Esta postagem mostra como o Amazon EMR 7.12 pode tornar suas cargas de trabalho Apache Spark e Iceberg com desempenho até 4,5x mais rápido.
O Tempo de execução do Amazon EMR para Apache Spark fornece um ambiente de execução de alto desempenho com compatibilidade complete de API com código aberto Apache Faísca e Iceberg Apache. Amazon EMR no EC2, Amazon EMR sem servidor, Amazon EMR no Amazon EKS, Amazon EMR no AWS Outposts e Cola AWS use os tempos de execução otimizados.
Nossos benchmarks mostram que o Amazon EMR 7.12 executa cargas de trabalho TPC-DS de 3 TB 4,5x mais rápido que o Spark 3.5.6 de código aberto com Iceberg 1.10.0.
As melhorias de desempenho incluem otimizações para cache de metadados, E/S paralela, planejamento de consulta adaptável, manipulação de tipos de dados e tolerância a falhas. Houve também algumas regressões específicas do Iceberg em torno de varreduras de dados que identificamos e corrigimos.
Essas otimizações permitem igualar o desempenho do Parquet no Amazon EMR, mantendo os principais recursos do Iceberg: transações ACID, viagem no tempo e evolução de esquema.
Resultados de benchmark em comparação com código aberto
Para avaliar o desempenho do motor Spark com o formato de tabela Iceberg, realizamos testes de benchmark utilizando o Conjunto de dados TPC-DS de 3 TB, versão 2.13um benchmark padrão in style da indústria. Testes de benchmark para o tempo de execução do Amazon EMR para Apache Spark e Apache Iceberg foram realizados em clusters do Amazon EMR 7.12 EC2 em comparação com o Apache Spark 3.5.6 de código aberto e o Apache Iceberg 1.10.0 em clusters do EC2.
Observação: Nossos resultados derivados do conjunto de dados TPC-DS não são diretamente comparáveis aos resultados oficiais do TPC-DS devido a diferenças de configuração.
As instruções de configuração e detalhes técnicos estão disponíveis em nosso Repositório GitHub. Para minimizar a influência de catálogos externos como Cola AWS e Hive, utilizamos o catálogo Hadoop para as tabelas Iceberg. Isso usa o sistema de arquivos subjacente, especificamente o Amazon S3, como catálogo. Podemos definir esta configuração configurando a propriedade spark.sql.catalog.. As tabelas de fatos usaram o particionamento padrão pela coluna de information, que varia de 200 a 2.100 partições. Nenhuma estatística pré-calculada foi usada para essas tabelas.
Executamos um complete de 104 consultas SparkSQL em 3 rodadas sequenciais, e o tempo médio de execução de cada consulta nessas rodadas foi obtido para comparação. O tempo médio de execução das três rodadas no Amazon EMR 7.12 com o Iceberg habilitado foi de 0,37 horas, demonstrando um aumento de velocidade de 4,5x em comparação com o Spark 3.5.6 de código aberto e o Iceberg 1.10.0. A figura a seguir apresenta os tempos totais de execução em segundos.

A tabela a seguir resume as métricas.
| Métrica | Amazon EMR 7.12 no EC2 | Amazon EMR 7.5 no EC2 | Código aberto Apache Spark 3.5.6 e Apache Iceberg 1.10.0 |
| Tempo médio de execução em segundos | 1349,62 | 1535,62 | 6113.92 |
| Média geométrica das consultas em segundos | 7.45910 | 8.30046 | 22.31854 |
| Custo* | US$ 4,81 | US$ 5,47 | US$ 17,65 |
*Estimativas de custos detalhadas são discutidas posteriormente nesta postagem.
O gráfico a seguir demonstra a melhoria de desempenho por consulta do Amazon EMR 7.12 em relação ao Spark 3.5.6 de código aberto e ao Iceberg 1.10.0. A extensão da aceleração varia de uma consulta para outra, com a mais rápida até 13,6x mais rápida para q23b, com o Amazon EMR superando o Spark de código aberto com tabelas Iceberg. O eixo horizontal organiza as consultas de benchmark do TPC-DS 3TB em ordem decrescente com base na melhoria de desempenho observada com o Amazon EMR, e o eixo vertical representa a magnitude dessa aceleração como uma proporção.
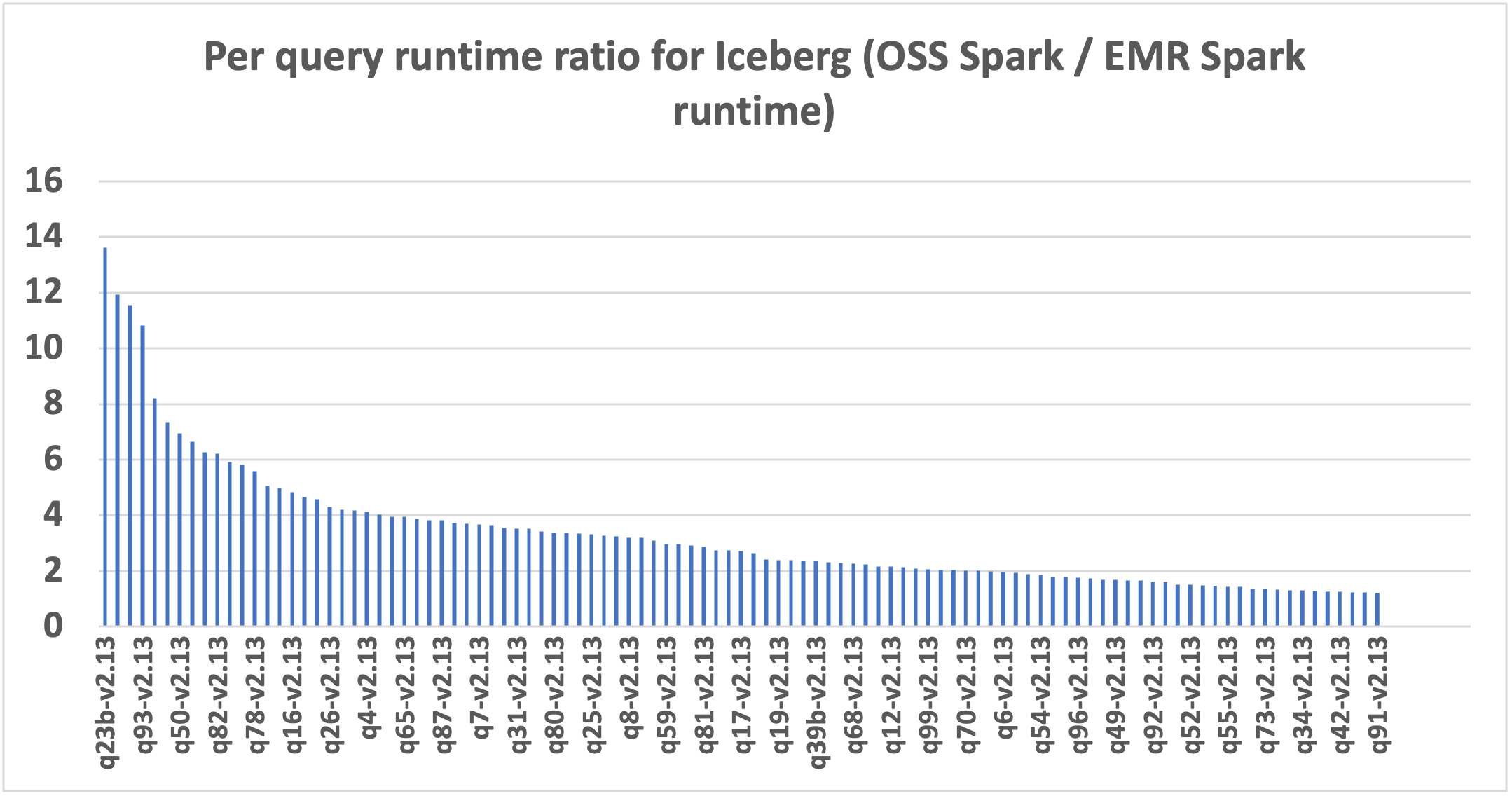
Análise da comparação de custos
Nosso benchmark fornece dados de tempo de execução complete e média geométrica para avaliar o desempenho do Spark e do Iceberg em um cenário complexo de suporte à decisão do mundo actual. Para obter informações adicionais, também examinamos o aspecto do custo. Calculamos estimativas de custos usando fórmulas que levam em conta instâncias sob demanda do EC2, Loja de blocos elásticos da Amazon (Amazon EBS) e despesas do Amazon EMR.
- Custo do Amazon EC2 (inclui custo de SSD) = número de instâncias * taxa horária r5d.4xlarge * tempo de execução do trabalho em horas
- Taxa horária 4xgrande = US$ 1,152 por hora
- Custo raiz do Amazon EBS = número de instâncias * Amazon EBS por taxa horária de GB * tamanho do quantity raiz EBS * tempo de execução do trabalho em horas
- Custo do Amazon EMR = número de instâncias * r5d.4xlarge Custo do Amazon EMR * tempo de execução do trabalho em horas
- Custo 4xlarge do Amazon EMR = US$ 0,27 por hora
- Custo complete = custo do Amazon EC2 + custo raiz do Amazon EBS + custo do Amazon EMR
Os cálculos revelam que o benchmark Amazon EMR 7.12 produz uma melhoria de eficiência de custos de 3,6x em relação ao Spark 3.5.6 de código aberto e ao Iceberg 1.10.0 na execução do trabalho de benchmark.
| Métrica | Amazon EMR 7.12 | Amazon EMR 7.5 | Código aberto Apache Spark 3.5.6 e Apache Iceberg 1.10.0 |
| Tempo de execução em segundos | 1349,62 | 1535,62 | 6113.92 |
Número de instâncias EC2 (Inclui nó primário) | 9 | 9 | 9 |
| Tamanho do Amazon EBS | 20 GB | 20 GB | 20 GB |
Amazon EC2 (Custo complete do tempo de execução) | US$ 3,89 | US$ 4,42 | US$ 17,61 |
| Custo do Amazon EBS | US$ 0,01 | US$ 0,01 | US$ 0,04 |
| Custo do Amazon EMR | US$ 0,91 | US$ 1,04 | US$ 0 |
| Custo complete | US$ 4,81 | US$ 5,47 | US$ 17,65 |
| Economia de custos | Amazon EMR 7.12 é 3,6x melhor | Amazon EMR 7.5 é 3,2x melhor | Linha de base |
Além das métricas baseadas em tempo discutidas até agora, os dados dos logs de eventos do Spark mostram que o Amazon EMR digitalizou aproximadamente 4,3 vezes menos dados do Amazon S3 e 5,3 vezes menos registros do que a versão de código aberto no benchmark TPC-DS de 3 TB. Essa redução na verificação de dados do Amazon S3 contribui diretamente para a economia de custos das cargas de trabalho do Amazon EMR.
Execute benchmarks de código aberto do Apache Spark em tabelas do Apache Iceberg
Usamos clusters EC2 separados, cada um equipado com nove instâncias r5d.4xlarge, para testar o Spark 3.5.6 de código aberto e o Amazon EMR 7.12 para carga de trabalho Iceberg. O nó primário estava equipado com 16 vCPU e 128 GB de memória, e os 8 nós de trabalho juntos tinham 128 vCPU e 1.024 GB de memória. Realizamos testes usando as configurações padrão do Amazon EMR para mostrar a experiência típica do usuário e ajustamos minimamente as configurações do Spark e do Iceberg para manter uma comparação equilibrada.
A tabela a seguir resume as configurações do Amazon EC2 para o nó primário e oito nós de trabalho do tipo r5d.4xlarge.
| Instância EC2 | vCPU | Memória (GiB) | Armazenamento de instância (GB) | Quantity raiz do EBS (GB) |
| r5d.4xgrande | 16 | 128 | 2 SSDs de 300 NVMe | 20 GB |
Pré-requisitos
Os seguintes pré-requisitos são necessários para executar o benchmarking:
- Usando as instruções do Repositório GitHub emr-spark-benchmarkconfigure os dados de origem TPC-DS no bucket S3 e no computador native.
- Crie o aplicativo de benchmark seguindo as etapas fornecidas em Etapas para construir um aplicativo spark-benchmark-assembly e copie o aplicativo de benchmark para seu bucket S3. Alternativamente, copie spark-benchmark-assembly-3.5.6.jar para o seu balde S3.
- Crie tabelas Iceberg a partir dos dados de origem do TPC-DS. Siga as instruções em GitHub para criar tabelas Iceberg usando o catálogo Hadoop. Por exemplo, o código a seguir usa um cluster do Amazon EMR 7.12 com Iceberg habilitado para criar as tabelas:
Observação: o native do warehouse do catálogo Hadoop e o nome do banco de dados da etapa anterior. Usamos as mesmas tabelas Iceberg para executar benchmarks com o Amazon EMR 7.12 e o Spark de código aberto.
Este aplicativo de benchmark é construído a partir do ramo tpcds-v2.13_iceberg. Se você estiver criando um novo aplicativo de benchmark, alterne para o department correto depois de baixar o código-fonte do repositório GitHub.
Crie e configure um cluster YARN no Amazon EC2
Para comparar o desempenho do Iceberg entre o Amazon EMR no Amazon EC2 e o Spark de código aberto no Amazon EC2, siga as instruções no Repositório GitHub emr-spark-benchmark para criar um cluster Spark de código aberto no Amazon EC2 usando Flintrock com 8 nós de trabalho.
Com base na seleção do cluster para este teste, as seguintes configurações são usadas:
Certifique-se de substituir o espaço reservado
Execute o benchmark TPC-DS com Apache Spark 3.5.6 e Apache Iceberg 1.10.0
Conclua as etapas a seguir para executar o benchmark TPC-DS:
- Faça login no nó primário do cluster de código aberto usando
flintrock login $CLUSTER_NAME. - Envie seu trabalho do Spark:
- Escolha o native correto do armazém do catálogo Iceberg e o banco de dados que contém as tabelas Iceberg criadas.
- Os resultados são criados em
s3://./benchmark_run - Você pode acompanhar o progresso em
/media/ephemeral0/spark_run.log.
Resuma os resultados
Após a conclusão do trabalho do Spark, recupere o arquivo de resultado do teste do bucket S3 de saída em s3://. Isso pode ser feito por meio do console do Amazon S3 navegando até o native do bucket especificado ou usando o comando Interface de linha de comando da Amazone (AWS CLI). O aplicativo de benchmark Spark organiza os dados criando uma pasta de carimbo de information/hora e colocando um arquivo de resumo em uma pasta chamada abstract.csv. Os arquivos CSV de saída contêm 4 colunas sem cabeçalhos:
- Nome da consulta
- Tempo médio
- Tempo mínimo
- Tempo máximo
Com os dados de 3 execuções de teste separadas com 1 iteração de cada vez, podemos calcular a média e a média geométrica dos tempos de execução de benchmark.
Execute o benchmark TPC-DS com o tempo de execução do Amazon EMR para Apache Spark
A maioria das instruções é semelhante a Etapas para executar o Spark Benchmarking com alguns detalhes específicos do Iceberg.
Pré-requisitos
Conclua as seguintes etapas de pré-requisito:
- Correr
aws configurepara configurar o shell da AWS CLI para apontar para a conta da AWS de benchmarking. Consulte Configurar a AWS CLI para obter instruções. - Carregue o arquivo JAR do aplicativo de benchmark no Amazon S3.
Implante o cluster do Amazon EMR e execute o trabalho de benchmark
Conclua as etapas a seguir para executar o trabalho de referência:
- Use o comando AWS CLI conforme mostrado em Implante o EMR no cluster EC2 e execute o trabalho de benchmark para implantar um Amazon EMR no cluster EC2. Certifique-se de ativar o Iceberg. Ver Crie um cluster Iceberg para mais detalhes. Escolha a versão correta do Amazon EMR, o tamanho do quantity raiz e a mesma configuração de recursos da configuração do Flintrock de código aberto. Consulte criar cluster para obter uma descrição detalhada das opções da AWS CLI.
- Armazene o ID do cluster da resposta. Precisamos disso para a próxima etapa.
- Envie o trabalho de referência no Amazon EMR usando
add-stepsda AWS CLI:- Substituir
- A aplicação de benchmark está em
s3://./spark-benchmark-assembly-3.5.6.jar - Escolha o native correto do armazém do catálogo Iceberg e o banco de dados que contém as tabelas Iceberg criadas. Deve ser o mesmo usado para a execução do benchmark TPC-DS de código aberto.
- Os resultados estarão em
s3://./benchmark_run
- Substituir
Resuma os resultados
Após a conclusão da etapa, você poderá ver o resultado resumido do benchmark em s3:// da mesma forma que na execução anterior e calcule a média e a média geométrica dos tempos de execução da consulta.
Limpar
Para ajudar a evitar cobranças futuras, exclua os recursos criados seguindo as instruções fornecidas no Seção de limpeza do repositório GitHub.
Resumo
O Amazon EMR otimiza o tempo de execução do Spark quando usado com tabelas Iceberg, alcançando desempenho 4,5 vezes mais rápido que o Apache Spark 3.5.6 de código aberto e o Apache Iceberg 1.10.0 com o Amazon EMR 7.12 no TPC-DS 3 TB, v2.13. Isso representa um avanço significativo em relação ao Amazon EMR 7.5, que proporcionou desempenho 3,6x mais rápido e preenche a lacuna em relação ao desempenho do parquet no Amazon EMR para que os clientes possam usar os benefícios do Iceberg sem prejudicar o desempenho.
Incentivamos você a se manter atualizado com as versões mais recentes do Amazon EMR para aproveitar ao máximo as melhorias contínuas de desempenho.
Para se manter informado, inscreva-se no Feed RSS do weblog de Huge Information da AWSonde você pode encontrar atualizações sobre o tempo de execução do Amazon EMR para Spark e Iceberg, bem como dicas sobre práticas recomendadas de configuração e recomendações de ajuste.
Sobre os autores
 Atul Félix Payapilly é engenheiro de desenvolvimento de software program do Amazon EMR na Amazon Internet Companies.
Atul Félix Payapilly é engenheiro de desenvolvimento de software program do Amazon EMR na Amazon Internet Companies.
 Akshaya KP é engenheiro de desenvolvimento de software program do Amazon EMR na Amazon Internet Companies.
Akshaya KP é engenheiro de desenvolvimento de software program do Amazon EMR na Amazon Internet Companies.
 Hari Kishore Chaparala é engenheiro de desenvolvimento de software program do Amazon EMR na Amazon Internet Companies.
Hari Kishore Chaparala é engenheiro de desenvolvimento de software program do Amazon EMR na Amazon Internet Companies.
 Giovanni Matteo é gerente sênior do grupo Amazon EMR Spark e Iceberg.
Giovanni Matteo é gerente sênior do grupo Amazon EMR Spark e Iceberg.