Já se perguntou o quão poucos LLMs ou algumas ferramentas processam e entendem seus PDFs que consistem em várias tabelas e imagens? Eles provavelmente usam um OCR tradicional ou um VLM (modelo de linguagem de visão) sob o capô. Embora valha a pena notar que o OCR tradicional sofre em reconhecer o texto manuscrito em imagens. Ele ainda tem problemas com fontes ou personagens incomuns, como fórmulas complexas em trabalhos de pesquisa. Os VLMs fazem um bom trabalho nesse sentido, mas podem ter dificuldade em entender a ordem dos dados tabulares. Eles também podem deixar de capturar relacionamentos espaciais, como imagens, juntamente com suas legendas.
Então, qual é a solução aqui? Aqui, exploramos um modelo recente focado em enfrentar todos esses problemas. O modelo Smoldocling que está disponível publicamente para abraçar o rosto. Então, sem mais delongas, vamos mergulhar.
Fundo
O Smoldocling é um modelo minúsculo, mas poderoso, 256m, projetado para compreensão do documento. Ao contrário dos modelos de peso pesado, ele não precisa de exhibits e exhibits de VRAM para executar. Consiste em um codificador de visão e um decodificador compacto treinado para produzir médicos, uma linguagem no estilo XML que codifica structure, estrutura e conteúdo. Seus autores o treinaram em milhões de documentos sintéticos com fórmulas, tabelas e trechos de código. Também vale a pena notar que esse modelo é construído em cima do smolvlm-256m do Hugging Face. Nas próximas seções, vamos mergulhar um nível mais profundo e olhar para sua arquitetura e demonstração.
Arquitetura de modelo

Tecnicamente, o Smoldocling também é um VLM, mas possui uma arquitetura única. O Smoldocling pega uma imagem de documento de página inteira e a codifica usando um codificador de visão, produzindo incorporações visuais densas. Estes são projetados e agrupados em um número fixo de tokens para ajustar o tamanho de entrada de um pequeno decodificador. Paralelamente, um immediate de usuário é incorporado e concatenado com os recursos visuais. Esta sequência combinada então produz um fluxo de estruturado
Demoção Smoldocling
Pré -requisito
Certifique -se de criar sua conta de rosto abraçada e manter seus tokens de acesso à mão, pois vamos fazer isso usando Abraçando o rosto.
Você pode Obtenha seus tokens de acesso aqui.
NOTA: Certifique -se de fornecer as permissões necessárias, como acesso a repositórios públicos e permita que ele faça chamadas de inferência.
Vamos usar um pipeline para carregar o modelo (alternativamente, você também pode optar por carregar o modelo diretamente, que será explorado imediatamente após este).
Nota: Este modelo, como mencionado anteriormente, processa uma imagem de um documento de uma só vez. Você pode optar por fazer uso deste pipeline para usar o modelo várias vezes de uma só vez para processar todo o documento.
Eu estarei usando o Google Colab (leia nosso Guia completo no Google Colab aqui) aqui. Certifique -se de alterar o tempo de execução para a GPU:
from transformers import pipeline
pipe = pipeline("image-text-to-text", mannequin="ds4sd/SmolDocling-256M-preview")
messages = (
{
"position": "person",
"content material": (
{"kind": "picture", "url": "https://cdn.analyticsvidhya.com/wp-content/uploads/2024/05/Intro-1.jpg"},
{"kind": "textual content", "textual content": "Which yr was this convention held?"}
)
},
)
pipe(textual content=messages)Eu forneci esta imagem de uma cúpula de hack de dados anterior e perguntei: “Em que ano foi realizada esta conferência?”

Resposta Smoldocling
{'kind': 'textual content', 'textual content': 'Which yr was this convention held?'})},
{'position': 'assistant', 'content material': ' This convention was held in 2023.'})})
Is that this appropriate? When you zoom in and look carefully, you will see that that it's certainly DHS 2023. This 256M parameter, with the assistance of the visible encoder, appears to be doing nicely. To see its full potential, you may go a whole doc with advanced photos and tables as an train.Agora vamos tentar usar outro método para acessar o modelo, carregando -o diretamente usando o módulo Transformers:
Aqui, passaremos um trecho de imagem no artigo de pesquisa Smoldocling e obteremos as médicos como saída do modelo.
A imagem que passaremos para o modelo:
Instale o módulo do núcleo de ancoragem primeiro antes de prosseguir:
! pip set up docling_core
Carregando o modelo e fornecendo o immediate:
from transformers import AutoProcessor, AutoModelForImageTextToText
from transformers.image_utils import load_image
picture = load_image("/content material/docling_screenshot.png")
processor = AutoProcessor.from_pretrained("ds4sd/SmolDocling-256M-preview")
mannequin = AutoModelForImageTextToText.from_pretrained("ds4sd/SmolDocling-256M-preview")
messages = (
{
"position": "person",
"content material": (
{"kind": "picture"},
{"kind": "textual content", "textual content": "Convert this web page to docling."}
)
}
)
immediate = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(textual content=immediate, photos=(picture), return_tensors="pt")
generated_ids = mannequin.generate(**inputs, max_new_tokens=8192)
prompt_length = inputs.input_ids.form(1)
trimmed_generated_ids = generated_ids(:, prompt_length:)
doctags = processor.batch_decode(
trimmed_generated_ids,
skip_special_tokens=False,
)(0).lstrip()
print("DocTags output:n", doctags)Exibindo os resultados:
from docling_core.varieties.doc.doc import DocTagsDocument
from docling_core.varieties.doc import DoclingDocument
doctags_doc = DocTagsDocument.from_doctags_and_image_pairs((doctags), (picture))
doc = DoclingDocument.load_from_doctags(doctags_doc, document_name="MyDoc")
md = doc.export_to_markdown()
print(md)Saída Smoldocling:
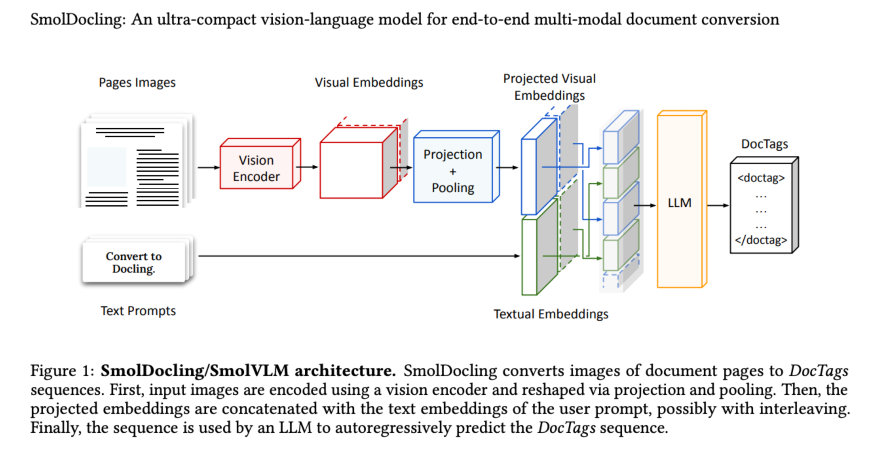
Figura 1: Arquitetura Smoldocling/Smolvlm. Smoldocling converte imagens de páginas de documentos em sequências de Doctags. Primeiro, as imagens de entrada são codificadas usando um codificador de visão e remodeladas por projeção e pool. Em seguida, as incorporações projetadas são concatenadas com as incorporações de texto do immediate do usuário, possivelmente com a intercalação. Finalmente, a sequência é usada por um LLM para prever automaticamente a sequência Doctags.
Ótimo ver Smoldocling falando sobre Smoldocling. O texto também parece preciso. É interessante pensar nos usos potenciais desse modelo. Vamos ver alguns exemplos do mesmo.
Casos de uso potenciais de Smoldocling
Como modelo de linguagem de visão, o Smoldocling tem amplo uso potencial, como extrair dados de documentos estruturados, por exemplo, documentos de pesquisa, relatórios financeiros e contratos legais.
Pode até ser usado para fins acadêmicos, como digitalizar notas manuscritas e digitalizar cópias de resposta. Pode -se também criar pipelines com smoldocling como componente em aplicativos que requerem OCR ou processamento de documentos.
Conclusão
Para resumir, Smoldocling é um modelo minúsculo, mas útil, 256m, projetado para entender o documento. O OCR tradicional luta com texto manuscrito e fontes incomuns, enquanto os VLMs geralmente perdem o contexto espacial ou tabular. Este modelo compacto faz um bom trabalho e possui vários casos de uso em que pode ser usado. Se você ainda não experimentou o modelo, experimente e informe -me se enfrentar algum problema no processo.
Perguntas frequentes
As médicos são tags especiais que descrevem o structure e o conteúdo de um documento. Eles ajudam o modelo a acompanhar coisas como tabelas, títulos e imagens.
O agrupamento é uma camada em redes neurais que reduz o tamanho da imagem de entrada. Ajuda com um processamento mais rápido de dados e treinamento mais rápido do modelo.
OCR (reconhecimento de caracteres óptico) é uma tecnologia que transforma imagens ou documentos digitalizados em texto editável. É comumente usado para digitalizar papéis, livros ou formulários impressos.
Apaixonado por tecnologia e inovação, formado pelo Instituto de Tecnologia da Vellore. Atualmente trabalhando como trainee de ciência de dados, com foco na ciência de dados. Profundamente interessado em aprendizado profundo e IA generativa, ansiosa para explorar técnicas de ponta para resolver problemas complexos e criar soluções impactantes.
Faça login para continuar lendo e desfrutar de conteúdo com curado especialista.