

À medida que a análise avançada e a IA continuam a impulsionar a estratégia empresarial, os líderes têm a tarefa de construir pipelines de dados flexíveis e resilientes que aceleram insights confiáveis. O pioneiro da IA, Andrew Ng, ressaltou recentemente que a engenharia de dados é elementary para o sucesso da IA centrada em dados—uma estratégia que prioriza a qualidade dos dados em detrimento da complexidade do modelo. A pesquisa mais recente da McKinsey Quarterly prevê ainda um futuro de “ubiquidade de dados” até 2030onde os dados corporativos são integrados perfeitamente em sistemas, processos e pontos de decisão. Para as empresas, o desafio agora não é apenas a rápida implantação; trata-se de construir processos iterativos e confiáveis que garantam dados acionáveis e de alta qualidade em escala.
O lançamento da versão mais recente da Cloudera Knowledge Engineering em nuvem pública aborda esse desafio crescente, introduzindo grandes melhorias na produtividade de desenvolvimento com ferramentas seguras para empresas, trazendo acesso remoto ao Apache Spark a partir dos ambientes de codificação preferidos do profissional. Este lançamento marca um marco em direção à visão da Cloudera Knowledge Engineering de fornecer as melhores soluções de pipeline e orquestração de nível de produção centradas no profissional.
Um novo nível de produtividade com acesso remoto
O novo Cloudera Knowledge Engineering 1.23 em destaque na nuvem pública Conectividade IDE externaque permite que os engenheiros de dados acessem clusters e pipelines de dados do Apache Spark diretamente de seus ambientes de desenvolvimento preferidos (por exemplo, Jupyter, PyCharm e VS Code). Equipes estendidas de profissionais de dados podem trabalhar em seus ambientes de codificação preferidos sem dependências proprietárias.
Junto com as sessões interativas da Cloudera Knowledge Engineering, as equipes de dados podem colher os benefícios do desenvolvimento iterativo, promovendo fluxos de trabalho iterativos mais colaborativos para impulsionar a qualidade e, ao mesmo tempo, manter padrões de segurança robustos.
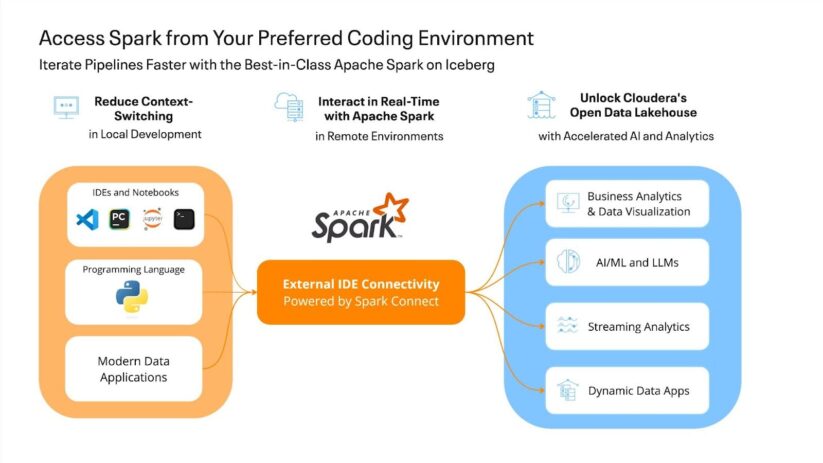
O melhor Apache Spark da categoria no Iceberg
Esta versão também traz novos recursos projetados para melhorar a relação custo-benefício. O suporte para Apache Iceberg 1.5, juntamente com Apache Spark 3.5, oferece melhor desempenho e gerenciamento de custos otimizado. Em casos de uso de Change Knowledge Seize (CDC), exclusões avançadas em nível de linha com Merge-on-Learn melhoram a eficiência da consulta, reduzindo o consumo de recursos e os custos operacionais.
Por que engenharia de dados Cloudera?
Clientes da Cloudera beneficie-se de ferramentas seguras para empresas para criar sandboxes colaborativos, capacitando engenheiros de dados, cientistas de dados e equipes estendidas de profissionais de dados que precisam de insights para orientar decisões. Com 100 vezes mais dados sob gerenciamento em comparação com outros fornecedores somente de nuvem, a Cloudera capacita as empresas a construir information lakehouses abertos para gerenciamento de dados escalonável e seguro com análises portáteis em ambientes de nuvem híbrida.
Os principais inovadores dos setores financeiro, de saúde e de outros setores com uso intensivo de dados confiam na Cloudera Knowledge Engineering por vários motivos:
- Pipelining de dados seguro em ambientes híbridos: Com o Apache Spark como mecanismo, o Cloudera Knowledge Engineering fornece ingestão segura, manipulando dados perfeitamente em diferentes formatos em nuvens híbridas para atender às diversas necessidades dos pipelines de dados modernos. Alimentado por serviços de plataforma integrados, o Cloudera Knowledge Engineering garante governança de dados com tratamento robusto de dados e rastreamento automatizado de linhagem do ciclo de vida.
- Fluxos de trabalho simplificados e colaborações iterativas: Com o Apache Airflow, a Cloudera Knowledge Engineering fornece integrações de API para ferramentas de dados externas como dbt. Sessões interativas e a mais recente conectividade IDE externa suportam iterações e colaborações rápidas.
- Interoperabilidade de dados com menor TCO: Cloudera Knowledge Engineering tem suporte nativo para Iceberg Apache – o principal formato de tabela aberta desenvolvido especificamente para gerenciar information lakes em escala de exabytes e fornecer consultas de alto desempenho. Ao contrário dos fornecedores de nuvem com mecanismos proprietários, a Cloudera Knowledge Engineering otimiza a eficiência de custos aproveitando tecnologias de código aberto e serviços de plataforma integrados, como Observabilidade Cloudera.
Pronto para explorar?
Descubra como a Cloudera Knowledge Engineering pode acelerar o tempo de obtenção de valor na construção de arquiteturas de dados modernas preparadas para o futuro: