Introdução: Analítica e operações estão convergindo
Hoje, os aplicativos não podem confiar apenas em eventos brutos. Eles precisam de dados com curadoria, contextual e acionável, da Lakehouse para a personalização de energia, a automação e as experiências inteligentes do usuário.
Entregar esses dados de maneira confiável com baixa latência tem sido um desafio, geralmente exigindo pipelines complexos e infraestrutura personalizada.
Lakebase, anunciada recentemente pela Databricks, aborda esse problema. Ele combina um banco de dados Postgres de alto desempenho com integração nativa de Lakehouse, tornando o ETL reverso simples e confiável.
O que é ETL reverso?
O ETL reverso sincroniza dados de alta qualidade de uma casa de lago nos sistemas operacionais que alimentam aplicações. Isso garante que conjuntos de dados confiáveis e informações orientadas a IA fluam diretamente para aplicativos que personalizam a personalização, recomendações, detecção de fraude e decisão em tempo actual.
Sem o ETL reverso, as idéias permanecem na casa de Lakehouse e não atingem as aplicações que precisam delas. O Lakehouse é onde os dados são limpos, enriquecidos e transformados em análises, mas não são construídos para interações de aplicativos de baixa latência ou cargas de trabalho transacionais. É aí que entra o LakeBase, fornecendo dados confiáveis de Lakehouse diretamente nas ferramentas em que ele conduz a ação, sem pipelines personalizados.
Na prática, o ETL reverso normalmente envolve quatro componentes principais, todos integrados ao LakeBase:
- Lakehouse: Dados com curadoria de lojas usadas para direcionar decisões, como tabelas agregadas no nível dos negócios (também conhecidas como “tabelas de ouro”), recursos de engenharia e saídas de inferência de ML.
- PIPELINES DE SINCIMENTO: Mova dados relevantes para lojas operacionais com agendamento, garantias de frescura e monitoramento.
- Banco de dados operacional: Otimizado para transações de alta simultaneidade, baixa latência e ácido.
- Aplicações: O destino ultimate em que as idéias se tornam ação, seja em aplicativos voltados para o cliente, ferramentas internas, APIs ou painéis.

Desafios do ETL reverso hoje
O ETL reverso parece simples, mas na prática, a maioria das equipes enfrenta os mesmos desafios:
- Pipelines ETL quebradiços e personalizados: Esses pipelines geralmente requerem infraestrutura de streaming, gerenciamento de esquema, manuseio de erros e orquestração. Eles são quebradiços e intensivos em recursos de manter.
- Múltiplos sistemas desconectados: Pilhas separadas para análises e operações significam mais infraestrutura para gerenciar, mais camadas de autenticação e mais probabilities de incompatibilidades de formato.
- Modelos de governança inconsistentes: Os sistemas analíticos e operacionais geralmente vivem em diferentes domínios políticos, dificultando a aplicação de controles de qualidade e políticas de auditoria consistentes.
Esses desafios criam atrito para os desenvolvedores e para os negócios, diminuindo os esforços para ativar de maneira confiável dados e fornecer aplicativos inteligentes e em tempo actual.
Lakebase: integrado por padrão para fácil ETL reverso
O LakeBase take away essas barreiras e transforma o ETL reverso em um fluxo de trabalho integrado e totalmente gerenciado. Ele combina um motor Postgres de alto desempenho, integração profunda de Lakehouse e sincronização de dados interna, para que novas idéias fluam para aplicações sem infraestrutura additional.
Essas capacidades do lago são especialmente valiosas para o ETL reverso:
- Integração profunda de Lakehouse: Dados de sincronização de mesas de Lakehouse até LakeBase em um instantâneo, programado ou contínuo, sem construir ou gerenciar trabalhos de ETL externos. Isso substitui a complexidade de dutos personalizados, tentativas e monitoramento por uma experiência gerenciada nativa.
- PostGres totalmente gerenciado: Construído no Postgres de código aberto, o Lakebase suporta transações ácidas, índices, junções e extensões como pós -gis e pgvector. Você pode se conectar com drivers e ferramentas existentes como PGADMIN ou JDBC, evitando a necessidade de aprender novas tecnologias de banco de dados ou manter a infraestrutura OLTP separada.
- Arquitetura escalável e resiliente: Lakebase separa a computação e armazenamento para escala independente, fornecendo latência de consulta abaixo de 10 ms e milhares de QPs. Os recursos da qualidade corporativa incluem alta disponibilidade multi-az, recuperação ponto-tempo e armazenamento criptografado, remoção dos desafios de escala e resiliência dos bancos de dados auto-gerenciados.
- Segurança e Governança Integrada: Registre o LakeBase no Catálogo da Unity para trazer dados operacionais para sua estrutura de governança centralizada, cobrindo trilhas e permissões de auditoria no nível do catálogo. O acesso by way of protocolo Postgres ainda usa funções e permissões nativas de Postgres, garantindo segurança transacional autêntica enquanto se encaixa no seu modelo de governança de banco de dados mais amplo.
- Arquitetura agnóstica em nuvem: Implante Lakebase ao lado de sua casa Lakehouse em seu ambiente de nuvem preferido sem re-arquitetar seus fluxos de trabalho.
Com esses recursos na plataforma de inteligência de dados do Databricks, a LakeBase substitui a configuração ETL reversa fragmentada que se baseia em pipelines personalizados, sistemas OLTP independentes e governança separada. Ele oferece um serviço integrado, de alto desempenho e seguro, garantindo que as idéias analíticas fluam para aplicações mais rapidamente, com menos esforço operacional e com a governança preservada.
Caso de uso da amostra: Construindo um portal de suporte inteligente com a Lakebase
Como exemplo prático, vamos percorrer como construir um portal de suporte inteligente alimentado pela Lakebase. Este portal interativo ajuda a apoiar as equipes a lidar com os incidentes de entrada usando idéias orientadas por ML da Lakehouse, como risco de escalação previsto e ações recomendadas, permitindo que os usuários atribuam propriedade, standing de rastreamento e deixem comentários em cada ticket.
Lakebase torna isso possível sincronizando as previsões no Postgres, além de armazenar atualizações do aplicativo. O resultado é um portal de suporte que combina análises com operações ao vivo. A mesma abordagem se aplica a muitos outros casos de uso, incluindo mecanismos de personalização e painéis orientados a ML.
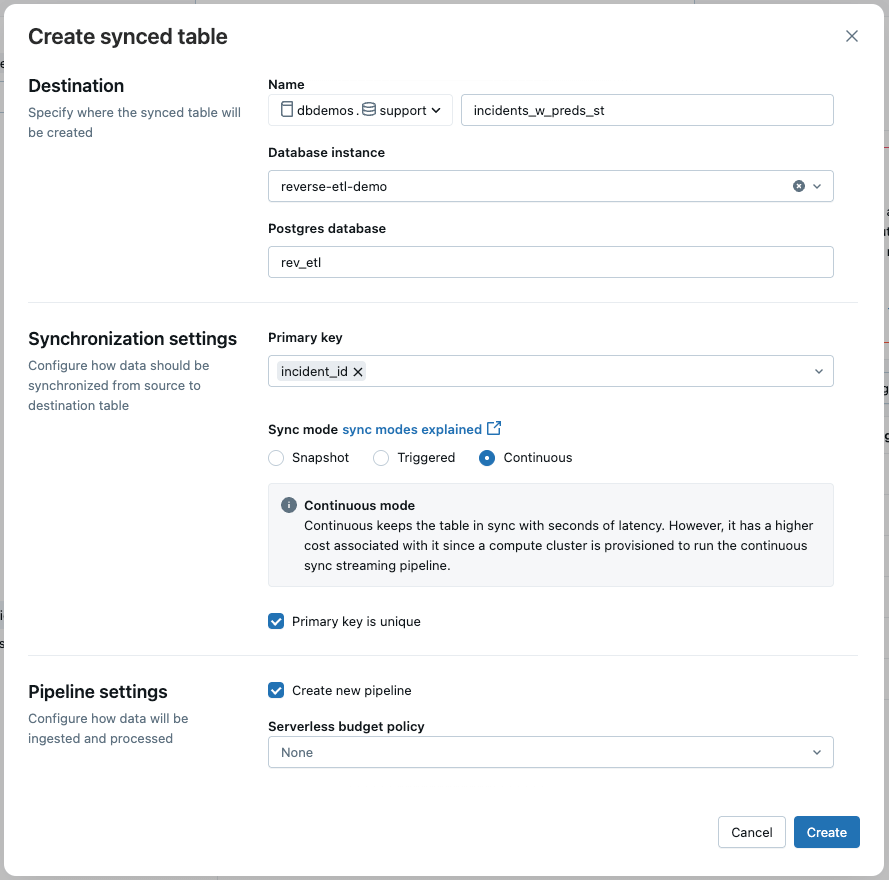
Etapa 1: Previsões de sincronização do lago a LakeBase
Os dados de incidentes, enriquecidos com previsões de ML, vive em uma tabela Delta e são atualizados quase em tempo actual por meio de um pipeline de streaming. Para alimentar o aplicativo de suporte, usamos o Lakebase Reverse ETL para sincronizar continuamente esta tabela Delta com uma tabela Postgres.
Na interface do usuário, selecionamos:
- Modo de sincronização: contínuo para atualizações de baixa latência
- Chave primária: incident_id
Isso garante que o aplicativo reflita os dados mais recentes com atraso mínimo.
NOTA: Você também pode criar o pipeline de sincronização programaticamente usando o SDK do Databricks.
Etapa 2: Crie uma tabela de estado para entradas do usuário
O aplicativo de suporte também precisa de uma tabela para armazenar dados digitados pelo usuário, como propriedade, standing e comentários. Como esses dados são escritos no aplicativo, eles devem entrar em uma tabela separada no lago (em vez da tabela sincronizada).
Aqui está o esquema:
Esse design garante que o ETL reverso permaneça unidirecional (Lakehouse → Lakebase), enquanto ainda permite atualizações interativas por meio do aplicativo.
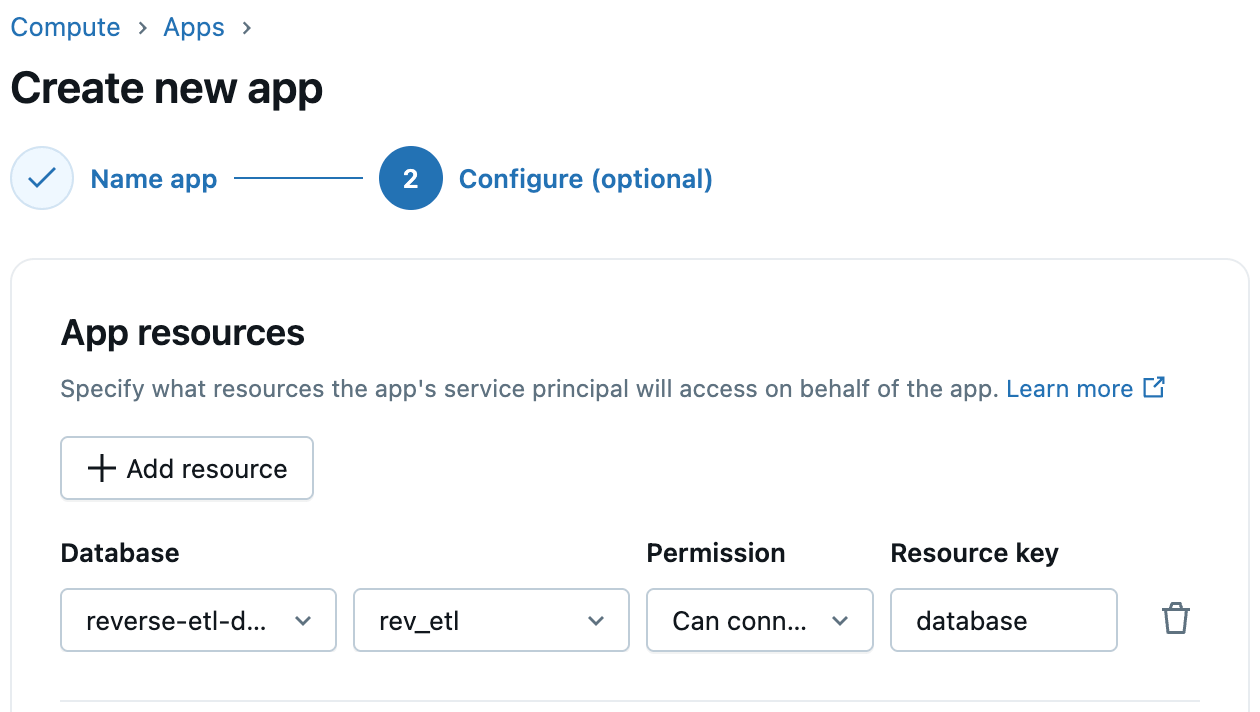
Etapa 3: Configurar acesso à base de lago em aplicativos Databricks
Os aplicativos Databricks suportam a integração de primeira classe com a LakeBase. Ao criar seu aplicativo, basta adicionar o LakeBase como um recurso de aplicativo e selecionar a instância e o banco de dados do LakeBase. Os Databricks providenciam automaticamente uma função Postgres correspondente para o diretor de serviço do aplicativo, simplificando a conectividade aplicativo para o Database. Você pode conceder a essa função o banco de dados, esquema e permissões de tabela necessários.
Etapa 4: implante seu código de aplicativo
Com seus dados sincronizados e permissões, agora você pode implantar o aplicativo Flask que alimenta o portal de suporte. O aplicativo se conecta à LakeBase by way of Postgres e serve um painel rico com gráficos, filtros e interatividade.
Conclusão
Trazer informações analíticas para aplicações operacionais não precisa mais ser um processo complexo e quebradiço. Com o LakeBase, o RERTE ETL se torna uma capacidade totalmente gerenciada e integrada. Ele combina o desempenho de um mecanismo Postgres, a confiabilidade de uma arquitetura escalável e a governança da plataforma Databricks.
Esteja você alimentando um portal de suporte inteligente ou construindo outras experiências em tempo actual e orientadas a dados, a Base LakeSe reduz a sobrecarga da engenharia e acelera o caminho da perception à ação.
Para saber mais sobre como Crie tabelas sincronizadas No Lakebase, confira nossa documentação e comece hoje.