Tempo de execução do Amazon EMR para Apache Spark oferece um ambiente de execução de alto desempenho, mantendo a compatibilidade da API com código aberto Apache Faísca e Iceberg Apache formato de tabela. Amazon EMR no EC2, Amazon EMR sem servidor, Amazon EMR no Amazon EKS, Amazon EMR no AWS Outposts e Cola AWS use os tempos de execução otimizados.
Nesta postagem, demonstramos os benefícios de desempenho de gravação do uso do tempo de execução do Amazon EMR 7.12 para Spark e Iceberg em comparação com o Spark 3.5.6 de código aberto com tabelas Iceberg 1.10.0 em uma carga de trabalho de mesclagem de 3 TB.
Escrever metodologia de benchmark
Nossos benchmarks demonstram que o Amazon EMR 7.12 pode executar cargas de trabalho de mesclagem de 3 TB duas vezes mais rápido do que o Spark 3.5.6 de código aberto com Iceberg 1.10.0, proporcionando melhorias significativas para ingestão de dados e pipelines ETL, ao mesmo tempo em que fornece os recursos avançados do Iceberg, incluindo transações ACID, viagem no tempo e evolução de esquema.
Carga de trabalho de referência
Para avaliar as melhorias no desempenho de gravação no Amazon EMR 7.12, escolhemos uma carga de trabalho de mesclagem que reflete padrões comuns de ingestão de dados e ETL. O benchmark consiste em 37 operações básicas de mesclagem em tabelas TPC-DS de 3 TB, testando o desempenho das operações INSERT, UPDATE e DELETE. A carga de trabalho é inspirada em abordagens de benchmarking estabelecidas da comunidade de código aberto, incluindo a metodologia de benchmark de fusão da Delta Lake e a estrutura LST-Bench. Combinamos e adaptamos essas abordagens para criar um teste abrangente de desempenho de gravação do Iceberg na AWS. Também começamos com um foco inicial apenas no desempenho de cópia na gravação.
Características da carga de trabalho
O benchmark executa 37 consultas básicas de mesclagem sequencial que modificam tabelas de fatos TPC-DS. As 37 consultas estão organizadas em três categorias:
- Inserções (consultas m1-m6): adição de novos registros a tabelas com volumes de dados variados. Essas consultas usam tabelas de origem com 5 a 100% de novos registros e zero correspondências, testando o desempenho puro da inserção em diferentes escalas.
- Upserts (consultas m8-m16): Modificando registros existentes ao inserir novos. Essas operações de upsert combinam diferentes proporções de registros correspondentes e não correspondentes — por exemplo, correspondências de 1% com inserções de 10% ou correspondências de 99% com inserções de 1% — representando cenários típicos em que os dados são atualizados e aumentados.
- Exclusões (consultas m7, m17-m37): Removendo registros com seletividade variável. Elas variam desde exclusões pequenas e direcionadas que afetam 5% dos arquivos e linhas até exclusões em grande escala, incluindo exclusões em nível de partição que podem ser otimizadas para operações somente de metadados.
As consultas operam no estado da tabela criado por operações anteriores, simulando pipelines ETL reais onde as etapas subsequentes dependem de transformações anteriores. Por exemplo, as primeiras seis consultas inserem entre 607.000 e 11,9 milhões de registros no web_returns mesa. Consultas posteriores são atualizadas e excluídas dessa tabela modificada, testando o desempenho de leitura após gravação. As tabelas de origem foram geradas por amostragem do TPC-DS web_returns tabela com proporções controladas de correspondência/não correspondência para condições de teste consistentes em todas as execuções de benchmark.
As operações de mesclagem variam em escala e complexidade:
- Pequenas operações que afetam 607.000 registros
- Grandes operações modificando mais de 12 milhões de registros
- Exclusões seletivas que exigem reescritas de arquivos
- Exclusões em nível de partição otimizadas para operações de metadados
Configuração de referência
Executamos o benchmark em {hardware} idêntico para Amazon EMR 7.12 e Spark 3.5.6 de código aberto com Iceberg 1.10.0:
- Conjunto: 9 instâncias r5d.4xlarge (1 primária, 8 de trabalho)
- Calcular: 144 vCPUs no whole, 1.152 GB de memória
- Armazenar: 2 SSD NVMe de 300 GB por instância
- Catálogo: Catálogo Hadoop
- Formato de dados: Arquivos Parquet no Amazon S3
- Formato de tabela: Apache Iceberg (padrão: modo copiar na gravação)
Resultados de referência
Comparamos os resultados de benchmark do Amazon EMR 7.12 com os de código aberto Spark 3.5.6 e Iceberg 1.10.0. Executamos as 37 consultas de mesclagem em três iterações sequenciais, e o tempo de execução médio nessas iterações foi obtido para comparação. A tabela a seguir mostra a média dos resultados em três iterações:
| Amazon EMR 7.12 (segundos) | Open Supply Spark 3.5.6 + Iceberg 1.10.0 (segundos) | Aceleração |
| 443,58 | 926,63 | 2,08x |
O tempo de execução médio para as três iterações no Amazon EMR 7.12 com Iceberg habilitado foi de 443,58 segundos, demonstrando um aumento de velocidade de 2,08x em comparação ao Spark 3.5.6 de código aberto e ao Iceberg 1.10.0. A figura a seguir apresenta os tempos totais de execução em segundos.

A tabela a seguir resume as métricas.
| Métrica | Amazon EMR 7.12 no EC2 | Código aberto Spark 3.5.6 e Iceberg 1.10.0 |
| Tempo médio de execução em segundos | 443,58 | 926,63 |
| Média geométrica das consultas em segundos | 6.40746 | 18.50945 |
| Custo* | US$ 1,58 | US$ 2,68 |
*Estimativas de custos detalhadas são discutidas posteriormente nesta postagem.
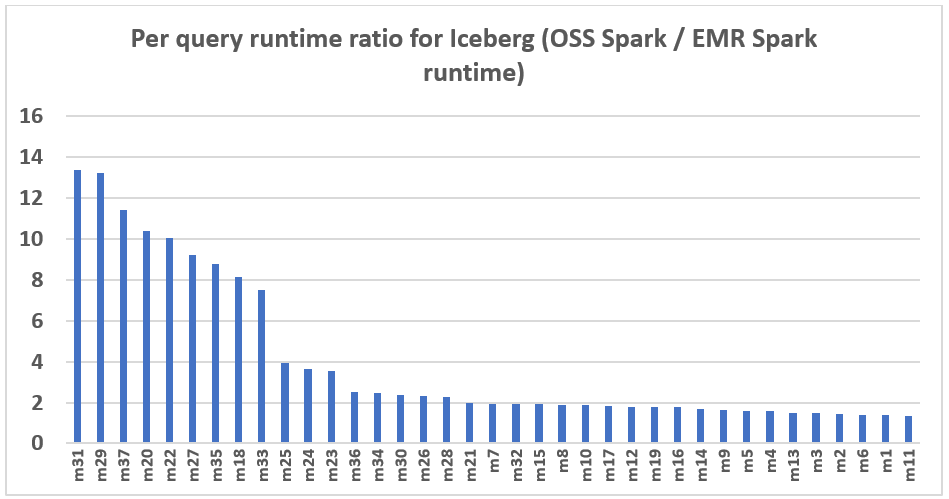
O gráfico a seguir demonstra a melhoria de desempenho por consulta do Amazon EMR 7.12 em relação ao Spark 3.5.6 de código aberto e ao Iceberg 1.10.0. A extensão da aceleração varia de uma consulta para outra, sendo a mais rápida até 13,3 vezes mais rápida para a consulta m31, com o Amazon EMR superando o Spark de código aberto com tabelas Iceberg. O eixo horizontal organiza as consultas de benchmark do TPC-DS 3TB em ordem decrescente com base na melhoria de desempenho observada com o Amazon EMR, e o eixo vertical representa a magnitude dessa aceleração como uma proporção.
Otimizações de desempenho no Amazon EMR
O Amazon EMR 7.12 alcança desempenho de gravação duas vezes mais rápido por meio de otimizações sistemáticas em todo o pipeline de execução de gravação. Essas melhorias abrangem diversas áreas:
- Operações de exclusão somente de metadados: ao excluir partições inteiras, o EMR agora pode otimizar essas operações para alterações somente de metadados, eliminando a necessidade de reescrever arquivos de dados. Isto reduz significativamente o tempo e o custo das operações de exclusão no nível da partição.
- Junções de filtro Bloom para operações de mesclagem: estratégias de junção aprimoradas usando filtros Bloom reduzem a quantidade de dados que precisam ser lidos e processados durante operações de mesclagem, beneficiando principalmente consultas com predicados seletivos.
- Gravação de arquivo paralelo: o paralelismo otimizado durante a fase de gravação das operações de mesclagem melhora a produtividade ao gravar os resultados filtrados de volta no Amazon S3, reduzindo o tempo geral da operação de mesclagem. Equilibramos o paralelismo com o desempenho de leitura para obter um desempenho geral otimizado em toda a carga de trabalho.
Essas otimizações funcionam juntas para oferecer melhorias consistentes de desempenho em diversos padrões de gravação. O resultado é uma ingestão de dados e execução de pipeline ETL significativamente mais rápidas, ao mesmo tempo que mantém as garantias ACID do Iceberg e a consistência dos dados do Iceberg.
Comparação de custos
Nosso benchmark fornece dados de tempo de execução whole e média geométrica para avaliar o desempenho do Spark e do Iceberg em um cenário complexo de suporte à decisão do mundo actual. Para obter informações adicionais, também examinamos o aspecto do custo. Calculamos estimativas de custos usando fórmulas que levam em conta instâncias sob demanda do EC2, Loja de blocos elásticos da Amazon (Amazon EBS) e despesas do Amazon EMR.
- Custo do Amazon EC2 (inclui custo de SSD) = número de instâncias * taxa horária r5d.4xlarge * tempo de execução do trabalho em horas
- Taxa horária 4xgrande = US$ 1,152 por hora
- Custo raiz do Amazon EBS = número de instâncias * Amazon EBS por taxa horária de GB * tamanho do quantity raiz EBS * tempo de execução do trabalho em horas
- Custo do Amazon EMR = número de instâncias * r5d.4xlarge Custo do Amazon EMR * tempo de execução do trabalho em horas
- Custo 4xlarge do Amazon EMR = US$ 0,27 por hora
- Custo whole = custo do Amazon EC2 + custo raiz do Amazon EBS + custo do Amazon EMR
Os cálculos revelam que o benchmark Amazon EMR 7.12 produz uma melhoria de eficiência de custos de 1,7x em relação ao Spark 3.5.6 de código aberto e ao Iceberg 1.10.0 na execução do trabalho de benchmark.
| Métrica | Amazon EMR 7.12 | Código aberto Spark 3.5.6 e Iceberg 1.10.0 |
| Tempo de execução em segundos | 443,58 | 926,63 |
| Número de instâncias EC2 (inclui nó primário) | 9 | 9 |
| Tamanho do Amazon EBS | 20 GB | 20 GB |
| Amazon EC2 (custo whole de tempo de execução) | US$ 1,28 | US$ 2,67 |
| Custo do Amazon EBS | US$ 0,00 | US$ 0,01 |
| Custo do Amazon EMR | US$ 0,30 | US$ 0 |
| Custo whole | US$ 1,58 | US$ 2,68 |
| Economia de custos | Amazon EMR 7.12 é 1,7 vezes melhor | Linha de base |
Execute benchmarks Spark de código aberto em tabelas Iceberg
Usamos clusters EC2 separados, cada um equipado com nove instâncias r5d.4xlarge, para testar o Spark 3.5.6 de código aberto e o Amazon EMR 7.12 para carga de trabalho Iceberg. O nó primário estava equipado com 16 vCPU e 128 GB de memória, e os oito nós de trabalho juntos tinham 128 vCPU e 1.024 GB de memória. Realizamos testes usando as configurações padrão do Amazon EMR para mostrar a experiência típica do usuário e ajustamos minimamente as configurações do Spark e do Iceberg para manter uma comparação equilibrada.
A tabela a seguir resume as configurações do Amazon EC2 para o nó primário e oito nós de trabalho do tipo r5d.4xlarge.
| Instância EC2 | vCPU | Memória (GiB) | Armazenamento de instância (GB) | Quantity raiz do EBS (GB) |
| r5d.4xgrande | 16 | 128 | 2 SSDs de 300 NVMe | 20GB |
Instruções de benchmarking
Siga as etapas abaixo para executar o benchmark:
- Para a execução de código aberto, crie um cluster Spark no Amazon EC2 usando Flintrock com a configuração descrita anteriormente.
- Configure os dados de origem TPC-DS com Iceberg em seu bucket S3.
- Crie o jar do aplicativo de benchmark a partir da origem para executar o benchmarking e obter os resultados.
Instruções detalhadas são fornecidas no Repositório GitHub emr-spark-benchmark.
Resuma os resultados
Após a conclusão do trabalho do Spark, recupere o arquivo de resultado do teste do bucket S3 de saída em s3://. Isso pode ser feito por meio do console do Amazon S3 navegando até o native do bucket especificado ou usando o comando Interface de linha de comando da Amazone (AWS CLI). O aplicativo de benchmark Spark organiza os dados criando uma pasta de carimbo de information/hora e colocando um arquivo de resumo em uma pasta chamada abstract.csv. Os arquivos CSV de saída contêm quatro colunas sem cabeçalhos:
- Nome da consulta
- Tempo médio
- Tempo mínimo
- Tempo máximo
Com os dados de três execuções de teste separadas com uma iteração de cada vez, podemos calcular a média e a média geométrica dos tempos de execução do benchmark.
Limpar
Para ajudar a evitar cobranças futuras, exclua os recursos criados seguindo as instruções fornecidas no Seção de limpeza do repositório GitHub.
Resumo
O Amazon EMR aprimora consistentemente o tempo de execução do EMR para Spark quando usado com tabelas Iceberg, alcançando um desempenho de gravação duas vezes mais rápido que o Spark 3.5.6 de código aberto e o Iceberg 1.10.0 com EMR 7.12 em cargas de trabalho de mesclagem de 3 TB. Isso representa uma melhoria significativa para a ingestão de dados e pipelines de ETL, ajudando a proporcionar uma redução de custos de 1,7x, ao mesmo tempo que mantém as garantias ACID do Iceberg. Incentivamos você a se manter atualizado com as versões mais recentes do Amazon EMR para aproveitar ao máximo as melhorias contínuas de desempenho.
Para se manter informado, inscreva-se no Feed RSS do weblog de Huge Information da AWSonde você pode encontrar atualizações sobre o tempo de execução do EMR para Spark e Iceberg, bem como dicas sobre práticas recomendadas de configuração e recomendações de ajuste.
Sobre os autores
 Atul Félix Payapilly é engenheiro de desenvolvimento de software program do Amazon EMR na Amazon Internet Providers.
Atul Félix Payapilly é engenheiro de desenvolvimento de software program do Amazon EMR na Amazon Internet Providers.
 Akshaya KP é engenheiro de desenvolvimento de software program do Amazon EMR na Amazon Internet Providers.
Akshaya KP é engenheiro de desenvolvimento de software program do Amazon EMR na Amazon Internet Providers.
 Hari Kishore Chaparala é engenheiro de desenvolvimento de software program do Amazon EMR na Amazon Internet Providers.
Hari Kishore Chaparala é engenheiro de desenvolvimento de software program do Amazon EMR na Amazon Internet Providers.
 Giovanni Matteo é gerente sênior do grupo Amazon EMR Spark e Iceberg.
Giovanni Matteo é gerente sênior do grupo Amazon EMR Spark e Iceberg.