganhos: de onde realmente vêm os benefícios do MPS?
Para identificar exatamente o porquê, dividimos o problema em dois blocos principais dos transformadores modernos: as camadas MLP (perceptron multicamadas) e o mecanismo de Atenção. Ao isolar cada componente (e remover outros fatores de confusão, como sobrecarga de CPU), poderíamos atribuir os ganhos com mais precisão.
Recursos de GPU necessários | |||
| N = Comprimento do Contexto | Pré-preenchimento (computação) | Decodificação (largura de banda de memória) | Decodificar (computar) |
| MLP | SOBRE) | O(1) | O(1) |
| Atenção | SOBRE(N^2) | SOBRE) | SOBRE) |
Os transformadores consistem em camadas de Atenção e MLP com diferentes comportamentos de escala:
- MLP: Carrega pesos uma vez; processa cada token de forma independente -> Largura de banda de memória constante e cálculo por token.
- Atenção: Carrega o cache KV e calcula o produto escalar com todos os tokens anteriores → Largura de banda da memória linear e cálculo por token.
Com isso em mente, realizamos ablações direcionadas.
Modelos somente MLP (atenção removida)
Para modelos pequenos, a camada MLP pode não saturar a computação mesmo com mais tokens por lote. Isolamos o impacto do MLP removendo o bloqueio de atenção do modelo.
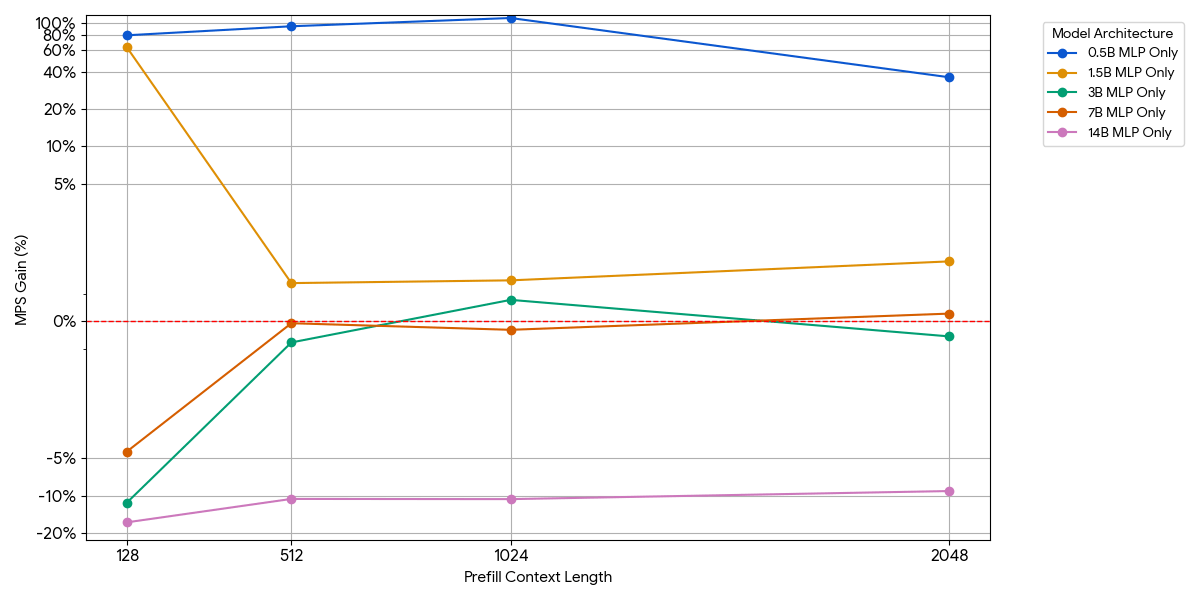
Conforme mostrado na figura acima, os ganhos são modestos e desaparecem rapidamente. À medida que o tamanho do modelo ou o comprimento do contexto aumentam, um único mecanismo já satura a computação (mais FLOPs por token em MLPs maiores, mais tokens com sequências mais longas). Uma vez que um mecanismo está vinculado à computação, a execução de dois mecanismos saturados quase não traz nenhum benefício – 1 + 1 <= 1.
Modelos somente atenção (MLP removido)
Depois de ver ganhos limitados do MLP, pegamos Qwen2.5-3B e medimos a configuração somente atenção de forma análoga.
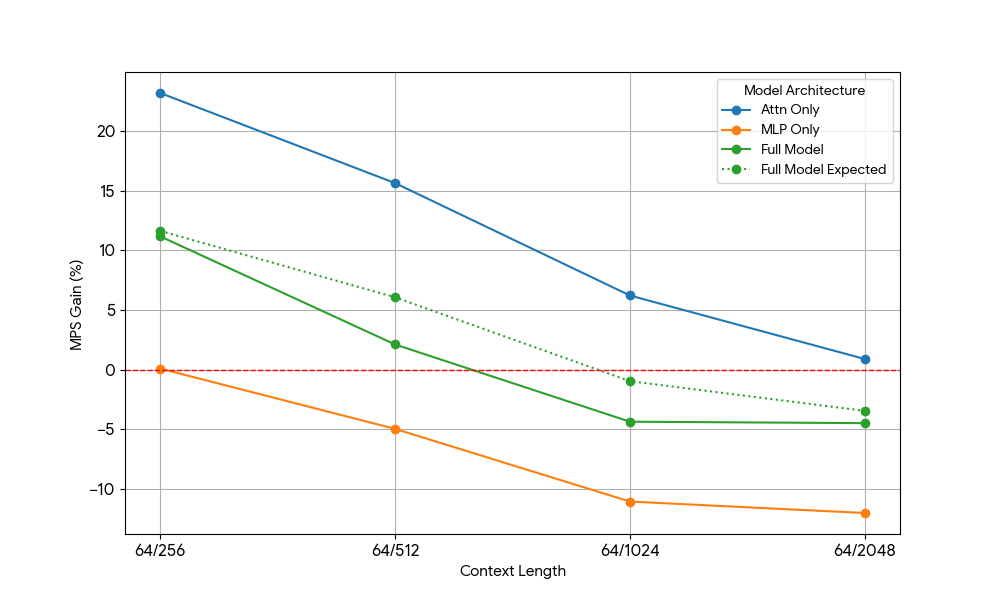
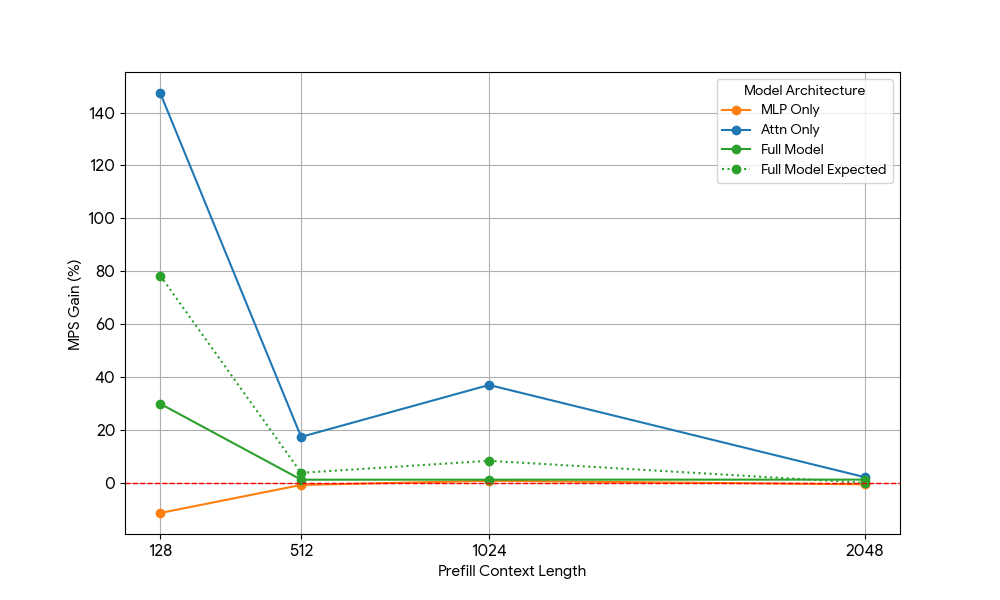
Os resultados foram impressionantes:
- Cargas de trabalho somente atenção mostram ganhos de MPS significativamente maiores do que o modelo completo para pré-preenchimento e decodificação.
- Para decodificação, os ganhos diminuem linearmente com o comprimento do contexto, o que se alinha com nossa expectativa no estágio de decodificação de que os requisitos de recursos para atenção crescem com o comprimento do contexto.
- Para o pré-preenchimento, os ganhos caíram mais rapidamente do que para a decodificação.
O ganho de MPS vem puramente de ganhos de atenção ou há algum efeito de sobreposição de Atenção MLP? Para estudar isso, calculamos o ganho esperado do modelo completo como uma média ponderada de apenas atenção e apenas MLP, sendo os pesos sua contribuição para o tempo de parede. Este ganho esperado do modelo completo é basicamente ganho puramente de sobreposições Attn-Attn e MLP-MLP, embora não leve em consideração a sobreposição Attn-MLP.
Para carga de trabalho de decodificação, o ganho esperado do modelo completo é ligeiramente superior ao ganho actual, o que indica impacto limitado da sobreposição Attn-MLP. Além disso, para carga de trabalho de pré-preenchimento, o ganho actual do modelo completo é muito menor do que os ganhos esperados da sequência 128. A explicação hipotética poderia ser que há menos oportunidades para o kernel de atenção insaturado ser sobreposto porque o outro mecanismo está gastando uma fração significativa de tempo fazendo MLP saturado. Portanto, a maior parte do ganho de MPS vem de 2 motores com atenção insaturada.
Benefício bônus: Recuperando o tempo de GPU perdido devido à sobrecarga da CPU
As ablações acima se concentraram em cargas de trabalho vinculadas à GPU, mas a forma mais grave de subutilização ocorre quando a GPU fica ociosa aguardando o trabalho da CPU – como agendador, tokenização ou pré-processamento de imagem em modelos multimodais.
Em uma configuração de mecanismo único, essas paradas de CPU desperdiçam diretamente os ciclos de GPU. Com o MPS, um segundo mecanismo pode assumir o controle da GPU sempre que o primeiro estiver bloqueado na CPU, transformando o tempo morto em computação produtiva.
Para isolar esse efeito, escolhemos deliberadamente um regime onde os ganhos anteriores no nível da GPU haviam desaparecido: Gemma-4B (um tamanho e comprimento de contexto onde a atenção e o MLP já estão bem saturados, portanto os benefícios da sobreposição do kernel são mínimos).
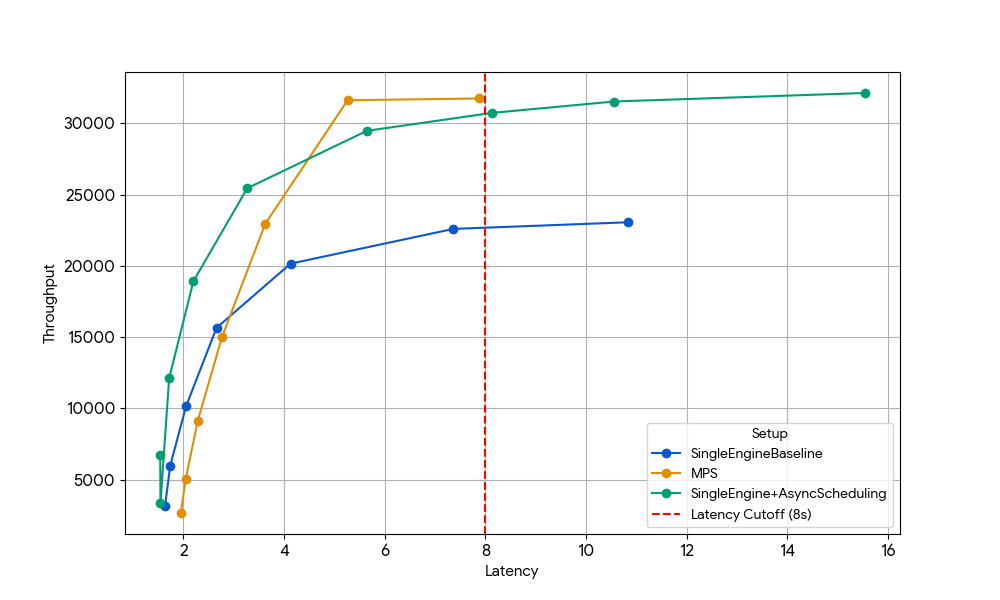
Com uma latência de 8s, o mecanismo único de linha de base (azul) é limitado pela sobrecarga da CPU do agendador, que pode ser aumentada habilitando o agendamento assíncrono no vLLM (linha verde, +33% de rendimento) ou executando dois mecanismos com MPS sem agendamento assíncrono (linha amarela, +35% de rendimento). Esse ganho quase idêntico confirma que, em cenários com restrição de CPU, o MPS pode recuperar essencialmente o mesmo tempo ocioso da GPU que o agendamento assíncrono elimina. O MPS pode ser útil, pois o vanilla vLLM v1.0 ainda tem sobrecarga de CPU na camada do agendador, onde otimizações como agendamento assíncrono não estão totalmente disponíveis.
Uma bala, não uma bala de prata
Com base em nossos experimentos, o MPS pode gerar ganhos significativos para inferência de modelos pequenos em algumas zonas operacionais:
- Mecanismos com sobrecarga significativa de CPU
- Modelos de linguagem muito pequenos (parâmetros ≤3B) com contexto curto a médio (<2k tokens)
- Modelos de linguagem muito pequenos (<3B) em cargas de trabalho com muitos pré-preenchimentos
Fora desses pontos ideais (por exemplo, modelos 7B+, contexto longo >8k ou cargas de trabalho já vinculadas à computação), os benefícios no nível da GPU não podem ser facilmente capturados pelo MPS.
Por outro lado, o MPS também introduziu complexidade operacional:
- Partes móveis extras: daemon MPS, configuração do ambiente do cliente e um roteador/balanceador de carga para dividir o tráfego entre os mecanismos
- Maior complexidade de depuração: sem isolamento entre mecanismos → um vazamento de memória ou OOM em um mecanismo pode corromper ou matar todos os outros que compartilham a GPU
- Carga de monitoramento: agora temos que observar a integridade do daemon, o estado da conexão do cliente, o equilíbrio de carga entre mecanismos, and many others.
- Modos de falha frágeis: como todos os mecanismos compartilham um único contexto CUDA e um único daemon MPS, um único cliente com comportamento inadequado pode corromper ou privar toda a GPU, afetando instantaneamente todos os mecanismos co-localizados.
Resumindo: o MPS é uma ferramenta afiada e especializada — extremamente eficaz nos regimes restritos descritos acima, mas raramente uma vitória de uso geral. Nós realmente gostamos de ultrapassar os limites do compartilhamento de GPU e descobrir onde estão os verdadeiros penhascos de desempenho. Ainda há uma enorme quantidade de desempenho e economia inexplorados em toda a pilha de inferência. Se você está entusiasmado com sistemas de atendimento distribuído ou com fazer com que os LLMs sejam 10 vezes mais baratos na produção, estamos contratando!
Autores: Xiaotong Jiang